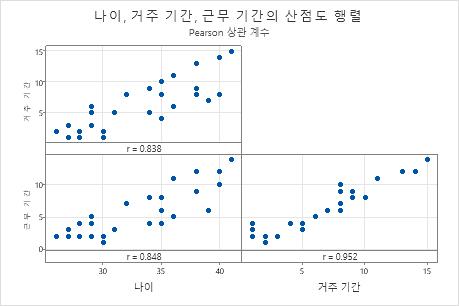
Pearson 상관 계수
상관 행렬은 각 변수 쌍의 선형 관계 정도를 측정하는 상관 계수 값을 표시합니다. 상관 계수 값의 범위는 -1과 +1 사이입니다. 두 변수가 함께 증가하거나 감소하는 경향이 있으면 상관 계수 값이 양수입니다. 변수 하나가 감소할 때 다른 변수가 증가하는 경우 상관 계수 값은 음수입니다.
해석
상관 행렬을 사용하여 두 변수의 관계 강도와 방향을 확인할 수 있습니다. 상관 계수 값이 큰 양수면 변수가 동일한 특성을 측정함을 의미합니다. 항목들이 긴밀하게 상관되어 있지 않으면 서로 다른 특성을 측정하거나 명확하게 정의되지 않을 수도 있습니다.
상관계수
| 나이 | 거주 기간 | 근무 기간 | 저축 | 부채 | |
|---|---|---|---|---|---|
| 거주 기간 | 0.838 | ||||
| 근무 기간 | 0.848 | 0.952 | |||
| 저축 | 0.552 | 0.570 | 0.539 | ||
| 부채 | 0.032 | 0.186 | 0.247 | -0.393 | |
| 신용카드 수 | -0.130 | 0.053 | 0.023 | -0.410 | 0.474 |
- 거주와 나이, 0.838
- 고용과 나이, 0.848
- 고용과 거주, 0.952
- 부채와 저축, −0.393
- 신용카드와 나이, −0.130
- 신용카드와 저축, −0.410
Spearman 상관 계수
두 계량형 변수 또는 순서형 변수 간 단순 관계의 강도와 방향을 조사하려면 Spearman 상관 계수를 사용합니다. 단순 관계에서 두 변수는 동일한 상대적인 방향으로 이동하는 경향이 있지만 반드시 일정한 비율로 변화하는 것은 아닙니다. Spearman 상관을 계산하기 위해 Minitab에서는 원시 데이터에 순위를 매깁니다. 그런 다음 순위 매긴 데이터에 대해 상관 계수를 계산합니다.
- 강도
-
상관 계수 값의 범위는 −1부터 +1까지입니다. 계수의 절대값이 클수록 변수 사이에 강한 관계가 있습니다.
Spearman 상관의 경우 절대값 1은 순위가 매겨진 데이터가 완전히 선형임을 나타냅니다. 예를 들어 Spearman 상관 계수가 −1이면 변수 A의 가장 큰 값이 변수 B의 가장 작은 값과 연관되어 있고, 변수 A의 두 번째로 큰 값이 변수 B의 두 번째로 큰 값과 연관되어 있으며, 이런 식으로 계속된다는 것을 의미합니다.
- 방향
-
계수의 부호는 관계의 방향을 나타냅니다. 두 변수가 함께 증가하거나 감소하는 경향이 있으면 계수가 양수이며, 상관을 나타내는 선이 위쪽 방향으로 기울어집니다. 한 변수가 증가할 때 다른 변수는 감소하는 경향이 있으면 계수는 음수이며, 상관을 나타내는 선이 아래쪽 방향으로 기울어집니다.
다음 그림은 변수 사이 관계의 강도 및 방향의 여러 패턴을 보여주기 위해 특정한 Spearman 상관 계수 값을 갖는 데이터를 표시합니다.

아무런 관계도 없음: Spearman 로 = 0
점들이 그림에 랜덤하게 위치합니다. 이는 변수 사이에 아무런 관계도 없다는 것을 나타냅니다.
강한 양의 관계: Spearman 로 = 0.948
점들이 선에 가깝게 위치합니다 이는 변수 사이에 강한 관계가 있다는 것을 나타냅니다. 변수가 동시에 증가하기 때문에 양의 관계가 있습니다.

