1단계: 모집단 평균 차이에 대한 신뢰 구간 결정
먼저 평균 차이를 고려한 다음 신뢰 구간을 조사합니다. 평균 차이는 표본의 쌍체 관측치 간 차이의 평균입니다.
평균 차이는 모평균 차이의 추정치입니다. 평균 차이는 전체 모집단이 아니라 표본 데이터를 기반으로 하기 때문에 표본 평균 차이가 모평균 차이와 같을 가능성은 없습니다. 모평균 차이를 더 잘 추정하려면 차이의 신뢰 구간을 사용하십시오.
신뢰 구간은 쌍체 관측치의 모평균 차이가 될 수 있는 값의 범위를 제공합니다. 예를 들어, 95% 신뢰 수준은 모집단에서 100개의 랜덤 표본을 추출할 경우 약 95개의 표본이 모평균 차이가 포함된 구간을 생성할 것으로 예상된다는 것을 나타냅니다. 신뢰 구간은 결과의 실제 유의성을 평가하는 데 도움이 됩니다. 해당 상황에 실제적으로 유의한 값이 신뢰 구간에 포함되는지 여부를 확인하려면 전문 지식을 이용하십시오. 신뢰 구간이 너무 넓어서 유의하지 않은 경우에는 표본 크기를 늘려보십시오. 자세한 내용은 더 정밀한 신뢰 구간을 구하는 방법에서 확인하십시오.
쌍체 차이 추정지
| 평균 | 표준 편차 | 평균의 표준 오차 | µ_차이에 대한 95% CI |
|---|---|---|---|
| 2.200 | 3.254 | 0.728 | (0.677, 3.723) |
주요 결과: 평균 차이, 평균 차이에 대한 95% CI
이 결과에서 심박수의 모평균 차이에 대한 추정치는 2.2입니다. 모평균 차이가 0.677과 3.723 사이에 있다고 95% 확신할 수 있습니다.
2단계: 검정 결과가 통계적으로 유의한지 여부를 확인
- p-값 ≤ α: 평균 간의 차이가 통계적으로 유의함(H0 기각)
- p-값이 유의 수준보다 작거나 같으면 귀무 가설을 기각합니다. 모평균 간의 차이가 귀무 가설에서의 차이와 같지 않다는 결론을 내릴 수 있습니다. 귀무 가설에서의 차이를 지정하지 않은 경우 Minitab에서는 평균 간에 차이가 없는지 여부(귀무 가설에서의 차이 = 0)를 검정합니다. 차이가 실제로 유의한지 여부를 확인하려면 전문 지식을 활용합니다. 자세한 내용은 통계적 유의성 및 실제적 유의성에서 확인하십시오.
- p-값 > α: 평균 간의 차이가 통계적으로 유의하지 않음(H0 기각 실패)
- p-값이 유의 수준보다 크면 귀무 가설을 기각할 수 없습니다. 쌍체 관측치 간의 평균 차이가 통계적으로 유의하다는 결론을 내릴 충분한 증거가 없습니다. 검정에 실제로 유의한 차이를 탐지할 만한 충분한 검정력이 있는지 확인해야 합니다. 자세한 내용은 쌍체 t 검정에 대한 검정력 및 표본 크기에서 확인하십시오.
검정
| 귀무 가설 | H₀: μ_차이 = 0 |
|---|---|
| 대립 가설 | H₁: μ_차이 ≠ 0 |
| T-값 | P-값 |
|---|---|
| 3.02 | 0.007 |
주요 결과: p-값
이 결과에서 귀무 가설은 달리기 프로그램 전과 후 환자의 휴식기 심박수의 평균 차이가 0이라는 것입니다. p-값이 0.007로, 유의 수준 0.05보다 작기 때문에 귀무 가설을 기각하고 달리기 프로그램 전과 후 환자의 심박수에 차이가 있다는 결론을 내립니다.
3단계: 데이터의 문제 확인
왜도 및 특이치와 같은 데이터의 문제는 결과에 부정적인 영향을 미칠 수 있습니다. 왜도를 확인하고 잠재적 특이치를 식별하려면 그래프를 사용하십시오.
데이터가 치우쳐 있는 것으로 보이는지 여부를 확인하려면 데이터의 산포를 조사합니다.
데이터가 치우쳐 있으면 대부분의 데이터가 그래프의 높은 쪽이나 낮은 쪽에 위치합니다. 히스토그램이나 상자 그림에서 왜도를 탐지하기가 가장 쉬운 경우가 많습니다.
오른쪽으로 치우침
왼쪽으로 치우침
오른쪽으로 치우친 데이터의 히스토그램은 대기 시간을 보여줍니다. 대부분의 대기 시간이 비교적 짧고 몇 개의 대기 시간만 깁니다. 왼쪽으로 치우친 데이터의 히스토그램은 수명 데이터를 보여줍니다. 몇 개의 품목이 즉시 고장나고 더 많은 품목이 나중에 고장납니다.
심하게 치우친 데이터는 표본이 작은 경우(20보다 작은 값) p-값의 유효성에 영향을 미칠 수 있습니다. 데이터가 심하게 치우쳐 있고 표본이 작은 경우 표본 크기를 늘리는 것을 고려해 보십시오.
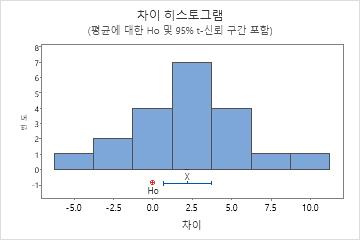
이 히스토그램에서 데이터는 심하게 치우쳐 있는 것으로 보이지 않습니다.
특이치 식별
다른 데이터 값에서 멀리 떨어져 있는 데이터 값인 특이치는 분석 결과에 크게 영향을 미칠 수 있습니다. 일반적으로 상자 그림에서 특이치를 식별하기가 가장 쉽습니다.
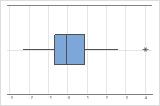
상자 그림에서는 별표(*)가 특이치를 나타냅니다.
특이치의 원인을 식별합니다. 모든 데이터 입력 오류 또는 측정 오류를 수정하십시오. 비정상적인 일회성 사건에 대한 데이터 값을 삭제해 보십시오(특수 원인이라고도 함). 그런 다음 분석을 반복하십시오. 자세한 내용은 특이치 식별에서 확인하십시오.
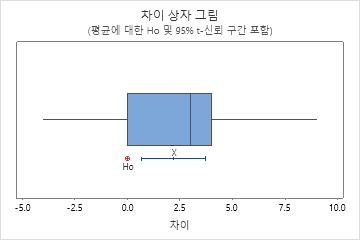
이 상자 그림에는 특이치가 없습니다.