Um prestador de serviços de saúde opera uma instalação que presta serviços de tratamento de abuso de substâncias. Um dos serviços na instalação é um programa ambulatorial de desintoxicação em que um curso regular de tratamento pode durar de 1 a 30 dias. Uma equipe responsável pelo planejamento de pessoal e suprimentos quer saber se eles podem fazer melhores predições sobre o tempo que um paciente usa os serviços com base em informações que podem coletar sobre o paciente quando este entra para o programa. Essas variáveis incluem informações demográficas e variáveis sobre o abuso de substâncias pelo paciente.
Primeiro, a equipe considera uma análise de regressão tradicional no Minitab. Devido ao padrão de valor faltante em seus dados, a análise omite mais de 70% dos dados. A omissão de um percentual tão grande de dados implica que muitas informações estão perdidas. Os resultados da análise dos casos sem dados faltantes podem ser muito diferentes dos resultados usando todo o conjunto de dados. Como Regressão CART® lida automaticamente com valores faltantes em variáveis preditoras, a equipe decide usar Regressão CART® para avaliar melhor seus dados.
- Abra o conjunto de dados de amostra TempoDeServico.MWX.
- Selecione .
- Em Resposta, digite 'Duração do Serviço'.
- Em Preditores contínuos, insira 'Idade no Ingresso'-'Anos de Educação'.
- Em Preditores categóricos, insira 'Outro uso estimulante'-'Diagnóstico de DSM'.
- Clique em Validação.
- Em Método de validação, selecione Validação cruzada de K dobras.
- Selecione Atribuir linhas de cada duplicação por coluna de ID.
- Em Coluna de IDs, digite Dobrar.
- Clique em OK em cada caixa de diálogo.
Interprete os resultados
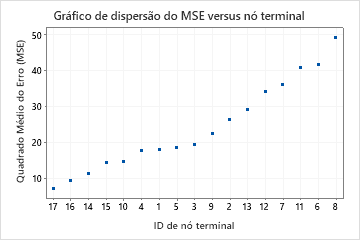
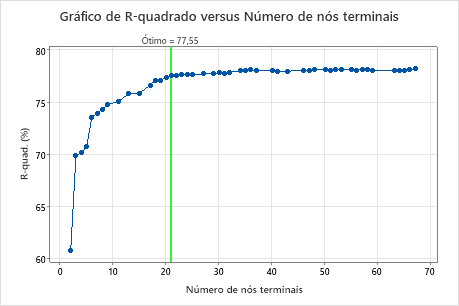
Por padrão, o Minitab exibe a menor árvore com um valor de R2 que está dentro de 1 erro padrão da árvore com o valor máximo de R2. Como a equipe de saúde usa a validação de K duplicações, o critério é o valor de R2 máximo de K duplicações. Esta árvore tem 21 nós terminais.
Selecione uma árvore alternativa
- Na saída, clique em Selecionar uma árvore alternativa
- No gráfico, selecione a árvore de 17 nós.
- Clique em Criar árvore.
Interprete os resultados
Os pesquisadores analisam o gráfico da estatística de R2 a da validação cruzada e o número de nós terminais. Como a árvore com 17 nós tem uma estatística de R2 próxima dos maiores valores do gráfico, os resultados para o resto da saída são para a árvore com 17 nós.
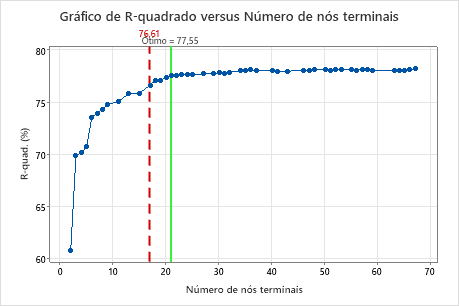
Os pesquisadores analisam primeiro o resumo do modelo para avaliar o desempenho da árvore menor. Os valores para a estatística de treinamento e de teste estão próximos uns dos outros, de modo que a árvore não parece superajustada. A estatística R2 é quase tão alta quanto a árvore de 21 nós, de modo que os pesquisadores decidem usar a árvore com 17 nós para explorar as relações entre as variáveis preditoras e os valores de resposta.
