표준 편차는 산포, 즉 데이터가 평균을 중심으로 퍼져 있는 정도를 나타내는 가장 일반적인 측도입니다. 표준 편차가 클수록 데이터의 범위가 더 커집니다.
모집단의 표준 편차를 나타내는 데는 σ(시그마) 기호를 자주 사용하는 반면, 표본의 표준 편차를 사용하는 데는 s를 사용합니다. 랜덤이 아니거나 공정에 자연스럽지 못한 변동은 종종 잡음이라고 합니다.
공정의 전체 변동을 추정하기 위한 벤치마크를 설정하기 위해 표준 편차를 사용할 수 있습니다.
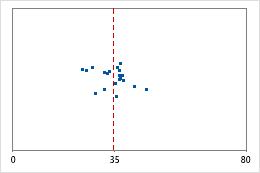
병원 1
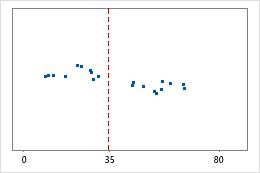
병원 2
병원 퇴원 시간
다음 예에 대해 생각해 보십시오. 관리자들이 두 개 병원의 응급실 부서에서 처치한 환자의 퇴원 시간을 추적하고자 합니다. 평균 퇴원 시간은 동일하지만(35분) 표준 편차는 유의하게 다릅니다. 병원 1의 표준 편차가 약 6입니다. 평균적으로 환자의 퇴원 시간은 평균(대시선)에서 약 6분 정도 멀어집니다. 병원 2의 표준 편차는 약 20입니다. 평균적으로 환자의 퇴원 시간은 평균(대시선)에서 약 20분 정도 멀어집니다.