한 티셔츠 가게의 구매자가 티셔츠의 크기별 판매 비율과 주문 비율을 비교하려고 합니다. 구매자는 한 주에 판매되는 티셔츠의 수를 카운트합니다.
구매자는 판매되는 티셔츠 크기의 비율이 주문되는 티셔츠 크기의 비율과 비례하는지 여부를 확인하기 위해 카이-제곱 적합도 검정을 수행합니다.
- 표본 데이터티셔츠판매.MWX을 엽니다.
- 을 선택합니다.
- 관측 개수에 카운트을 입력합니다.
- 범주 이름(옵션)에 크기을 입력합니다.
- 검정에서 특정 비율을 선택하고 비율을 입력합니다.
- 확인을 클릭합니다.
결과 해석
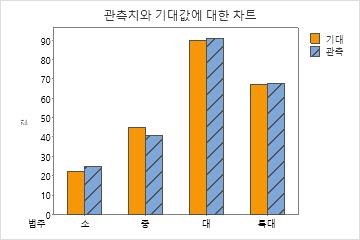
이 결과에서 티셔츠 크기별 관측된 카운트는 기대 카운트와 크게 다르지 않습니다. 크기별 카운트는 다음과 같습니다.
- 작은 치수의 티셔츠는 22.5장 판매될 것으로 예상되었는데 25장 판매되었습니다.
- 중간 치수의 티셔츠는 45장 판매될 것으로 예상되었는데 41장 판매되었습니다.
- 큰 치수의 티셔츠는 90장 판매될 것으로 예상되었는데 91장 판매되었습니다.
- 특대 치수의 티셔츠는 68장 판매될 것으로 예상되었는데 67.5장 판매되었습니다.
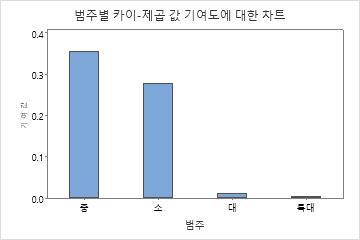
실제 판매량과 예상 판매량 사이에 가장 큰 차이가 있는 것은 중간 치수 범주입니다. 결과적으로 이 범주가 카이-제곱 통계량 0.355에 가장 크게 기여합니다.
전체 카이-제곱 통계량은 0.648이며 0.885의 p-값을 제공합니다. p-값이 유의 수준 0.05보다 크기 때문에 구매자는 귀무 가설을 기각할 수 없습니다. 구매자는 관측된 티셔츠 판매량과 기대되는 티셔츠 판매량 사이에 유의한 차이가 없다는 결론을 내립니다.
관측 및 기대 카운트
| 범주 | 관측 | 검정 비율 | 기대 | 카이-제곱에 대 한 기여도 |
|---|---|---|---|---|
| 소 | 25 | 0.1 | 22.5 | 0.277778 |
| 중 | 41 | 0.2 | 45.0 | 0.355556 |
| 대 | 91 | 0.4 | 90.0 | 0.011111 |
| 특대 | 68 | 0.3 | 67.5 | 0.003704 |
카이-제곱 검정
| N | DF | 카이-제곱 | P-값 |
|---|---|---|---|
| 225 | 3 | 0.648148 | 0.885 |