1단계: 검정 평균과 기준 평균이 동일한지 여부 결정
신뢰 구간을 동등성 한계와 비교합니다. 신뢰 구간이 동등성 한계 내에 완전히 포함되면 검정 모집단의 평균이 기준 모집단의 평균과 동일하다고 주장할 수 있습니다. 신뢰 구간의 일부가 동등성 한계를 벗어나면 동등성을 주장할 수 없습니다.
차이 = 평균(새 브랜드) - 평균(최고 브랜드)
| 차이 | 표준 편차 | SE | 95% 동등성 CI | 동등성 구간 |
|---|---|---|---|---|
| -0.11929 | 0.42324 | 0.11312 | (-0.319605, 0.0810335) | (-0.5, 0.5) |
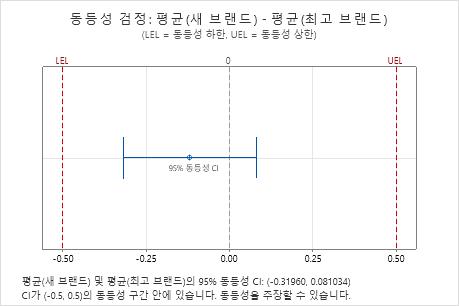
주요 결과: 95% CI, 동등성 구간
이 결과에서 95% 신뢰 구간은 동등성 하한(LEL)과 동등성 상한(UEL)에 의해 정의되는 구간 내에 완전히 포함됩니다. 따라서 검정 평균이 기준 평균과 동일하다는 결론을 내릴 수 있습니다.
참고
p-값을 사용하여 동등성 검정의 결과를 평가할 수도 있습니다. 동등성을 입증하려면 두 귀무 가설의 값이 모두 알파보다 작아야 합니다.
2단계: 데이터의 문제 확인
왜도 또는 특이치와 같은 데이터의 문제는 결과에 부정적인 영향을 미칠 수 있습니다. 데이터의 산포를 조사하여 왜도를 확인하고 잠재적 특이치를 식별하려면 그래프를 사용합니다.
데이터가 치우쳐 있는 것으로 보이는지 여부 확인
데이터가 치우쳐 있으면 대부분의 데이터가 그래프의 높은 쪽이나 낮은 쪽에 있습니다. 히스토그램이나 상자 그림에서 왜도를 식별하기가 가장 쉬운 경우가 많습니다.
오른쪽으로 치우침
왼쪽으로 치우침
예를 들어, 오른쪽으로 치우친 히스토그램은 급여 데이터를 보여줍니다. 많은 직원의 급여가 비교적 적으며 많은 급여를 받는 직원의 수는 점점 더 줄어듭니다. 왼쪽으로 치우친 히스토그램은 고장률 데이터를 보여줍니다. 초기에 고장나는 품목의 수는 적으며 나중에는 점점 더 많은 품목에 고장이 발생합니다.
심하게 치우친 데이터는 표본이 작은 경우(20보다 작은 값) 검정 결과의 유효성에 영향을 미칠 수 있습니다. 데이터가 심하게 치우쳐 있고 표본이 작은 경우 표본 크기를 늘리는 것을 고려해 보십시오.
특이치 식별
대부분의 다른 데이터에서 멀리 떨어져 있는 데이터 점인 특이치는 결과에 크게 영향을 미칠 수 있습니다. 상자 그림에서 특이치를 식별하기가 가장 쉽습니다.
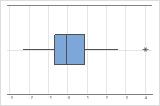
상자 그림에서 특이치는 별표(*)로 표시됩니다.
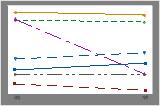
피실험자 프로파일 그림에서 다른 반응 및 동등성 검정 결과와 크게 다른 피실험자 반응을 찾습니다.
특이치의 원인을 식별해야 합니다. 모든 데이터 입력 또는 측정 오류를 수정하십시오. 특수 원인과 관련된 데이터를 제거하고 분석을 다시 실행해 보십시오. 특수 원인에 대한 자세한 내용을 확인하려면 관리도를 사용하여 우연 원인 변동과 특수 원인 변동 탐지로 이동하십시오.
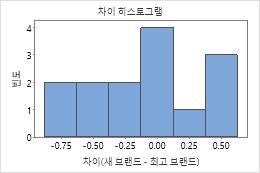
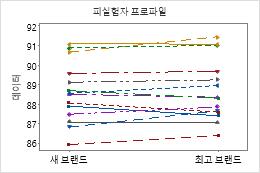
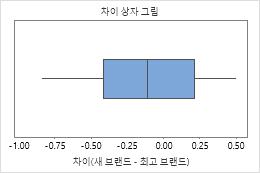
상자 그림과 히스토그램은 차이가 치우쳐 있는 것으로 보이지 않으며 특이치가 없다는 것을 보여줍니다. 피실험자 프로파일 그림은 측정값이 피실험자 간에 달라진다는 것을 보여줍니다. 그러나 각 관측치 쌍을 연결하는 선이 거의 수평입니다. 따라서 각 피실험자의 검정 및 기준 처리에 대한 값이 비슷합니다. 이 패턴은 두 솔루션의 효과가 동일하다는 것을 나타내는 통계 분석 결과와 일치합니다.