Neste tópico
Etapa1: Determine se a associação entre a resposta e o termo é estatisticamente significativa
- Valor-p ≤ α: a associação é estatisticamente significativa
- Se o valor-p for menor ou igual ao nível de significância, é possível concluir que há uma associação estatisticamente significativa entre a variável de resposta e o termo.
- Valor-p > α: a associação não é estatisticamente significativa
- Se o valor-p for maior ou igual ao nível de significância, não é possível concluir que há uma associação estatisticamente significativa entre a variável de resposta e o termo. Talvez seja necessário reajustar o modelo sem o termo.
- Se um fator fixo é significativo, é possível concluir que nem todas as médias de nível são iguais.
- Se um fator aleatório é significativo, é possível concluir que o fator contribui para a quantidade de variação na resposta.
- Se um termo de interação é significativo, a relação entre um fator e a resposta depende dos outros fatores do termo. Neste caso, você não deve interpretar os principais efeitos sem considerar o efeito da interação.
Use a tabela Médias para entender as diferenças estatisticamente significativas entre os níveis de fatores em seus dados. A média de cada grupo fornece uma estimativa de cada média da população. Procure por diferenças entre médias de grupo para termos que são estatisticamente significativos.
Para efeitos principais, a tabela apresenta os grupos dentro de cada fator e suas médias. Para efeitos de interação, a tabela apresenta todas as combinações possíveis dos grupos. Se um termo de interação for estatisticamente significativo, não interprete os efeitos principais sem considerar os efeitos da interação.
Informações dos Fatores
| Fator | Tipo | Níveis | Valores |
|---|---|---|---|
| Tempo | Fixo | 2 | 1; 2 |
| Operador | Aleatório | 3 | 1; 2; 3 |
| Configuração | Fixo | 3 | 35; 44; 52 |
Análise de Variância para Espessura
| Fonte | GL | SQ | QM | F | P | |
|---|---|---|---|---|---|---|
| Tempo | 1 | 9,0 | 9,00 | 0,29 | 0,644 | |
| Operador | 2 | 1120,9 | 560,44 | 4,28 | 0,081 | x |
| Configuração | 2 | 15676,4 | 7838,19 | 73,18 | 0,001 | |
| Tempo*Operador | 2 | 62,0 | 31,00 | 4,34 | 0,026 | |
| Tempo*Configuração | 2 | 114,5 | 57,25 | 8,02 | 0,002 | |
| Operador*Configuração | 4 | 428,4 | 107,11 | 15,01 | 0,000 | |
| Erro | 22 | 157,0 | 7,14 | |||
| Total | 35 | 17568,2 |
Sumário do Modelo
| S | R2 | R2(aj) |
|---|---|---|
| 2,67140 | 99,11% | 98,58% |
Termos de erro para testes
| Fonte | Componente de variância | Termo de erro | Quadrado Médio Esperado para Cada Termo (usando o modelo irrestrito) | |
|---|---|---|---|---|
| 1 | Tempo | 4 | (7) + 6 (4) + Q[1; 5] | |
| 2 | Operador | 35,789 | * | (7) + 4 (6) + 6 (4) + 12 (2) |
| 3 | Configuração | 6 | (7) + 4 (6) + Q[3; 5] | |
| 4 | Tempo*Operador | 3,977 | 7 | (7) + 6 (4) |
| 5 | Tempo*Configuração | 7 | (7) + Q[5] | |
| 6 | Operador*Configuração | 24,994 | 7 | (7) + 4 (6) |
| 7 | Erro | 7,136 | (7) |
Termos de Erro para Testes Sintetizados
| Fonte | GL do Erro | QM do Erro | Síntese do QM do Erro | |
|---|---|---|---|---|
| 2 | Operador | 5,12 | 130,9747 | (4) + (6) - (7) |
Médias
| Tempo | N | Espessura |
|---|---|---|
| 1 | 18 | 67,7222 |
| 2 | 18 | 68,7222 |
| Configuração | N | Espessura |
|---|---|---|
| 35 | 12 | 40,5833 |
| 44 | 12 | 73,0833 |
| 52 | 12 | 91,0000 |
| Tempo*Configuração | N | Espessura |
|---|---|---|
| 1 35 | 6 | 40,6667 |
| 1 44 | 6 | 70,1667 |
| 1 52 | 6 | 92,3333 |
| 2 35 | 6 | 40,5000 |
| 2 44 | 6 | 76,0000 |
| 2 52 | 6 | 89,6667 |
Principais resultados: valor de P, tabela Médias
Configuração é um fator fixo e este efeito principal é significativo. Este resultado indica que a espessura de revestimento média não é igual para todas as configurações da máquina.
Tempo*Configuração é um efeito de interação que envolve dois fatores fixos. Este efeito de interação é significativo, o que indica que a relação entre cada fator e a resposta depende do nível do outro fator. Neste caso, você não deve interpretar os principais efeitos sem considerar o efeito da interação.
Nestes resultados, a tabela Médias mostra como a espessura média varia de acordo com o tempo, configuração da máquina e cada combinação de tempo e configuração de máquina. A configuração é estatisticamente significativa e as médias diferem entre as configurações de máquina. No entanto, como o termo de interação Tempo*Configuração é estatisticamente significativo, não interprete os efeitos principais sem considerar os efeitos da interação. Por exemplo, a tabela para o termo de interação mostra que com uma configuração de 44, o tempo 2 está associado a um revestimento mais espesso. No entanto, com uma configuração de 52, o tempo 1 está associado a um revestimento mais espesso.
