Neste tópico
Distância quadrada
Distância quadrada de Mahalanobis - Forma geral
A distância quadrada (também chamada de distância de Mahalanobis) da observação x ao centro (média) do grupo t para discriminante linear é dada pela seguinte forma geral:

Distância quadrada de Mahalanobis - Função quadrática
A distância quadrada de Mahalanobis de x para o grupo t para a função discriminante quadrática é calculada da seguinte forma:

Distância quadrada generalizada - Função linear
A distância quadrada generalizada de x para o grupo t para a função discriminante linear é calculada da seguinte forma:
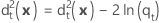
Distância quadrada generalizada - Função quadrática
A distância quadrada generalizada de x para o grupo t para a função discriminante quadrática é calculada da seguinte forma:

Probabilidade posterior
A probabilidade posterior para x pertencente ao grupo t é calculada da seguinte maneira:
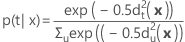
Escores discriminantes lineares
Os escores discriminantes lineares são calculados da seguinte maneira:

Notação
| Termo | Descrição |
|---|---|
| x | vetor da coluna de comprimento p contendo os valores das preditoras desta observação (esse vetor da coluna está armazenado como uma linha) |
| p | número de preditoras |
| n | número total de observações |
| t | identificações do grupo |
| nt | número de observações no grupo t |
| qt | a probabilidade anterior do grupo t, que iguala nt/r |
| Sp | a matriz de covariância combinada para análise discriminante linear |
| Si | matriz de covariância do grupo i para análise discriminante quadrática |
| mt | vetor da coluna de comprimento p contendo as médias das preditoras calculadas a partir dos dados no grupo t |
| St | matriz de covariância do grupo t |
| |St| | determinante de St |
Função discriminante linear

Para um dada x, esta regra aloca x ao grupo com a maior função discriminante linear.
Notação
| Termo | Descrição |
|---|---|
| x | vetor da coluna de comprimento p contendo os valores das preditoras desta observação (esse vetor da coluna está armazenado como uma linha) |
| mi | vetor da coluna de comprimento p contendo as médias das preditoras calculadas a partir dos dados no grupo i |
| Sp | matriz de covariância combinada |
| ln pi | log natural da probabilidade anterior para o grupo i |
Distância quadrada generalizada

Notação
| Termo | Descrição |
|---|---|
| x | vetor da coluna de comprimento p contendo os valores das preditoras desta observação (esse vetor da coluna está armazenado como uma linha) |
| mi | vetor da coluna de comprimento p contendo as médias das preditoras calculadas a partir dos dados no grupo i |
| Sp | matriz de covariância combinada f |
| ln pi | log natural da probabilidade anterior para o grupo i |
Probabilidade posterior
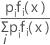
A maior probabilidade posterior é equivalente ao maior valor de ln [pi fi (x)]


Notação
| Termo | Descrição |
|---|---|
| pi | probabilidade anterior para o grupo i |
| fi(x) | a densidade conjunta para os dados no grupo i (com os parâmetros da população substituídos pelas estimativas da amostra) |