런 검정과 함께 제공되는 모든 통계량에 대한 정의 및 해석 방법을 확인해 보십시오.
N
표본 크기(N)는 표본의 총 관측치 수입니다. 표본 크기는 기대되는 런 수와 p-값에 영향을 미칩니다.
K
K는 비교 기준의 값입니다. 기본적으로 K는 표본 데이터의 평균입니다. 그러나 중위수 등 다른 값을 지정할 수도 있습니다. Minitab에서는 관측 런 수를 계산하기 위해 K를 사용합니다.
K보다 작거나 같음 및 K보다 큼
K보다 큰 관측치 수는 비교 기준의 값(기본적으로 평균)보다 큰 관측치의 수입니다. K보다 작은 관측치 수는 비교 기준보다 작거나 같은 관측치의 수입니다. Minitab에서는 p-값을 계산하기 위해 이러한 값을 사용합니다.
귀무 가설과 대립 가설
귀무 가설과 대립 가설은 데이터 순서에 대한 서로 배타적인 두 서술문입니다. 가설 검정은 표본 데이터를 사용하여 귀무 가설의 기각 여부를 확인합니다.
- 귀무 가설
- 데이터 순서가 랜덤합니다.
- 대립 가설
- 데이터 순서가 랜덤하지 않습니다.
관측 런 수 및 기대 런 수
관측 런 수는 비교 기준 K보다 크거나 작은 관측치 그룹의 수입니다. 선은 K를 나타냅니다. 이 예에는 다섯 개의 런이 포함되어 있습니다.
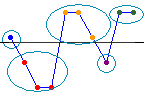
기대 런 수는 랜덤 시리즈에서 런의 표본 추출 분포에 대한 평균입니다. 관측 런 수가 기대 런 수보다 상당히 크거나 작으면 데이터 순서가 랜덤하지 않을 가능성이 높습니다. 데이터 순서가 랜덤한지 여부를 확인하려면 p-값을 유의 수준과 비교하십시오.
p-값
p-값은 귀무 가설에 반하는 증거를 측정하는 확률입니다. p-값이 작을수록 귀무 가설에 반하는 더 강력한 증거가 됩니다.
해석
데이터 순서가 랜덤한지 여부를 확인하려면 p-값을 사용합니다.
데이터 순서가 랜덤한지 여부를 확인하려면 p-값을 유의 수준과 비교하십시오. 일반적으로 0.05의 유의 수준(α 또는 알파로 표시함)이 좋습니다. 0.05의 유의 수준은 데이터 순서가 실제로 랜덤하지만 랜덤하지 않다는 결론을 내릴 위험이 5%라는 것을 나타냅니다.
- p-값 ≤ α: 데이터 순서가 랜덤하지 않습니다(H0 기각).
- p-값이 유의 수준보다 작거나 같으면 귀무 가설을 기각하고 데이터 순서가 랜덤하지 않다는 결론을 내립니다.
- p-값 > α: 데이터 순서가 랜덤하지 않다는 결론을 내릴 수 없습니다(H0을 기각할 수 없음)
- p-값이 유의 수준보다 크면 귀무 가설을 기각할 수 없습니다. 데이터 순서가 랜덤하지 않다는 결론을 내릴 충분한 증거가 없습니다.