강한 음의 관계: Spearman 로 = -1.0
점들이 선에 가깝게 위치합니다 이는 변수 사이에 강한 관계가 있다는 것을 나타냅니다. 한 변수가 증가하면 다른 변수도 감소하기 때문에 음의 관계가 있습니다.
상관 계수만을 기초로, 한 변수의 변화가 다른 변수의 변화를 유발한다는 결론을 내리는 것은 적절하지 않습니다. 적절히 통제된 실험에서만 인과 관계를 확인할 수 있습니다.
해석
상관계수
| 나이 | 거주 기간 | 근무 기간 | 저축 | 부채 | |
|---|---|---|---|---|---|
| 거주 기간 | 0.824 | ||||
| 근무 기간 | 0.830 | 0.912 | |||
| 저축 | 0.570 | 0.571 | 0.496 | ||
| 부채 | -0.198 | -0.142 | -0.056 | -0.605 | |
| 신용카드 수 | -0.179 | 0.069 | 0.036 | -0.480 | 0.353 |
쌍별 비교 Spearman 상관 계수
| 표본 1 | 표본 2 | N | 상관 계수 | ρ에 대한 95% CI | P-값 |
|---|---|---|---|---|---|
| 거주 기간 | 나이 | 30 | 0.824 | (0.624, 0.922) | 0.000 |
| 근무 기간 | 나이 | 30 | 0.830 | (0.636, 0.926) | 0.000 |
| 저축 | 나이 | 30 | 0.570 | (0.236, 0.783) | 0.001 |
| 부채 | 나이 | 30 | -0.198 | (-0.524, 0.178) | 0.293 |
| 신용카드 수 | 나이 | 30 | -0.179 | (-0.508, 0.197) | 0.345 |
| 근무 기간 | 거주 기간 | 30 | 0.912 | (0.798, 0.963) | 0.000 |
| 저축 | 거주 기간 | 30 | 0.571 | (0.237, 0.784) | 0.001 |
| 부채 | 거주 기간 | 30 | -0.142 | (-0.479, 0.232) | 0.454 |
| 신용카드 수 | 거주 기간 | 30 | 0.069 | (-0.300, 0.419) | 0.719 |
| 저축 | 근무 기간 | 30 | 0.496 | (0.144, 0.737) | 0.005 |
| 부채 | 근무 기간 | 30 | -0.056 | (-0.408, 0.311) | 0.768 |
| 신용카드 수 | 근무 기간 | 30 | 0.036 | (-0.328, 0.392) | 0.849 |
| 부채 | 저축 | 30 | -0.605 | (-0.804, -0.283) | 0.000 |
| 신용카드 수 | 저축 | 30 | -0.480 | (-0.726, -0.124) | 0.007 |
| 신용카드 수 | 부채 | 30 | 0.353 | (-0.020, 0.639) | 0.056 |
이 결과에서 거주와 나이 간 Spearman 상관 계수는 0.824로, 변수 사이에 양의 관계가 있음을 나타냅니다. 로에 대한 신뢰 구간은 0.624에서 0.922까지입니다. p 값은 0.000으로, α = 0.05 수준에서 관계가 통계적으로 유의함을 의미합니다.
부채와 저축 사이의 Spearman 상관 계수는 -0.605이고, 신용 카드와 저축 사이의 계수는 -0.480입니다. 이런 변수 사이에는 음의 관계가 있어 부채와 신용 카드가 증가할수록 저축이 감소함을 나타냅니다.
사용된 행
사용된 행 수는 방법 표에 표시됩니다. 비결측값을 포함한 행 수가 표시됩니다.
비결측값이 있는 경우 사용된 행 수가 신뢰 구간 계산에 사용되는 실제 표본 크기와 같지 않습니다.
