포아송에 대한 적합도 검정을 해석하려면 다음 단계를 수행하십시오. 주요 결과에는 p-값과 여러 가지 그래프가 포함됩니다.
1단계: 데이터가 포아송 분포를 따르지 않는지 여부 확인
데이터가 포아송 분포를 따르지 않는지 여부를 확인하려면 p-값을 유의 수준(α)과 비교하십시오. 일반적으로 0.05의 유의 수준(α 또는 알파로 표시함)이 적절합니다. 0.05의 유의 수준은 데이터가 포아송 분포를 따르는데 포아송 분포를 따르지 않는다는 결론을 내릴 위험이 5%라는 것을 나타냅니다.
- p-값 ≤ α: 데이터가 포아송 분포를 따르지 않음(H0 기각)
- p-값이 유의 수준보다 작거나 같으면 귀무 가설을 기각하고 데이터가 포아송 분포를 따르지 않는다는 결론을 내립니다.
- p-값 > α: 데이터가 포아송 분포를 따르지 않는다는 결론을 내릴 수 없음(H0 기각 실패)
- p-값이 유의 수준보다 크면 데이터가 포아송 분포를 따르지 않는다는 결론을 내릴 충분한 증거가 없기 때문에 귀무 가설을 기각할 수 없습니다.
방법
| 빈도(관측) |
|---|
기술 통계량
| N | 평균 |
|---|---|
| 300 | 0.536667 |
결점에 대한 관측 및 기대 카운트
| 결점 | 포아송 확률 | 관측 개수 | 기대 카운트 | 카이-제곱에 대한 기여도 |
|---|---|---|---|---|
| 0 | 0.584694 | 213 | 175.408 | 8.056 |
| 1 | 0.313786 | 41 | 94.136 | 29.993 |
| 2 | 0.084199 | 18 | 25.260 | 2.086 |
| >=3 | 0.017321 | 28 | 5.196 | 100.072 |
카이-제곱 검정
| 귀무 가설 | H₀: 데이터가 포아송 분포를 따름 |
|---|---|
| 대립 가설 | H₁: 데이터가 포아송 분포를 따르지 않음 |
| DF | 카이-제곱 | P-값 |
|---|---|---|
| 2 | 140.208 | 0.000 |
주요 결과: P-값
이 결과에서 귀무 가설은 데이터가 포아송 분포를 따른다는 것입니다. p-값이 0.000으로, 0.05보다 작기 때문에 귀무 가설을 기각합니다. 데이터가 포아송 분포를 따르지 않는다는 결론을 내릴 수 있습니다.
2단계: 각 범주의 관측값과 기대값 간의 차이 조사
각 범주에 대해 관측값의 수가 기대값의 수와 다른지 여부를 확인하려면 관측값과 기대값에 대한 차트를 사용합니다. 관측값과 기대값 간의 차이가 크면 데이터가 포아송 분포를 따르지 않는다는 것을 나타냅니다.
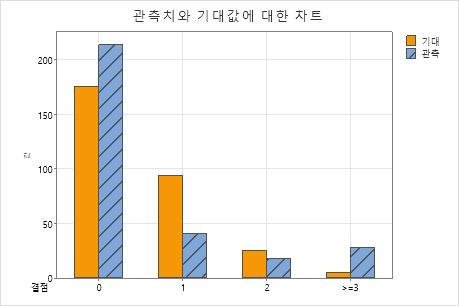
이 막대 차트는 결점 0개, 결점 1개 및 결점 4개 이상에 대한 관측값이 기대값과 다르다는 것을 보여줍니다. 따라서 막대 차트에서 p-값이 나타내는 것, 즉 데이터가 포아송 분포를 따르지 않는다는 것을 시각적으로 확인할 수 있습니다.