Preditores importantes
Qualquer árvore de classificação é uma coleção de divisões. Cada divisão proporciona melhorias à árvore. Cada divisão também inclui divisões de substitutos que também proporcionam melhorias na árvore. A importância de uma variável é dada por todas as suas melhorias quando a árvore usa a variável para dividir um nó ou como substituto para dividir um nó quando outra variável tem um valor faltante.
A fórmula a seguir fornece a melhoria em um único nó:
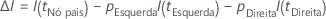
Os valores de I(t),pEsquerda, e pDireita dependem do critério para dividir os nós. Para obter mais informações, acesse Métodos de divisão de nós em Classificação CART®.

Média − Log-verossimilhança
Dados de treinamento ou sem validação
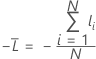
em que
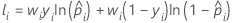
Notação para dados de treinamento ou sem validação
| Termo | Descrição |
|---|---|
| N | tamanho amostral dos dados completos ou dos dados de treinamento |
| wi | peso para a ia observação no conjunto de dados completo ou de treinamento |
| yi | variável indicadora que é 1 para o evento e 0 em outros casos para o conjunto completo ou de dados de treinamento |
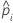 | probabilidade predita do evento para a ia linha no conjunto de dados completo ou de treinamento |
Validação cruzada de K dobras
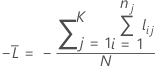
em que

Notação para validação cruzada de K dobras
| Termo | Descrição |
|---|---|
| N | tamanho amostral dos dados completos ou de treinamento |
| nj | tamanho amostral da dobra j |
| wij | peso para a ia observação na dobra j |
| yij | variável indicadora que é 1 para evento e 0 em outros casos para os dados na dobra j |
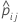 | probabilidade predita do evento a partir da estimativa do modelo que não inclui as observações para a ia observação na dobra j |
Conjunto de dados de teste
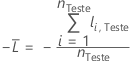
em que
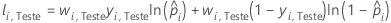
Notação para o conjunto de dados de teste
| Termo | Descrição |
|---|---|
| nteste | tamanho amostral do conjunto de teste |
| wi, teste | peso para a ia observação no conjunto de dados de teste |
| yi, teste | variável indicadora que é 1 para evento e 0 em outros casos para os dados no conjunto de teste |
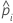 | probabilidade predita do evento para a ia linha no conjunto de teste |
Área sob a curva ROC
Fórmula


Para a área sob a curva, o Minitab utiliza uma integração.

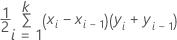
em que k é o número de nós terminais e (x0, y0) é o ponto (0, 0).
| x (taxa de falsos positivos) | y (taxa de positivos verdadeiros) |
|---|---|
| 0,0923 | 0,3051 |
| 0,4154 | 0,7288 |
| 0,7538 | 0,9322 |
| 1 | 1 |
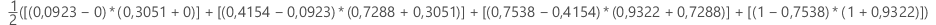

Notação
| Termo | Descrição |
|---|---|
| TRP | taxa de positivos verdadeiros |
| FPR | taxa de falsos positivos |
| TP | positivos verdadeiros, eventos que foram corretamente avaliados |
| P | número de eventos positivos reais |
| FP | negativos verdadeiros, não eventos que foram corretamente avaliados |
| N | número de eventos negativos reais |
| FNR | taxa de falsos negativos |
| TNR | taxa de negativos verdadeiros |
IC de 95% para a área sob a curva ROC
O intervalo a seguir fornece os limites superiores e inferiores para o intervalo de confiança:
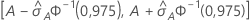
O cálculo do erro padrão da área sob a curva ROC (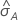 ) vem de Salford Predictive Modeler®. Para obter informações gerais sobre a estimativa da variância da área sob a curva ROC, consulte as seguintes referências:
) vem de Salford Predictive Modeler®. Para obter informações gerais sobre a estimativa da variância da área sob a curva ROC, consulte as seguintes referências:
Engelmann, B. (2011). Measures of a ratings discriminative power: Applications and limitations. In B. Engelmann & R. Rauhmeier (Eds.), The Basel II Risk Parameters: Estimation, Validation, Stress Testing - With Applications to Loan Risk Management (2ª ed.) Heidelberg; Nova York: Springer. doi:10.1007/978-3-642-16114-8
Cortes, C. e Mohri, M. (2005). Confidence intervals for the area under the ROC curve. Advances in neural information processing systems, 305-312.
Feng, D., Cortese, G., e Baumgartner, R. (2017). A comparison of confidence/credible interval methods for the area under the ROC curve for continuous diagnostic tests with small sample size. Statistical Methods in Medical Research, 26(6), 2603-2621. doi:10.1177/0962280215602040
Notação
| Termo | Descrição |
|---|---|
| A | área sob a curva ROC |
 | 0,975 percentil da distribuição normal padrão |
Ganho
Fórmula
Para os 10% das observações nos dados com as probabilidades mais altas serem atribuídos à classe de eventos, use a seguinte fórmula.
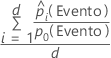
Para o ganho de teste com um conjunto de dados de teste, use as observações do conjunto de dados de teste. Para o ganho do teste com validação cruzada em de K dobras, selecione os dados a serem usados e calcule o ganho das probabilidades preditas para dados que não estão na estimativa do modelo.
Notação
| Termo | Descrição |
|---|---|
| d | número de casos em 10% dos dados |
 | probabilidade predita do evento |
 | probabilidade de evento nos dados de treinamento ou, se a análise não utilizar validação, no conjunto de dados completo |
Custo de classificação errada
O custo de classificação errada na tabela de sumário do modelo é o custo relativo de classificação errada para o modelo em relação a um classificador trivial que classifica todas as observações na classe mais frequente.
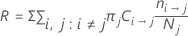
O custo relativo de classificação errada tem a seguinte forma:
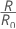
Em que R0 ié o custo para o classificador trivial.
A fórmula para R simplifica quando as probabilidades a priori são iguais ou são provenientes dos dados.
Probabilidades a priori iguais

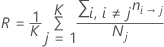
Probabilidades a priori dos dados

Com esta definição, R tem a seguinte forma:
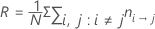
Notação
| Termo | Descrição |
|---|---|
| πj | probabilidade a priori da ja classe da variável resposta |
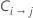 | custo de classificar errado a classe i como classe j |
 | Número de registros da classe i classificados incorretamente como classe j |
| Nj | número de casos na ja classe da variável resposta |
| K | número de classes na variável resposta |
| N | número de casos nos dados |