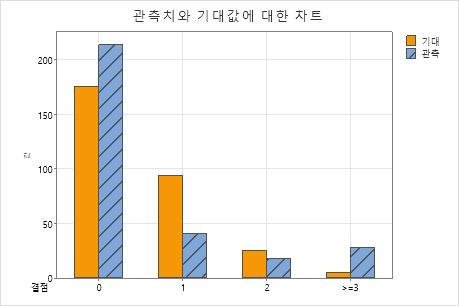
한 가전제품 회사의 품질 엔지니어가 텔레비전 수상기당 결점 수가 포아송 분포를 따르는지 여부를 확인하려고 합니다. 엔지니어는 텔레비전 300대를 랜덤하게 선택하여 텔레비전당 결점 수를 기록합니다.
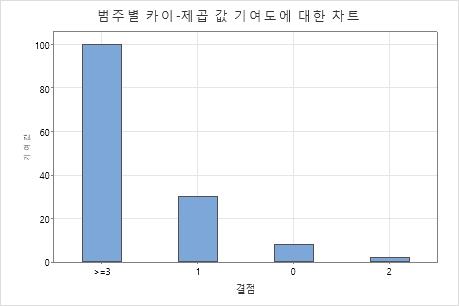
귀무 가설은 데이터가 포아송 분포를 따른다는 것입니다. p-값이 0.000으로, 유의 수준 0.05보다 작기 때문에 엔지니어는 귀무 가설을 기각하고 데이터가 포아송 분포를 따르지 않는다는 결론을 내립니다. 그래프는 범주 1과 3에 대해 관측값과 기대값의 차이가 크고, 범주 3의 카이-제곱 통계량에 대한 기여도가 가장 높다는 것을 보여줍니다.
이제 support.minitab.com을 떠나게 됩니다."
계속하려면 계속을 클릭하세요 :
 3에 대해 관측값과 기대값의 차이가 크고, 범주 3의 카이-제곱 통계량에 대한 기여도가 가장 높다는 것을 보여줍니다.
3에 대해 관측값과 기대값의 차이가 크고, 범주 3의 카이-제곱 통계량에 대한 기여도가 가장 높다는 것을 보여줍니다.