Z.LSL, Z.USL e Z.Bench para capacidade potencial (dentro)
A estatística de Benchmark Z para a capacidade potencial é calculados encontrando o valor Z usando a (0,1) distribuição padrão normal para as estatísticas correspondentes.


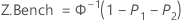
onde:


Notação
| Termo | Descrição |
|---|---|
| Φ (X) | A função distribuição acumulada (FDA) da distribuição normal padrão |
| Φ-1 (X) | FDA inversa de uma distribuição-normal-padrão |
 | Desvio padrão dentro do subgrupo |
Intervalos de confiança para Z.bench para um processo com dois limites de especificação
Intervalo bilateral


em que
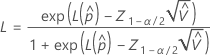
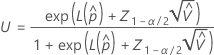
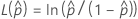

Para calcular  , substitua as estimativas da amostra pelos parâmetros da fórmula para
, substitua as estimativas da amostra pelos parâmetros da fórmula para 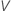 :
:



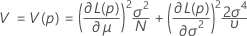
em que
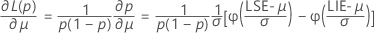

Limite de confiança superior unilateral
Para calcular um limite de confiança superior unilateral, altere 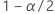 Até
Até  na definição de U.
na definição de U.
Notação
| Termo | Descrição |
|---|---|
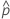 | as probabilidades estimadas de cauda que estejam fora dos limites de especificação |
 | o (1 - α / 2)o percentil da distribuição normal padrão |
| α | o alfa para o nível de confiança |
 | a média do processo (estimada a partir dos dados da amostra ou de um valor histórico) |
| s | o desvio padrão da amostra dentro de subgrupos |
| υ | os graus de liberdade para s |
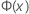 | a função de distribuição acumulada (FDA) de uma distribuição normal padrão |
 | a Função de Densidade de Probabilidade (FDP) de uma distribuição normal padrão |
| LSE | o limite superior de especificação |
| LIE | o limite inferior de especificação |
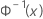 | a fda inversa de uma distribuição normal padrão |
Intervalos de confiança para Z.bench para um processo com um limite de especificação
Os cálculos para o intervalo de confiança para Z.Bench dependem de quais limites de especificação o processo tem.
Limite inferior de especificação, intervalo de confiança bilateral
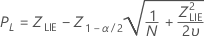
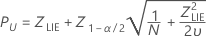

Limite inferior de especificação, limite de confiança unilateral

O Minitab resolve a seguinte equação para encontrar p1:

em que

Limite superior de especificação, intervalo de confiança bilateral
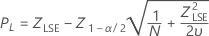
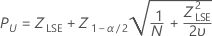

Limite superior de especificação, limite de confiança unilateral

O Minitab resolve a seguinte equação para encontrar p2:
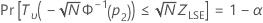
em que

Notação
| Termo | Descrição |
|---|---|
| LIE | o limite inferior de especificação |
| LSE | o limite superior de especificação |
| α | o alfa para o nível de confiança |
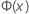 | a função de distribuição acumulada (FDA) de uma distribuição normal padrão |
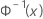 | a fda inversa de uma distribuição normal padrão |
 | o (1 - α / 2)o percentil da distribuição normal padrão |
| N | o número total de medições |
| υ | os graus de liberdade para s |
 | a média do processo (estimada a partir dos dados da amostra ou de um valor histórico) |
| s | o desvio padrão da amostra dentro de subgrupos |
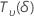 | Uma variável aleatória que é distribuída como uma distribuição t não central com  Graus de liberdade e parâmetro de não centralidade δ Graus de liberdade e parâmetro de não centralidade δ |