Análise de variância

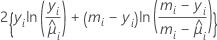
A tabela de desviância é construída com base no seguinte resultado geral que supõe que ϕ é conhecido. Se DI for a desviância associada a um modelo inicial e DS for a desviância associada a um subconjunto de termos no modelo inicial, sob algumas condições de regularidade, a seguinte relação existe:

A diferença entre as desviâncias é assintoticamente distribuída como uma distribuição qui-quadrado com d graus de liberdade. Essas estatísticas são calculadas para análise ajustada (tipo III) e análise sequencial (tipo I). A desviância ajustada e a estatística qui-quadrado na tabela de desviâncias são iguais. A desviância média ajustada é a desviância ajustada dividida pelos graus de liberdade.
Para a análise sequencial, a saída depende da ordem em que as preditoras entram no modelo. A desviância sequencial é a parte exclusiva da desviância que uma preditora explica, dadas quaisquer preditoras já no modelo. Se você tiver um modelo com três preditoras, X1, X2 e X3, a desviância sequencial para X3 mostra quanto da desviância restante que X3 explica, dado que X1 e X2 já estejam no modelo. Para obter uma desviância sequencial diferente, repita o procedimento de regressão inserindo as preditoras em uma ordem diferente.
Se ϕ for desconhecido, quanto às respostas que seguem uma distribuição normal, sob algumas condições de regularidade, a relação muda para o seguinte:
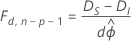
Aqui, a diferença entre as desviâncias é assintoticamente distribuída como uma distribuição F com d graus de liberdade para o numerador e n − p graus de liberdade para o denominador. Para estimar o parâmetro de dispersão, use o modelo inicial.
Notação
| Termo | Descrição |
|---|---|
| yi | o número de eventos da iésima linha |
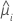 | a resposta média estimada da iésima linha |
| mi | o número de ensaios da iésima linha |
| Lf | a log-verossimilhança do modelo completo |
| Lc | a log-verossimilhança do modelo com um subconjunto de termos do modelo completo |
| d | os graus de liberdade são a diferença entre os números de parâmetros nos modelos a comparar |
| ϕ | o parâmetro de dispersão, conhecido por ser 1 para o modelo binomial |
| n | o número de linhas nos dados |
| p | os graus de liberdade da regressão do modelo inicial |
Graus de liberdade (DF)
Diferentes somas de quadrados têm diferentes graus de liberdade.
DF para um fator numérico = 1
DF para um fator categórico = b − 1
DF para um termo quadrático = 1
DF para blocos = c − 1
DF para erro = n − p
DF total = n − 1

Observação
Os fatores categóricos em filtragens de experimentos no Minitab têm 2 níveis. Assim, os graus de liberdade para um fator categórico são 2 - 1 = 1. Por extensão, as interações entre fatores também têm um grau de liberdade.
Notação
| Termo | Descrição |
|---|---|
| b | O número de níveis no fator |
| c | O número de blocos |
| n | O número de linhas no experimento |
| ni | O número de observações para a ia combinação de níveis de fatores |
| m | O número de combinações de níveis de fator |
| p | O número de coeficientes |
Log-verossimilhança
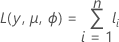
A forma geral das contribuições individuais são as seguintes:

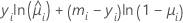
Notação
| Termo | Descrição |
|---|---|
| yi | o número de eventos da iésima linha |
| mi | o número de ensaios da iésima linha |
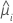 | a resposta média estimada da iésima linha |
valor-p (P)
Usado nos testes de hipóteses para ajudá-lo a decidir se deve rejeitar ou não rejeitar uma hipótese nula. O valor-p é a probabilidade de se obter uma estatística de teste que seja pelo menos tão extrema quanto o valor calculado real, se a hipótese nula for verdadeira. Um valor cortado comumente usado para o valor-p é 0,05. Por exemplo, se o valor-p calculado de uma estatística de teste for menor do que 0,05, você rejeita a hipótese nula.