Observação
Este comando está disponível com o Módulo de análise preditiva. Clique aqui saber mais sobre como ativar o módulo.
Procure o melhor tipo de modelo
Uma equipe de pesquisadores coleta e publica informações detalhadas sobre fatores que afetam doenças cardíacas. As variáveis incluem idade, sexo, níveis de colesterol, frequência cardíaca máxima e muito mais. Este exemplo é baseado em um conjunto de dados públicos que fornece informações detalhadas sobre doenças cardíacas. Os dados originais são de archive.ics.uci.edu.
Os pesquisadores querem encontrar um modelo que faça as previsões mais precisas possíveis. Os pesquisadores usam Descobrir o melhor modelo (Resposta binária) para comparar o desempenho preditivo de 4 tipos de modelos: regressão logística binária, TreeNet®, Random Forests® e CART®. Os pesquisadores planejam explorar ainda mais o tipo de modelo com o melhor desempenho preditivo.
- Abra os dados amostrais, BinarioCardiopatiaMelhorModelo.MWX.
- Selecione .
- Em Resposta, insira 'Doença cardíaca'.
- Em Preditores contínuos, digite Idade, 'Pressão Arterial de descanso', Colesterol, 'Max Heart Rate', e ' Pico Antigo'.
- Em Preditores categóricos, digite Sexo, ' Tipo de dor torácica', 'Açúcar no sangue em jejum', 'Resto ECG', 'Exercício Angina', Inclinação, 'Principais Navios' e Thal.
- Clique em OK.
Interpretar os resultados
A tabela Seleção de Modelos compara o desempenho dos diferentes tipos de modelos. O modelo de Random Forests® tem o valor mínimo da probabilidade média de loglikelihood. Os resultados a seguir são para o melhor modelo de Random Forests®.
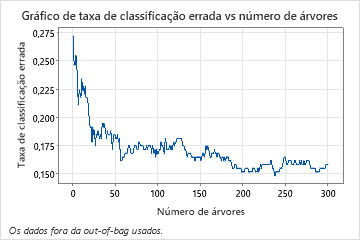
A taxa de classificação errada vs número de árvores mostra toda a curva sobre o número de árvores cultivadas. A taxa de classificação incorreta é de aproximadamente 0,16.
A tabela de sumário do modelo mostra que o log-verossimilhança negativo médio é de 0,39.
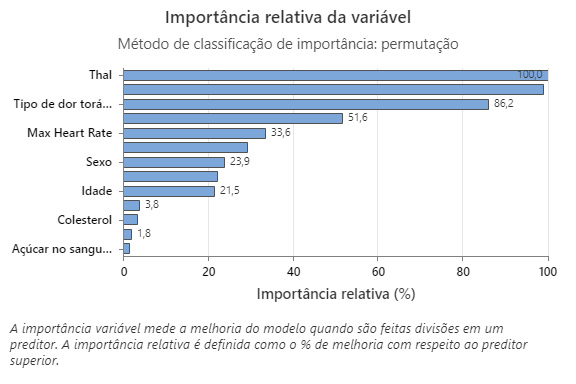
O gráfico de importância relativa da variável representa os preditores por ordem de seu efeito sobre a melhoria do modelo quando as divisões são feitas em um preditor sobre a sequência de árvores. A variável preditora mais importante é o Thal. Se a contribuição da variável preditora superior, Thal, for de 100%, então a próxima variável importante, Vasos principais, tem uma contribuição de 98,9%. Isso significa que os Vasos principais são 98,9% tão importantes quanto Thal neste modelo de classificação.
A matriz confusão mostra se o modelo separa as classes bem e corretamente. Neste exemplo, a probabilidade de um evento ser predito corretamente é de 87%. A probabilidade de que um não evento ser predito corretamente é de 81%.
A taxa de classificação errada ajuda a indicar se o modelo irá predizer novas observações com exatidão. Para predição de eventos, o erro de classificação errada do teste é de 13%. Para predição de eventos, o erro de classificação errada do é de 19%. No geral, o erro de classificação errada para os dados do teste é de aproximadamente 16%.
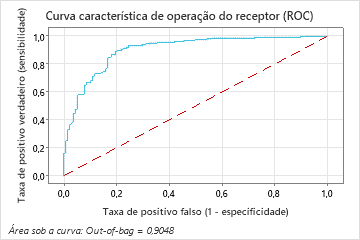
A área sob a curva ROC para o modelo Random Forests® é aproximadamente 0,90 para os dados fora do saco.
