모수
모수는 대화 상자에서 선택한 통계량을 보여줍니다. 모수는 분포 곡선을 그리기 위해 확률 분포 함수(PDF)의 입력 값으로 사용되며 모집단 전체를 설명하는 측도입니다. 자세한 내용은 모수, 모수 추정치 및 표본 추출 분포의 정의에서 확인하십시오.
관측치의 길이
포아송 공정에서는 지정된 관측 범위에서 시간, 넓이, 부피, 항목 수 등을 나타내는 특정한 사건 또는 속성의 발생 횟수를 셉니다. 관측치의 길이는 각 관측 범위의 양, 기간, 크기를 나타냅니다.
해석
Minitab에서는 발생률을 상황에 가장 적합한 형태로 변환하기 위해 관측치의 길이를 사용합니다.
예를 들어, 각 표본 관측치가 연간 사건 발생 횟수를 세는 경우, 길이 1은 연간 발생률을 나타내고 길이 12는 월간 발생률을 나타냅니다.
- 검사자들이 122개의 결점을 찾기 때문에 총 발생 횟수는 122입니다.
- 검사자들이 50개의 상자를 표본으로 추출하기 때문에 표본 크기(N)는 50입니다.
- 상자마다 10장의 타월이 들어 있기 때문에 검사자들은 타월당 결점 수를 계산하기 위해 관측치 길이로 10을 사용합니다. 상자당 결점 수를 계산하기 위해서는 관측치 길이로 1을 사용합니다.
- 발생률은 (전체 발생 횟수 / N) / (관측치의 길이) = (122/50) / 10 = 0.244입니다. 따라서 각 타월에는 평균 0.244개의 결점이 있습니다.
분포
- 정규 분포
-
정규 분포는 평균의 연속 표준 편차가 데이터 관측치의 백분율을 추정하기 위한 벤치마크를 지정하는 종 모양의 분포입니다. 이러한 벤치마크는 Z-검정 및 t-검정과 같은 많은 가설 검정의 기본이 됩니다.
예를 들어 펜실베니아 주에 거주하는 모든 성인 남성의 키는 정규 분포를 근사하게 따릅니다. 따라서 대다수 남성의 키는 평균 키 69인치에 가깝습니다. 평균 키보다 약간 큰 남성의 수와 69인치보다 약간 작은 남성의 수는 비슷합니다. 몇 명만이 평균보다 훨씬 더 크거나 훨씬 더 작습니다.
- 이항 분포
-
항목, 사건 또는 사람을 두 범주 중 하나로 독립적으로 분류하는 경우 한 범주의 항목, 사건 또는 사람 수는 이항 분포를 따릅니다. 두 범주는 예/아니오, 합격/불합격 또는 불량/양호와 같이 서로 배타적이어야 합니다.
예를 들어, 엔지니어들이 볼트를 검사하고 볼트를 사용할 수 없도록 만드는 심각한 갈라짐이 있는지 확인합니다. 갈라짐이 없는 볼트는 양호하고 갈라짐이 있는 볼트는 불량입니다.
- 포아송 분포
-
일정 시간, 영역, 기타 관측 기간에 걸쳐 특징, 결과 또는 작업 존재를 카운트하는 경우 포아송 데이터를 얻습니다. 포아송 데이터는 단위 크기가 동일한 상태에서 단위당 카운트로 평가됩니다.
예를 들어, 한 버스 회사의 검사자가 30일간 일별 버스 고장의 횟수를 셉니다.
표준 편차
표준 편차는 산포, 즉 데이터가 평균을 중심으로 퍼져 있는 정도를 나타내는 가장 일반적인 측도입니다. 모집단의 표준 편차를 나타내는 데는 σ(시그마) 기호를 자주 사용하는 반면, 표본의 표준 편차를 사용하는 데는 s를 사용합니다. 랜덤이 아니거나 공정에 자연스럽지 못한 변동을 종종 잡음이라고 합니다. Minitab에서 표시하는 값은 사용자가 대화 상자에서 지정한 계획 값입니다.
비율
비율은 개수 또는 빈도와 달리 전체에 대한 상대 비율로, 사건 수를 표본 크기로 나눈 값과 같습니다. Minitab에서 표시하는 값은 사용자가 대화 상자에서 지정한 계획 값입니다.
발생률
발생률은 관측치의 단위 길이당 사건이 발생한 평균 횟수입니다. Minitab에서 표시하는 값은 사용자가 대화 상자에서 지정한 계획 값입니다.
평균
포아송 평균은 전체 관측 공간에 걸쳐 사건이 발생한 평균 횟수입니다. Minitab에서 표시하는 값은 사용자가 대화 상자에서 지정한 계획 값입니다.
신뢰 수준
95%의 신뢰 수준은 일반적으로 잘 작동합니다. 이 신뢰 수준은 한 모집단에서 선택한 20개의 표본 중 19개(95%)가 모집단 모수를 포함하는 신뢰 구간을 생성할 것임을 나타냅니다.
신뢰 수준은 동일한 모집단에서 반복해서 표본을 추출할 경우 모집단 모수를 포함할 구간의 비율을 나타냅니다. 따라서 100개의 표본을 추출하고 100개의 95% 신뢰 구간을 생성한 경우, 다음 그림에 표시된 것처럼 약 95%의 구간에 모집단 모수(예: 모집단의 평균)가 포함될 것으로 예상됩니다.
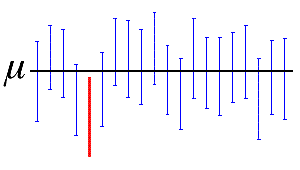
이 그림에서 수평선은 알 수 없는 모평균 µ의 고정 값을 나타냅니다. 수평선과 겹치는 19개의 파란색 수직 신뢰 구간에는 모평균 값이 포함됩니다. 완전히 수평선 아래 있는 1개의 빨간색 신뢰 구간에는 모평균 값이 포함되지 않습니다.
신뢰 구간
Minitab에서는 사용자가 대화 상자에서 지정한 신뢰 구간의 유형을 표시합니다.
신뢰 구간은 모집단 비율이 될 수 있는 값의 범위를 제공합니다. 표본이 랜덤이기 때문에 모집단의 두 표본에서 동일한 신뢰 구간이 생성될 가능성은 없습니다. 그러나 표본 추출을 여러 번 반복하면 일정한 백분율의 신뢰 구간이나 한계에는 알 수 없는 모집단 모수가 포함됩니다. 모수를 포함하는 이러한 신뢰 구간 또는 한계의 백분율이 해당 구간의 신뢰 수준입니다.
상한은 모집단 모수가 더 작을 가능성이 높은 값을 정의합니다. 하한은 모집단 모수가 더 클 가능성이 높은 값을 정의합니다.