Método
| Divisão de nós | Erro mínimo quadrado |
|---|---|
| Árvore ótima | Dentro de 2,5 erros padrão de R-quadrado máximo |
| Validação do modelo | Validação cruzada com linhas definidas por Dobrar |
| Linhas usadas | 4453 |
Informações da Resposta
| Média | DesvPad | Mínimo | Q1 | Mediana | Q3 | Máximo |
|---|---|---|---|---|---|---|
| 17,5960 | 9,29097 | 1 | 10 | 18 | 26 | 30 |
Sumário do modelo
| Preditores totais | 44 |
|---|---|
| Preditores importantes | 33 |
| Número de nós terminais | 17 |
| Tamanho mínimo do nó terminal | 49 |
| Estatísticas | Treinamento | Teste |
|---|---|---|
| R-quadrado | 77,99% | 76,61% |
| Raiz do quadrado médio do Erro (RMSE) | 4,3585 | 4,4932 |
| Quadrado médio do erro (MSE) | 18,9967 | 20,1887 |
| Desvio absoluto médio (DAM) | 3,4070 | 3,5226 |
| Erro percentual absoluto médio (MAPE) | 0,6535 | 0,6674 |
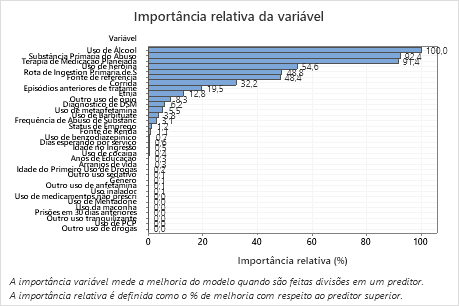
- 'Substância Primária do Abuso' e 'Terapia de Medicação Planejada' são cerca de 92% tão importantes quanto 'Uso de Álcool'.
- 'Uso de heroína' é cerca de 55% tão importante quanto 'Uso de Álcool'.
- 'Rota de Ingestion Primária de Sub' e 'Fonte de referência' são cerca de 48% tão importantes quanto 'Uso de Álcool'.
Embora esses resultados incluam 33 variáveis com importância positiva, os rankings relativos fornecem informações sobre quantas variáveis devem ser controladas ou monitoradas para uma determinada aplicação. Quedas íngremes nos valores de importância relativa de uma variável para a próxima variável podem orientar as decisões sobre quais variáveis devem ser controladas ou monitoradas. Por exemplo, nesses dados, as três variáveis mais importantes têm valores de importância relativamente próximos antes de uma queda de quase 40% na importância relativa para a próxima variável. Da mesma forma, três variáveis têm valores de importância semelhantes próximos a 50%. Você pode remover variáveis de diferentes grupos e refazer a análise para avaliar como as variáveis em vários grupos afetam os valores de exatidão da predição na tabela Sumário do modelo.
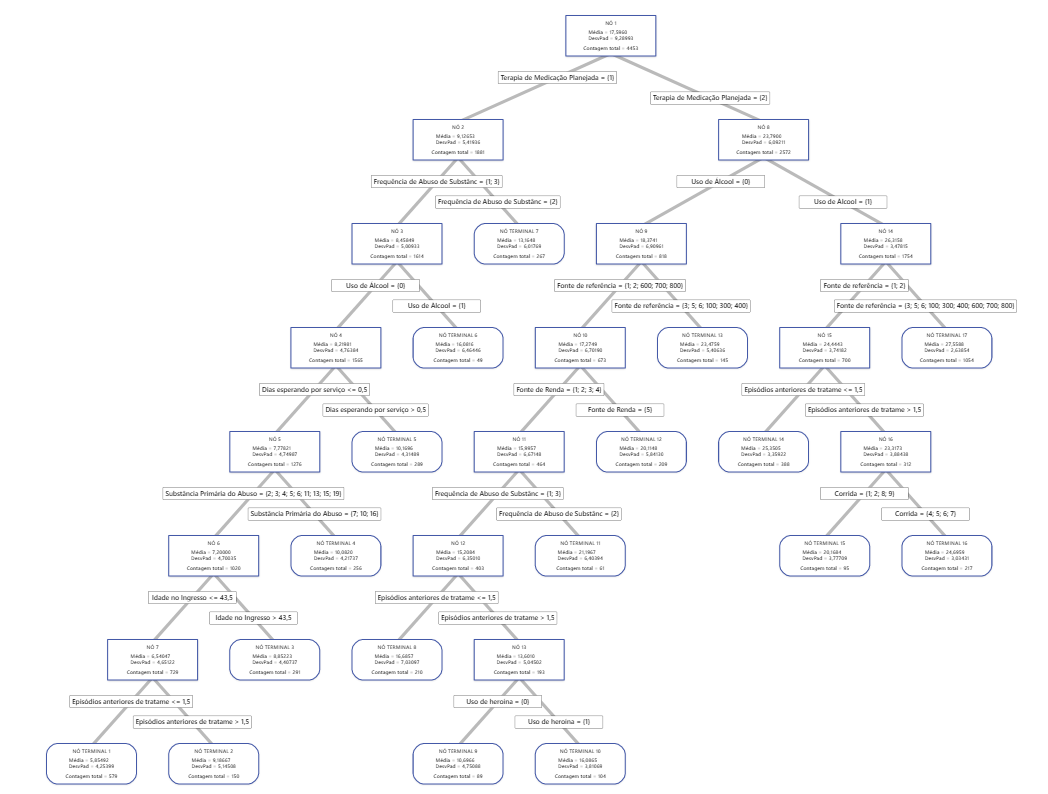
Para uma análise com validação cruzada de K duplicações, o diagrama de árvore mostra todos os 4453 casos do conjunto de dados completo. Você pode alternar as visualizações da árvore entre a vista detalhada e dividida do nó. A tabela de estatísticas de ajustes e de erros e os critérios para classificação de sujeitos oferecem informações adicionais sobre os nós terminais.