Método
| Ajuste um modelo de regressão logística stepwise com termos lineares e termos de ordem 2. |
|---|
| Ajuste 6 modelos de classificação TreeNet®. |
| Ajuste 3 modelos de classificação Random Forests® com tamanho amostral de bootstrap igual ao tamanho de dados de treinamento de 303. |
| Ajuste um modelo ótimo de classificação CART®. |
| Selecione o modelo com logverossimilhança máxima da avaliação cruzada com 5-dobras. |
| Número total de linhas: 303 |
| Linhas usadas para o modelo de regressão logística: 303 |
| Linhas usadas para modelos baseados em árvores: 303 |
Informações de resposta binária
| Variável | Classe | Contagem | % |
|---|---|---|---|
| Doença cardíaca | 1 (Evento) | 165 | 54,46 |
| 0 | 138 | 45,54 | |
| Todos | 303 | 100,00 |
| Melhor modelo dentro do tipo | -Log da Verossimilhança Média | Área sob a curva ROC | Taxa de classificação errada |
|---|---|---|---|
| Random Forests®* | 0,3904 | 0,9048 | 0,1584 |
| TreeNet® | 0,3907 | 0,9032 | 0,1520 |
| Regressão logística | 0,4671 | 0,9142 | 0,1518 |
| CART® | 1,8072 | 0,7991 | 0,2080 |
Hiperparâmetros para melhor modelo Random Forests®
| Número de amostras bootstrap | 300 |
|---|---|
| Tamanho amostral | O mesmo que o tamanho dos dados de treinamento de 303 |
| Número de preditores selecionados para divisão de nós | Raiz quadrada do número total de preditores = 3 |
| Tamanho mínimo do nó interno | 8 |
Sumário do modelo
| Preditores totais | 13 |
|---|---|
| Preditores importantes | 13 |
| Estatísticas | Out-of-Bag |
|---|---|
| -Log da Verossimilhança Média | 0,3904 |
| Área sob a curva ROC | 0,9048 |
| IC de 95% | (0,8706; 0,9389) |
| Elevação | 1,7758 |
| Taxa de classificação errada | 0,1584 |
Matriz de confusão
| Classe predita (Out-of-Bag) | ||||
|---|---|---|---|---|
| Classe real | Contagem | 1 | 0 | % Correto |
| 1 (Evento) | 165 | 143 | 22 | 86,67 |
| 0 | 138 | 26 | 112 | 81,16 |
| Todos | 303 | 169 | 134 | 84,16 |
| Estatísticas | Out-of-Bag (%) |
|---|---|
| Taxa de positivo verdadeiro (sensibil. ou poder) | 86,67 |
| Taxa de positivo falso (erro tipo I) | 18,84 |
| Taxa de negativo falso (erro tipo II) | 13,33 |
| Taxa de negativo verdadeiro (especificidade) | 81,16 |
Classificação errada
| Out-of-Bag | |||
|---|---|---|---|
| Contagem | Classificado errado | % de erro | |
| Classe real | |||
| 1 (Evento) | 165 | 22 | 13,33 |
| 0 | 138 | 26 | 18,84 |
| Todos | 303 | 48 | 15,84 |
Selecione um modelo alternativo
Os pesquisadores podem analisar os resultados de outros modelos a partir da busca pelo melhor modelo. Para um modelo TreeNet®, você pode selecionar a partir de um modelo que fez parte da pesquisa ou especificar hiperparmetros para um modelo diferente.
- Selecione Selecione o modelo alternativo.
- Em Tipo de modelo, selecione TreeNet®.
- Em Selecione um modelo existente, escolha o terceiro modelo, que tem o melhor valor da média mínima –log-verossimilhança.
- Clique em Exibir resultados.
Interpretar os resultados
Para esta análise, o Minitab cultiva 300 árvores e o número ótimo de árvores é de 46. O modelo usa uma taxa de aprendizagem de 0,1 e uma fração subsample de 0,5. número máximo de nós terminais por árvore O número máximo de nós terminais por árvore é 6.
