평균
숫자 묶음의 중심을 측정하는 데 가장 일반적으로 사용되는 측도. 모든 관측치의 합을 (비결측) 관측치 수로 나눈 값입니다.
공식
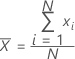
표기법
| 용어 | 설명 |
|---|---|
| xi | i번째 관측치 |
| N | 비결측 관측치 수 |
표준 편차
표본 표준 편차는 데이터 산포의 측도를 제공하며, 표본 분산의 제곱근과 같습니다.
공식
 이면 표본의 표준 편차는 다음과 같습니다.
이면 표본의 표준 편차는 다음과 같습니다.
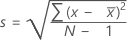
표기법
| 용어 | 설명 |
|---|---|
| x i | i번째 관측치 |
 | 관측치의 평균 |
| N | 비결측 관측치 수 |
N
Anderson-Darling 통계량(A2)
A2는 적합선(선택된 분포에 근거)과 비모수적 계단 함수(표시 점에 근거) 사이의 영역을 측정합니다. 이 통계량은 분포의 끝 부분에 더 많은 가중치를 부여한 거리 제곱입니다. Anderson-Darling 값이 작을수록 분포가 데이터를 보다 잘 적합시킵니다..
Anderson-Darling 정규성 검정은 다음과 같이 정의됩니다.
H0: 데이터가 정규 분포를 따름
H1: 데이터가 정규 분포를 따르지 않음
공식

표기법
| 용어 | 설명 |
|---|---|
| F(Yi) |  , 표준 정규 분포의 누적 분포 함수 , 표준 정규 분포의 누적 분포 함수 |
| Yi | 순서가 있는 데이터 |
Ryan-Joiner
Ryan-Joiner 검정은 데이터와 데이터의 정규 점수 사이의 상관을 나타내는 상관 계수를 제공합니다. 상관 계수가 1에 가까우면 데이터가 정규 확률도에 가깝습니다. 상관 계수가 적절한 임계값보다 작으면 정규 분포를 따른다는 귀무 가설을 기각합니다.
공식
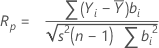
표기법
| 용어 | 설명 |
|---|---|
| Yi | 순서가 있는 관측치 |
| bi | 순서가 있는 데이터의 정규 점수 |
| s2 | 표본 분산 |
Kolmogorov-Smirnov
공식
- H0: 데이터가 정규 분포를 따름
- H1: 데이터가 정규 분포를 따르지 않음

표기법
| 용어 | 설명 |
|---|---|
| D+ | maxi {i / n – Z (i)} |
| D– | maxi {Z (i) – (i – 1) / n)} |
| Z | F(X(i)) |
| F(x) | 정규 분포의 확률분포함수 |
| X(i) | 랜덤 표본의 i번째 순서 통계량, 1 ≤ i ≤ n |
| n | 표본 크기 |
P-값
정규성 검정의 결과를 보고하기 위한 또 한 가지 양적 측도는 p-값입니다. 작은 p-값은 귀무 가설이 거짓임을 나타냅니다.
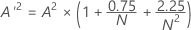
- 13 > A'2 > 0.600인 경우 p = exp(1.2937 - 5.709 * A'2 + 0.0186(A'2)2)
- 0.600 > A'2 > 0.340인 경우 p = exp(0.9177 - 4.279 * A'2 – 1.38(A'2)2)
- 0.340 > A'2 > 0.200인 경우 p = 1 – exp(–8.318 + 42.796 * A'2 – 59.938(A'2)2)
- A'2 < 0.200인 경우 p = 1 – exp(–13.436 + 101.14 * A'2 – 223.73(A'2)2)
표시점
일반적으로 적합선에 점이 가까울수록 데이터에 보다 잘 적합되는 분포입니다. Minitab에는 분포가 데이터를 얼마나 잘 적합시키는지 평가하는 데 도움이 되는 적합도 측도가 두 가지 있습니다.
공식
| 분포 | x 좌표 | y 좌표 |
|---|---|---|
| 정규 분포 | x | Φ–1 기준 |
표기법
| 용어 | 설명 |
|---|---|
| Φ–1 기준 | 표준 정규 분포의 경우 역 CDF에서 p에 대해 반환된 값 |
확률도
입력 데이터는 x-값으로 표시됩니다. Minitab에서는 분포를 가정하지 않고 발생 확률을 계산합니다. 그래프의 Y-척도는 데이터가 정규 분포를 따르는 것처럼 확률도가 직선으로 표시되는 정규 확률지에 있는 Y 척도와 유사합니다.