상관 계수 신뢰 구간
신뢰 구간은 상관 계수가 될 수 있는 값의 범위를 제공합니다. 표본이 랜덤이기 때문에 모집단의 두 표본에서 동일한 신뢰 구간이 생성될 가능성은 없습니다. 하지만 표본 추출을 여러 번 반복하면 일정한 백분율의 신뢰 구간이나 한계에 알 수 없는 상관 계수가 포함됩니다. 상관 계수를 포함하는 이러한 신뢰 구간 또는 한계의 백분율이 해당 구간의 신뢰 수준입니다.
예를 들어 95% 신뢰 수준은 모집단에서 100개의 랜덤 표본을 추출할 경우 약 95개의 표본에서 상관 계수가 포함된 구간을 생성할 것으로 예상됨을 의미합니다.
상한은 모집단 차이가 더 작을 가능성이 높은 값을 정의합니다. 하한은 모집단 차이가 더 클 가능성이 높은 값을 정의합니다.
Pearson 상관 계수의 신뢰 구간은 기초를 이루는 이변량 분포의 정규성에 민감합니다. 데이터가 정규성을 벗어나는 경우 표본 크기에 관계 없이 신뢰 구간이 부정확할 수 있습니다.
Spearman 상관 계수의 신뢰 구간은 순위 기반이며, 기초를 이루는 이변량 분포 가정에 덜 민감합니다.
해석
신뢰 구간은 결과의 실제 유의성을 평가하는 데 도움이 됩니다. 해당 상황에 실제적으로 유의한 값이 신뢰 구간에 포함되는지 여부를 확인하려면 전문 지식을 이용하십시오. 신뢰 구간이 너무 넓어서 유의하지 않은 경우에는 표본 크기를 늘려보십시오. 자세한 내용은 더 정밀한 신뢰 구간을 구하는 방법에서 확인하십시오.
쌍별 비교 Pearson 상관 계수
| 표본 1 | 표본 2 | N | 상관 계수 | ρ에 대한 95% CI | P-값 |
|---|---|---|---|---|---|
| 거주 기간 | 나이 | 30 | 0.838 | (0.684, 0.920) | 0.000 |
| 근무 기간 | 나이 | 30 | 0.848 | (0.702, 0.926) | 0.000 |
| 저축 | 나이 | 30 | 0.552 | (0.240, 0.761) | 0.002 |
| 부채 | 나이 | 30 | 0.032 | (-0.332, 0.388) | 0.865 |
| 신용카드 수 | 나이 | 30 | -0.130 | (-0.468, 0.242) | 0.494 |
| 근무 기간 | 거주 기간 | 30 | 0.952 | (0.901, 0.977) | 0.000 |
| 저축 | 거주 기간 | 30 | 0.570 | (0.264, 0.772) | 0.001 |
| 부채 | 거주 기간 | 30 | 0.186 | (-0.187, 0.512) | 0.326 |
| 신용카드 수 | 거주 기간 | 30 | 0.053 | (-0.313, 0.406) | 0.779 |
| 저축 | 근무 기간 | 30 | 0.539 | (0.222, 0.753) | 0.002 |
| 부채 | 근무 기간 | 30 | 0.247 | (-0.125, 0.557) | 0.189 |
| 신용카드 수 | 근무 기간 | 30 | 0.023 | (-0.340, 0.380) | 0.906 |
| 부채 | 저축 | 30 | -0.393 | (-0.660, -0.038) | 0.032 |
| 신용카드 수 | 저축 | 30 | -0.410 | (-0.671, -0.059) | 0.024 |
| 신용카드 수 | 부채 | 30 | 0.474 | (0.138, 0.713) | 0.008 |
이 결과에서 거주와 나이 사이에는 양의 선형 상관 관계가 있으며, 상관 계수는 0.838입니다. 따라서 상관 계수가 0.684와 0.920 사이에 있다고 95% 확신할 수 있습니다. 일반적으로 상관 관계가 더 강할수록 신뢰 구간이 좁습니다. 예를 들어 신용 카드와 나이의 상관 관계는 약하고 95% 신뢰 구간 범위는 -0.468에서 0.242까지입니다.
p-값
p-값은 귀무 가설에 반하는 증거를 측정하는 확률입니다. p-값이 작을수록 귀무 가설에 반하는 더 강력한 증거가 됩니다.
해석
p-값을 사용해 상관 관계가 통계적으로 유의한지 확인합니다.