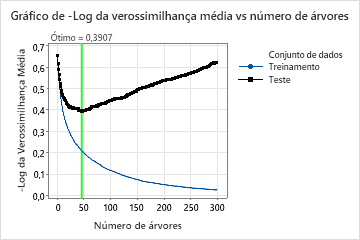
O gráfico de log-verossimilhança médio vs número de árvores mostra toda a curva sobre o número de árvores cultivadas. O valor ótimo para os dados do teste é 0,3907 quando o número de árvores é 46.
Sumário do modelo
| Preditores totais | 13 |
|---|---|
| Preditores importantes | 13 |
| Número de árvores cultivadas | 300 |
| Número ótimo de árvores | 46 |
| Estatísticas | Treinamento | Teste |
|---|---|---|
| -Log da Verossimilhança Média | 0,2088 | 0,3907 |
| Área sob a curva ROC | 0,9842 | 0,9032 |
| IC de 95% | (0,9721; 0,9964) | (0,8683; 0,9381) |
| Elevação | 1,8364 | 1,7744 |
| Taxa de classificação errada | 0,0726 | 0,1520 |
Quando o número de árvores é de 46, a tabela de resumo do modelo indica que a probabilidade média negativa de loglikelihood é aproximadamente 0,21 para os dados de treinamento e aproximadamente 0,39 para os dados do teste.
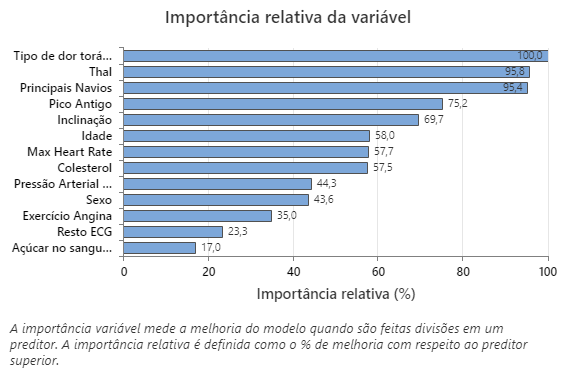
O gráfico de importância relativa da variável representa os preditores por ordem de seu efeito sobre a melhoria do modelo quando as divisões são feitas em um preditor sobre a sequência de árvores. A variável preditora mais importante é o Tipo de dor torácica. Se a contribuição da variável preditora superior, Tipo de dor torácica, for 100%, a próxima variável importante, Thal, terá uma contribuição de 95,8%. Isso significa que o Thal é 95,8% tão importante quanto o tipo de dor torácica neste modelo de classificação.
Matriz de confusão
| Classe predita (Treinamento) | |||||||
|---|---|---|---|---|---|---|---|
| Classe predita (Teste) | |||||||
| Classe real | Contagem | 1 | 0 | % Correto | 1 | 0 | % Correto |
| 1 (Evento) | 165 | 156 | 9 | 94,55 | 147 | 18 | 89,09 |
| 0 | 138 | 13 | 125 | 90,58 | 28 | 110 | 79,71 |
| Todos | 303 | 169 | 134 | 92,74 | 175 | 128 | 84,82 |
| Estatísticas | Treinamento (%) | Teste (%) |
|---|---|---|
| Taxa de positivo verdadeiro (sensibil. ou poder) | 94,55 | 89,09 |
| Taxa de positivo falso (erro tipo I) | 9,42 | 20,29 |
| Taxa de negativo falso (erro tipo II) | 5,45 | 10,91 |
| Taxa de negativo verdadeiro (especificidade) | 90,58 | 79,71 |
A matriz confusão mostra se o modelo separa as classes bem e corretamente. Neste exemplo, a probabilidade de um evento ser predito corretamente é de 89%. A probabilidade de que um não evento ser predito corretamente é de 80%.
Classificação errada
| Treinamento | Teste | ||||
|---|---|---|---|---|---|
| Classificado errado | % de erro | Classificado errado | % de erro | ||
| Classe real | Contagem | ||||
| 1 (Evento) | 165 | 9 | 5,45 | 18 | 10,91 |
| 0 | 138 | 13 | 9,42 | 28 | 20,29 |
| Todos | 303 | 22 | 7,26 | 46 | 15,18 |
A taxa de classificação errada ajuda a indicar se o modelo irá predizer novas observações com exatidão. Para a previsão de eventos, o erro de classificação errada do teste é de aproximadamente 11%. Para predição de eventos, o erro de classificação errada do é de 20%. No geral, o erro de classificação errada para os dados do teste é de aproximadamente 15%.
