데이터가 정규 분포를 따르지 않는지 여부를 확인하려면 p-값을 유의 수준과 비교하십시오. 일반적으로 0.05의 유의 수준(α 또는 알파로 표시함)이 적절합니다. 0.05의 유의 수준은 데이터가 정규 분포를 따르는데 정규 분포를 따르지 않는다는 결론을 내릴 위험이 5%라는 것을 나타냅니다.
p-값 ≤ α: 데이터가 정규 분포를 따르지 않음(H0 기각)
p-값이 유의 수준보다 작거나 같으면 귀무 가설을 기각하고 데이터가 정규 분포를 따르지 않는다는 결론을 내립니다.
p-값 > α: 데이터가 정규 분포를 따르지 않는다는 결론을 내릴 수 없음(H0 기각 실패)
p-값이 유의 수준보다 크면 귀무 가설을 기각할 수 없습니다. 데이터가 정규 분포를 따르지 않는다는 결론을 내릴 충분한 증거가 없습니다.
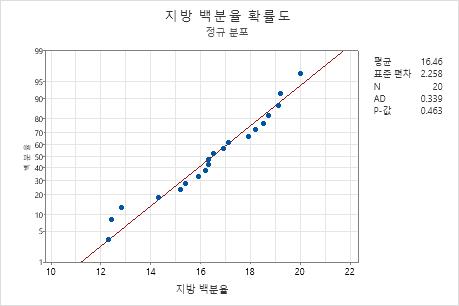
주요 결과: P-값
이 결과에서 귀무 가설은 데이터가 정규 분포를 따른다는 것입니다. p-값이 0.463으로, 유의 수준 0.05보다 크기 때문에 귀무 가설을 기각할 수 없습니다. 데이터가 정규 분포를 따르지 않는다는 결론을 내릴 수 없습니다.
2단계: 정규 분포의 적합도 시각화
정규 분포의 적합도를 시각화하려면 확률도를 조사하고 데이터 점들이 적합된 분포선을 얼마나 가깝게 따르는지 평가하십시오. 정규 분포는 직선에 가깝게 놓이는 경향이 있습니다. 치우친 데이터는 곡선을 이룹니다.
오른쪽으로 치우친 데이터
왼쪽으로 치우친 데이터
팁
Minitab에서 백분위수와 값의 차트를 보려면 적합된 분포선 위로 마우스를 가져가십시오.
이 확률도에서 데이터는 선을 따라 대략적으로 직선을 형성합니다. 정규 분포가 데이터에 양호하게 적합한 것으로 나타납니다.