이 항목의 내용
혼합 효과 모형의 관리 수준에서의 비교를 위한 Dunnett 방법

관리 수준에서의 다중 비교의 경우 Minitab에서는 단측 구간도 계산합니다.
- 상한
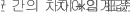
- 하한

적합 평균 및 차이의 표준 오차를 계산하는 방법에 대한 자세한 내용은 혼합 효과 모형 적합의 적합 평균에 대한 방법 및 공식에서 확인하십시오.
참고
검정 통계량, 수정된 p-값, 개별 신뢰 수준 및 그룹화 정보 표에 대한 계산은 일반 선형 모형에 대한 계산과 일치합니다. 자세한 내용은 일반 선형 모형의 비교에 대한 방법 및 공식에서 확인하십시오.
임계값

- Dunnett, C. W. (January 01, 1955). A multiple comparison procedure for comparing several treatments with a control. Journal of the American Statistical Association, 50, 1096-1121.
- J.C. Hsu (1996). Multiple Comparisons: Theory and methods. Chapman & Hall.
| 용어 | 설명 |
|---|---|
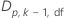 | Dunnett이 제안하는 다음과 같은 분포의 상위  백분위수, 비교: 백분위수, 비교:  , 자유도: df , 자유도: df |
| α | 제1종 오류를 범할 동시 확률 |
| k | 고정 효과 항 또는 랜덤 항의 수준 수 |
| df | 자유도 |
자유도는 고정 효과 항에 대한 비교인지, 랜덤 항에 대한 비교인 지에 따라 다릅니다.
자유도(df)
고정 효과 항의 경우 자유도(df)는 해당하는 고정 효과 항을 검정하기 위한 자유도와 같습니다. 랜덤 항의 경우 자유도는 Satterthwaites 근사 방법을 사용합니다.
자유도 계산에 대한 자세한 내용은 혼합 효과 모형 적합의 고정 효과 검정에 대한 방법 및 공식에서 확인하십시오.
혼합 효과 모형의 관리 수준에서의 비교를 위한 Fisher 방법

관리 수준에서의 다중 비교의 경우 Minitab에서는 단측 구간도 계산합니다.
- 상한
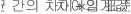
- 하한

적합 평균 및 차이의 표준 오차를 계산하는 방법에 대한 자세한 내용은 혼합 효과 모형 적합의 적합 평균에 대한 방법 및 공식에서 확인하십시오.
참고
검정 통계량, 수정된 p-값, 개별 신뢰 수준 및 그룹화 정보 표에 대한 계산은 일반 선형 모형에 대한 계산과 일치합니다. 자세한 내용은 일반 선형 모형의 비교에 대한 방법 및 공식에서 확인하십시오.
임계값
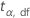
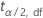
| 용어 | 설명 |
|---|---|
 | 자유도가 df인 스튜던트화 t-분포의 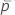 사분위수 사분위수 |
| α | 제1종 오류를 범할 개별 확률 |
| df | 자유도 |
자유도는 고정 효과 항에 대한 비교인지, 랜덤 항에 대한 비교인 지에 따라 다릅니다.
자유도(df)
고정 효과 항의 경우 자유도(df)는 해당하는 고정 효과 항을 검정하기 위한 자유도와 같습니다. 랜덤 항의 경우 자유도는 Satterthwaites 근사 방법을 사용합니다.
자유도 계산에 대한 자세한 내용은 혼합 효과 모형 적합의 고정 효과 검정에 대한 방법 및 공식에서 확인하십시오.
혼합 효과 모형의 관리 수준에서의 비교를 위한 Bonferroni 방법

관리 수준에서의 다중 비교의 경우 Minitab에서는 단측 구간도 계산합니다.
- 상한
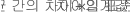
- 하한

적합 평균 및 차이의 표준 오차를 계산하는 방법에 대한 자세한 내용은 혼합 효과 모형 적합의 적합 평균에 대한 방법 및 공식에서 확인하십시오.
참고
검정 통계량, 수정된 p-값, 개별 신뢰 수준 및 그룹화 정보 표에 대한 계산은 일반 선형 모형에 대한 계산과 일치합니다. 자세한 내용은 일반 선형 모형의 비교에 대한 방법 및 공식에서 확인하십시오.
임계값


| 용어 | 설명 |
|---|---|
 | 자유도가 df인 스튜던트의 t-분포의 상위 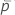 백분위수 백분위수 |
| α | 제1종 오류를 범할 동시 확률 |
| c |  |
| k | 고정 효과 항 또는 랜덤 항의 수준 수 |
| df | 자유도 |
자유도는 고정 효과 항에 대한 비교인지, 랜덤 항에 대한 비교인 지에 따라 다릅니다.
자유도(df)
고정 효과 항의 경우 자유도(df)는 해당하는 고정 효과 항을 검정하기 위한 자유도와 같습니다. 랜덤 항의 경우 자유도는 Satterthwaites 근사 방법을 사용합니다.
자유도 계산에 대한 자세한 내용은 혼합 효과 모형 적합의 고정 효과 검정에 대한 방법 및 공식에서 확인하십시오.
혼합 효과 모형의 관리 수준에서의 비교를 위한 Sidak 방법

관리 수준에서의 다중 비교의 경우 Minitab에서는 단측 구간도 계산합니다.
- 상한
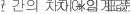
- 하한

적합 평균 및 차이의 표준 오차를 계산하는 방법에 대한 자세한 내용은 혼합 효과 모형 적합의 적합 평균에 대한 방법 및 공식에서 확인하십시오.
참고
검정 통계량, 수정된 p-값, 개별 신뢰 수준 및 그룹화 정보 표에 대한 계산은 일반 선형 모형에 대한 계산과 일치합니다. 자세한 내용은 일반 선형 모형의 비교에 대한 방법 및 공식에서 확인하십시오.
임계값
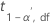
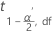
| 용어 | 설명 |
|---|---|
 | 자유도가 df인 스튜던트의 t-분포의 상위 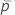 백분위수 백분위수 |
 | 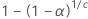 |
| α | 제1종 오류를 범할 동시 확률 |
| c |  |
| k | 고정 효과 항 또는 랜덤 항의 수준 수 |
| df | 자유도 |
자유도는 고정 효과 항에 대한 비교인지, 랜덤 항에 대한 비교인 지에 따라 다릅니다.
자유도(df)
고정 효과 항의 경우 자유도(df)는 해당하는 고정 효과 항을 검정하기 위한 자유도와 같습니다. 랜덤 항의 경우 자유도는 Satterthwaites 근사 방법을 사용합니다.
자유도 계산에 대한 자세한 내용은 혼합 효과 모형 적합의 고정 효과 검정에 대한 방법 및 공식에서 확인하십시오.