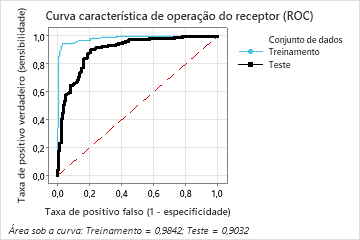
A área sob a curva ROC quando o número de árvores é 46 é aproximadamente 0,98 para os dados de treinamento e é aproximadamente 0,90 para os dados de teste.
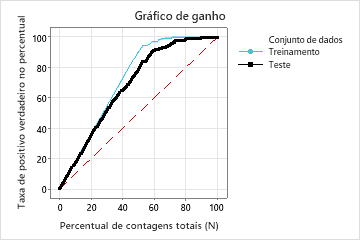
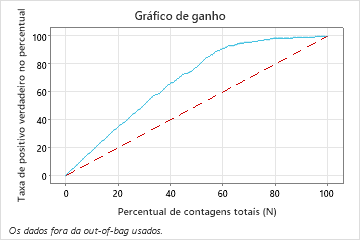
Neste exemplo, o gráfico de ganho mostra um aumento acentuado acima da linha de referência, em seguida, um achatamento. Neste caso, aproximadamente 60% dos dados representam aproximadamente 90% dos positivos verdadeiros. Essa diferença é o ganho extra com o uso do modelo.
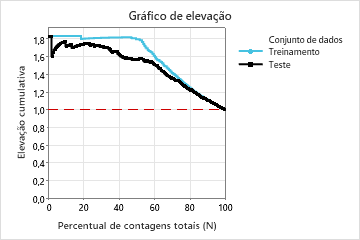
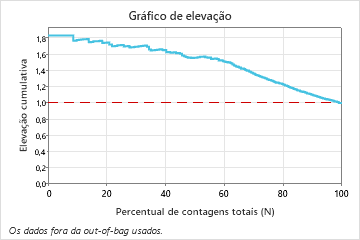
Neste exemplo, o gráfico de elevação mostra um grande aumento acima da linha de referência que começa a diminuir mais rapidamente após aproximadamente 50% da contagem total.
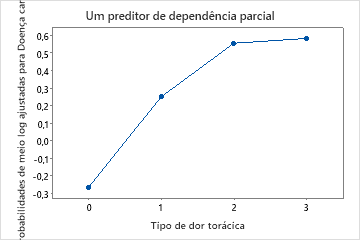
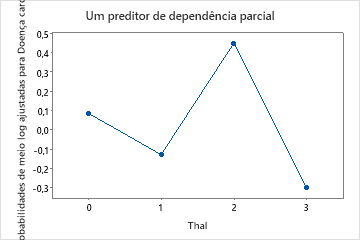
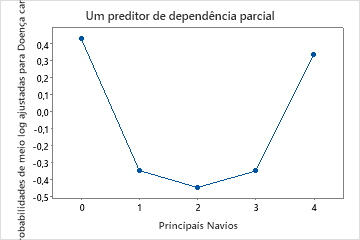
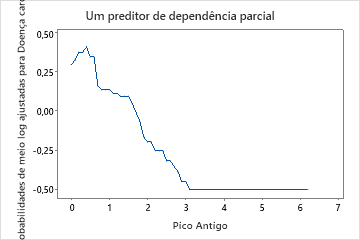
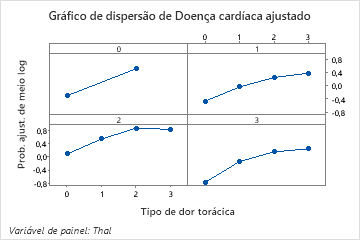
Use os gráficos de dependência parcial para obter uma visão de como as variáveis importantes ou pares de variáveis afetam a resposta predita. Os valores de resposta na escala de meio log são as predições oriundas do modelo. Os gráficos de dependência parcial mostram se a relação entre a resposta e uma variável é linear, monotônica ou mais complexa.
Por exemplo, no gráfico de dependência parcial do tipo de dor no peito, as chances de 1/2 log são mais altas no valor de 3. Selecione ou para produzir gráficos para outras variáveis