원하는 방법 또는 공식을 선택하십시오.
이 항목의 내용
평균 순위
Minitab에서는 평균 순위를 다음과 같이 계산합니다.
- 가장 작은 관측치에 순위 1을 지정하고 두 번째로 작은 관측치에 순위 2를 지정하는 방식으로 결합된 표본에 순위를 매깁니다.
- 둘 이상의 관측치가 같은 경우 Minitab에서는 두 관측치에 모두 평균 순위를 지정합니다.
- 각 표본의 순위에 대한 평균을 계산합니다.
Minitab에서는 결과의 평균 순위 아래 각 그룹에 대한 값을 표시합니다.
z-값
공식
Minitab에서는 각 그룹에 대한 z-값을 다음과 같이 계산합니다.
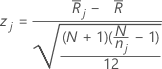
표기법
| 용어 | 설명 |
|---|---|
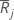 | 그룹 j의 평균 순위 |
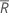 | 모든 관측치의 평균 순위 |
| N | 관측치 수 |
| nj | j번째 그룹의 관측치 수 |
같은 값 순위매기기
같은 값은 두 개 이상의 관측치가 같을 때 발생합니다. 데이터에 같은 값이 있는 경우, Minitab에서는 다음과 같이 데이터에 순위를 매깁니다.
- 괸측치를 오름차순으로 정렬합니다.
- 같은 값이 없는 것처럼 각 관측치에 순위를 지정합니다.
- 같은 값의 집합인 경우, 해당하는 순위의 평균을 계산하여 이 값을 해당 집합에 있는 각 같은 값에 새 순위로 지정합니다.
예
표본에 2.4, 5.3, 2.4, 4.0, 1.2, 3.6, 4.0, 4.3, 4.0의 9개 관측치가 있습니다.
| 관측치 | 순위(같은 값이 없는 것으로 가정) | 순위 |
|---|---|---|
| 1.2 | 1 | 1 |
| 2.4 | 2 | 2.5 |
| 2.4 | 3 | 2.5 |
| 3.6 | 4 | 4 |
| 4.0 | 5 | 6 |
| 4.0 | 6 | 6 |
| 4.0 | 7 | 6 |
| 4.3 | 8 | 8 |
| 5.3 | 9 | 9 |
다음 정보는 검정 통계량을 계산할 경우에도 사용됩니다.
- 같은 값의 집합 수 = 2
- 첫 번째 집합의 같은 값 수 = 2
- 두 번째 집합의 같은 값 수 = 3
H
공식

귀무 가설 하에서는 자유도가 k - 1인 카이-제곱 분포가 H의 분포와 근사합니다. 관측치가 다섯 개 미만인 그룹이 없는 경우 근사가 상당히 정확합니다. H 값이 크면 일부 중위수 간의 차이가 통계적으로 유의하다는 귀무 가설의 강력한 증거가 됩니다.
Lehmann (1975)1 등 일부 저자는 데이터에 같은 값이 있을 때 H를 조정할 것을 제안합니다. Minitab에서는 데이터에 같은 값이 있을 때 H(조정)를 표시합니다.
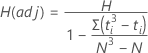
귀무 가설 하에서는 자유도가 k - 1인 카이-제곱 분포가 H 및 H(수정)의 분포와 근사합니다.
p-값 = 1 – CDF (χ2H, df)
p-값 = 1 – CDF (χ2H(adj), df)
작은 표본의 경우 Minitab에서는 정확 표를 사용할 것을 권장합니다. 자세한 내용은 Hollander and Wolfe (1973)2을 참조하십시오.
표기법
| 용어 | 설명 |
|---|---|
| nj | 그룹 j의 관측치 수 |
| N | 총 표본 크기 |
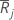 | 그룹 j의 순위 평균 |
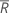 | 모든 순위의 평균 |
| ti | i번째 같은 값 집합의 같은 값 수 |
1 E.L. Lehmann (1975). Nonparametrics: Statistical Methods Based on Ranks, Holden-Day.
2 M. Hollander and D.A. Wolfe (1973). Nonparametric Statistical Methods, John Wiley & Sons, Inc.