다음 방법 및 공식은 검정 평균과 기준 평균의 비율을 검정하는 데 사용됩니다.
비율
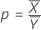
표기법
| 용어 | 설명 |
|---|---|
| ρ | 비율 |
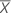 | 검정 평균 |
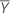 | 기준 평균 |
동등성 한계
k1을 하한 값 k2를 상한 값으로 지정합니다. 기본적으로 동등성 하한 δ1은 다음 공식에 의해 계산됩니다.

그리고 동등성 상한 δ2는 다음 공식에 의해 계산됩니다.

자유도(DF)

표기법
| 용어 | 설명 |
|---|---|
| v | 자유도 |
| n | 관측치 쌍의 수 |
S12
S12는 X 값과 Y 값 사이의 표본 공분산을 나타냅니다. 이 값은 CI 및 t-값의 계산에 사용됩니다. 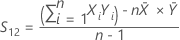
표기법
| 용어 | 설명 |
|---|---|
| Xi | 검정 표본의 i번째 관측치(예: Xi, Yi)는 i번째 관측치 쌍입니다. |
| Yi | 기준 표본의 i번째 관측치(예: Xi, Yi)는 i번째 관측치 쌍입니다. |
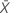 | 검정 표본의 평균 |
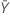 | 기준 표본의 평균 |
| n | 관측치 쌍의 수 |
신뢰 구간
다음 두 가지 조건 중 하나가 충족되는 경우 Minitab에서는 신뢰 구간(CI)을 계산할 수 없습니다.
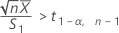
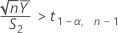
조건이 충족되는 경우 Minitab에서는 분석에 사용되는 방법을 기반으로 CI를 계산합니다.
- 100(1 - α)% CI
기본적으로 Minitab에서는 ρ에 대한 100(1 - α)% CI를 다음과 같이 계산합니다.
CI = [min(C, ρL), max(C, ρU)]
설명:
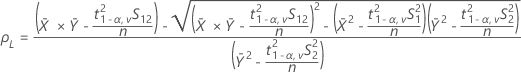
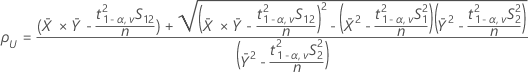
- 100(1 - 2α)% CI
100(1 - 2α)% CI를 사용하는 옵션을 선택할 경우 CI가 다음 공식에 의해 계산됩니다.
CI = [ρL, ρU] - 단측 구간
검정 평균 / 기준 평균 > 하한 가설의 경우 100(1 - α)% 하한은 ρL과 같습니다.
검정 평균 / 기준 평균 < 상한 가설의 경우 100(1 - α)% 하한은 ρU와 같습니다.
표기법
| 용어 | 설명 |
|---|---|
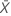 | 검정 표본의 평균 |
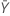 | 기준 표본의 평균 |
| S12 | X 값과 Y 값 간의 표본 공분산 |
| S1 | 검정 표본의 표준 편차 |
| n | 표본 크기 |
| S2 | 기준 표본의 표준 편차 |
| δ1 | 동등성 하한 |
| δ2 | 동등성 상한 |
| v | 자유도 |
| α | 검정의 유의 수준(알파) |
| t1-α,v | 자유도가 v인 t-분포의 1 - α 임계값 상한 |
t-값
t1을 가설  에 대한 t-값 t2를 가설
에 대한 t-값 t2를 가설  에 대한 t-값으로 정의합니다. 여기서
에 대한 t-값으로 정의합니다. 여기서  는 검정 모집단의 평균과 기준 모집단의 평균 비율입니다.
는 검정 모집단의 평균과 기준 모집단의 평균 비율입니다. 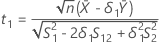
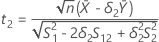
에 대한 t-값 t2를 가설 에 대한 t-값으로 정의합니다. 여기서 는 검정 모집단의 평균과 기준 모집단의 평균 비율입니다. 표기법
| 용어 | 설명 |
|---|---|
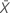 | 검정 표본의 평균 |
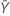 | 기준 표본의 평균 |
| S1 | 검정 표본의 표준 편차 |
| S2 | 기준 표본의 표준 편차 |
| S12 | X 값과 Y 값 간의 상관 관계 |
| n | 관측치 쌍의 수 |
| δ1 | 동등성 하한 |
| δ2 | 동등성 상한 |
| Λ | 검정 모집단의 평균과 기준 모집단 평균의 알 수 없는 비율 |
P-값
각 귀무 가설에 대한 확률 PH0은 다음과 같이 지정됩니다.
 인 경우,
인 경우,
| H0 | P-값 |
|---|---|
 |
 |
 |
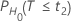 |
표기법
| 용어 | 설명 |
|---|---|
| Λ | 검정 모집단의 평균과 기준 모집단의 평균의 알 수 없는 비율 |
| δ1 | 동등성 하한 |
| δ2 | 동등성 상한 |
| v | 자유도 |
| T | 자유도가 v인 t-분포 |
| t1 | 다음 가설에 대한 t-값:  |
| t2 | 다음 가설에 대한 t-값:  |
참고
t-값이 계산되는 방법에 대한 정보는 t-값에 대한 절을 참조하십시오.