O operador é um fator aleatório e todas as interações que incluem um fator aleatório são consideradas como aleatórias. Se um fator aleatório é significativo, é possível concluir que o fator contribui para a quantidade de variação na resposta. Operador não é significativo ao nível de 0,05, mas os efeitos de interação que incluem operador são significativos. Estes efeitos de interação indicam que a quantidade de variação com que o operador contribui para a resposta depende do valor do tempo e da configuração da máquina.
Etapa 2: Determine se o modelo ajusta bem os dados
Para determinar se o modelo ajusta bem os dados, examine as estatísticas de qualidade do ajuste tabela do resumo do modelo.
- S
-
Use S para avaliar se o modelo descreve bem a resposta. Use S em vez das estatísticas de R2 para comparar o ajuste de modelos que não têm constante.
S é medido nas unidades da variável de resposta e representa o quão longe os valores de dados caem dos valores ajustados. Quanto mais baixo for o valor de S, melhor o modelo descreve a resposta. No entanto, um valor de S baixo por si só não indica que o modelo satisfaz aos pressupostos do modelo. Você deve verificar os gráficos de resíduos para conferir os pressupostos.
- R2
-
Quanto mais alto o valor de R2 melhor o modelo ajusta seus dados. O valor de R2 está sempre entre 0 e 100%.
O R2 sempre aumenta quando você adiciona mais preditores a um modelo. Por exemplo, o melhor modelo de cinco preditores terá sempre um R2 que é pelo menos tão elevado quanto o melhor modelo de quatro preditores. Portanto, R2 é mais útil quando for comparado a modelos do mesmo tamanho.
- R2 (aj)
-
Use o R2 ajustado quando desejar comparar modelos que têm diferentes números de preditores. R2 sempre aumenta quando você adiciona um preditor ao modelo, mesmo quando não existe uma verdadeira melhoria ao modelo. O valor de R2 ajustado incorpora o número de preditores no modelo para ajudá-lo a escolher o modelo correto.
-
Amostras pequenas não fornecem uma estimativa precisa da força da relação entre a resposta e os preditores. Por exemplo, se você precisar que R2 seja mais exato, deve usar uma amostra maior (geralmente, 40 ou mais).
-
A estatística de qualidade do ajuste é apenas uma medida do grau em que o modelo ajusta os dados (se ajusta bem ou mal). Mesmo quando um modelo tem um um valor desejável, você deve verificar os gráficos de resíduos para conferir se o modelo atende aos pressupostos do modelo.
Sumário do Modelo
| S | R2 | R2(aj) |
|---|---|---|
| 2,67140 | 99,11% | 98,58% |
Principais resultados: S, R2, R2 (aj)
Nestes resultados, o modelo explica 99,11% da variação da espessura do revestimento. Por estes dados, o valor de R2 indica que o modelo fornece um bom ajuste aos dados. Se os modelos adicionais forem ajustados com diferentes preditores, utilize os valores de R2 ajustados para comparar se os modelos ajustam bem os dados.
Etapa 3: Determinar se o modelo atende às suposições da análise
Use os gráficos de resíduos para ajudar a determinar se o modelo é adequado e satisfaz aos pressupostos da análise. Se os pressupostos não forem satisfeitos, o modelo pode não ajustar bem os dados e você deve ter cautela ao interpretar os resultados.
Para obter mais informações sobre como lidar com os padrões nos gráficos residuais, vá para Gráficos de resíduos para Ajustar modelo linear generalizado e clique no nome do gráfico residual na lista na parte superior da página.
Gráficos de resíduos versus de ajustes
Use o gráfico de resíduos versus ajustes para verificar a pressuposição de que os resíduos são aleatoriamente distribuídos e têm variância constante. De maneira ideal, os pontos devem cair aleatoriamente em ambos os lados de 0, sem padrões reconhecíveis nos pontos.
| Padrão | O que o padrão pode indicar |
|---|---|
| Dispersão grande ou irregular de resíduos entre valores ajustados | Variância não constante |
| Curvilíneo | Um termo de ordem mais alta ausente |
| Um ponto que está distante de zero | Um outlier |
| Um ponto que é distante dos outros pontos na direção x | Um ponto influente |
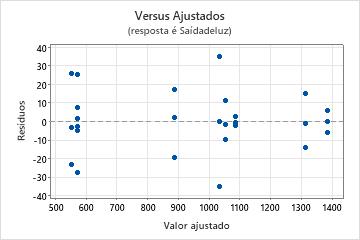
Gráfico de resíduos versus ordem
Tendência
Deslocamento
Ciclo
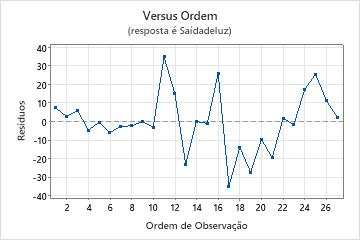
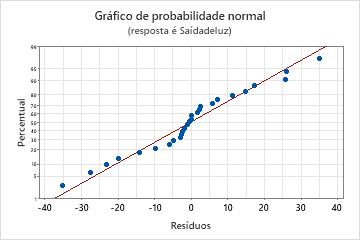
Gráfico de probabilidade normal
Use o gráfico de probabilidade normal de resíduos para verificar a pressuposição de que os resíduos são distribuídos normalmente. O gráfico de probabilidade normal dos resíduos deve seguir aproximadamente uma linha reta.
| Padrão | O que o padrão pode indicar |
|---|---|
| Não é uma linha reta | Não normalidade |
| Um ponto que está distante da linha | Um outlier |
| Alteração de inclinação | Uma variável não identificada |