- p-값 ≤ α: 상관 계수가 통계적으로 유의함(H0 기각)
- p-값이 유의 수준보다 작거나 같으면 귀무 가설을 기각합니다. 상관 계수가 통계적으로 유의하다는 결론을 내릴 수 있습니다. 차이가 실제로 유의한지 여부를 확인하려면 전문 지식을 활용합니다. 자세한 내용은 통계적 유의성 및 실제적 유의성에서 확인하십시오.
- p-값 > α: 상관 계수가 통계적으로 유의하지 않음(H0 기각 실패)
- p-값이 유의 수준보다 크면 귀무 가설을 기각할 수 없습니다. 상관 계수가 통계적으로 유의하다는 결론을 내릴 충분한 증거가 없습니다.
Pearson 상관 계수와 Spearman 상관 계수의 p-값 절차는 모두 정규성 이탈에 대해 로버스트합니다. p-값은 일반적으로 n이 25 이상인 경우 표본의 모집단에 관계 없이 정확합니다.
쌍별 비교 Pearson 상관 계수
| 표본 1 | 표본 2 | N | 상관 계수 | ρ에 대한 95% CI | P-값 |
|---|---|---|---|---|---|
| 거주 기간 | 나이 | 30 | 0.838 | (0.684, 0.920) | 0.000 |
| 근무 기간 | 나이 | 30 | 0.848 | (0.702, 0.926) | 0.000 |
| 저축 | 나이 | 30 | 0.552 | (0.240, 0.761) | 0.002 |
| 부채 | 나이 | 30 | 0.032 | (-0.332, 0.388) | 0.865 |
| 신용카드 수 | 나이 | 30 | -0.130 | (-0.468, 0.242) | 0.494 |
| 근무 기간 | 거주 기간 | 30 | 0.952 | (0.901, 0.977) | 0.000 |
| 저축 | 거주 기간 | 30 | 0.570 | (0.264, 0.772) | 0.001 |
| 부채 | 거주 기간 | 30 | 0.186 | (-0.187, 0.512) | 0.326 |
| 신용카드 수 | 거주 기간 | 30 | 0.053 | (-0.313, 0.406) | 0.779 |
| 저축 | 근무 기간 | 30 | 0.539 | (0.222, 0.753) | 0.002 |
| 부채 | 근무 기간 | 30 | 0.247 | (-0.125, 0.557) | 0.189 |
| 신용카드 수 | 근무 기간 | 30 | 0.023 | (-0.340, 0.380) | 0.906 |
| 부채 | 저축 | 30 | -0.393 | (-0.660, -0.038) | 0.032 |
| 신용카드 수 | 저축 | 30 | -0.410 | (-0.671, -0.059) | 0.024 |
| 신용카드 수 | 부채 | 30 | 0.474 | (0.138, 0.713) | 0.008 |
이 결과에는 유의 수준 0.05보다 작은 p-값이 많아 Pearson 상관 계수가 통계적으로 유의함을 나타냅니다.
참고
극단적인 데이터 점으로 인해 p-값이 작지만 신뢰 구간이 매우 넓은 경우가 있습니다. 예를 들어 신용카드와 부채의 경우 95% 신뢰 구간이 매우 넓지만 p-값은 작습니다. 산점 행렬도를 살펴보면 극단적인 데이터 점을 볼 수 있습니다.
산점도 행렬
산점도 행렬은 개별 산점도를 배열한 것입니다. 행렬의 각 산점도는 x와 y축의 항목 쌍에 대한 점수를 그래프로 표시합니다.
해석
산점도 행렬은 변수의 각 조합 사이의 관계를 시각적으로 측정하는 데 사용합니다. 관계는 선형 또는 단순이거나 둘 다 아닐 수 있습니다. 결과에 큰 영향을 미칠 수 있는 특이치를 찾는 데도 산점도 행렬을 사용합니다. 관계 유형에 대한 자세한 내용을 확인하려면 선형, 비선형 및 단조 관계으로 이동하십시오.
이 산점도 행렬은 모든 항목 쌍이 양의 선형 관계를 가진다는 것을 나타냅니다.