- O nó 2 inclui os casos em que 'Terapia de Medicação Planejada' = 1. Este nó tem 1881 casos. A média para o nó é menor do que a média geral. O desvio padrão para o Nó 2 é de cerca de 5,4, o que é menor do que o desvio padrão geral porque uma divisão produz mais nós puros.
- O nó 8 inclui os casos em que 'Terapia de Medicação Planejada' = 2. Esse nó tem 2572 casos. A média para o nó é mais do que a média geral. O desvio padrão para o Nó 8 é de cerca de 6,1, o que também é menor do que o desvio padrão geral.
Em seguida, o Nó 2 divide por 'Frequência de Abuso de Substâncias' e o Nó 8 divide por 'Uso de Álcool'. O Nó Terminal 17 tem os casos para 'Terapia de Medicação Planejada' = 2, 'Uso de Álcool' = 1, e 'Fonte de referência' = 3, 5, 6, 100, 300, 400, 600, 700 ou 800. Os pesquisadores observam que o Nó Terminal 17 tem a média mais alta, o menor desvio padrão e a maioria dos casos.
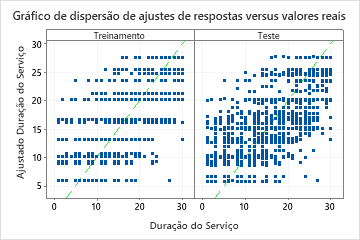
Os resultados incluem um gráfico de dispersão dos valores de resposta ajustados e os valores de resposta reais. Os pontos para o conjunto de dados de treinamento e o conjunto de dados de teste mostram padrões semelhantes. Essa semelhança sugere que o desempenho da árvore em novos dados está próximo do desempenho da árvore nos dados de treinamento.
- 'Terapia de Medicação Planejada' = {2}
- 'Uso de Álcool' = {0}
- 'Fonte de referência' = {1, 2, 600, 700, 800}
- 'Fonte de Renda' = {1, 2, 3, 4}
- 'Frequência de Abuso de Substâncias' = {1, 3}
- 'Episódios anteriores de tratamento' <= 1,5
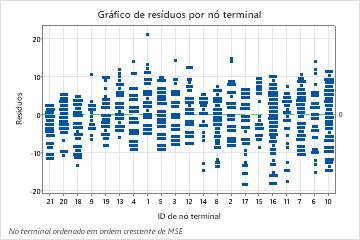
O gráfico de resíduos por nó terminal mostra que o ajuste é muito grande para um agrupamento pequeno de pacientes no Nó Terminal 8. Os analistas consideram investigar por que alguns desses pacientes usam os serviços por menos tempo do que um paciente típico em seu grupo. Por exemplo, se esses pacientes estiverem em uma localização geográfica diferente dos outros pacientes do nó terminal, os diferentes regulamentos governamentais e de seguros podem afetar o tempo que eles usam os serviços.
O gráfico de resíduos por nó terminal mostra outros casos em que os analistas podem optar por investigar agrupamentos ou outliers. Por exemplo, nesses dados, há um resíduo que parece muito maior do que os outros no Nó Terminal 1 e no Nó Terminal 7. Os analistas decidem investigar a razão pela qual esses pacientes usaram os serviços por mais tempo do que outros pacientes em seu nó terminal.
Como o valor do teste R2 deixa espaço para melhorias e os gráficos de resíduos mostram casos em que a árvore não ajusta bem, os pesquisadores consideram se devem usar um Regressão TreeNet® ou um Regressão Random Forests® para tentar melhorar o ajuste da árvore.