이 항목의 내용
Minitab에서는 시계열을 분석할 수 있는 여러 분석을 제공합니다. 이러한 분석에는 단순 예측 및 평활 방법, 상관 분석 방법 및 ARIMA 모형화가 있습니다. 상관 분석은 ARIMA 모형화와 별개로 수행될 수 있지만 Minitab에서는 상관 방법을 ARIMA 모형화의 일부로 사용합니다.
단순 예측 및 평활 방법
단순 예측 및 평활 방법에서는 일반적으로 데이터의 시계열도에서 쉽게 관측할 수 있는 시계열의 성분을 모형화합니다. 이 방법은 데이터를 성분 요소로 분해한 다음, 성분의 추정치를 미래로 확장하여 예측값을 구합니다. 추세 분석 및 분해는 정적 방법이고, 이동 평균[MA], 단일/이중 지수 평활 및 Winters의 방법은 동적 방법입니다. 정적 방법은 패턴이 시간에 따라 바뀌지 않는 반면, 동적 방법은 패턴이 시간에 따라 바뀌고 추정치는 인접한 값을 사용하여 업데이트됩니다.
두 가지 방법을 함께 사용할 수도 있습니다. 즉, 하나의 성분을 모형화하기 위해 정적 방법을 선택하고 다른 성분을 모형화하기 위해 동적 방법을 선택할 수 있습니다. 예를 들어, 추세 분석을 사용하여 정적 추세 성분을 적합시키고 Winters의 방법을 사용하여 잔차의 계절 성분을 동적으로 모형화할 수 있습니다. 또는 분해를 사용하여 정적 계절 모형을 적합시키고 이중 지수 평활을 사용하여 잔차의 추세 성분을 동적으로 모형화할 수 있습니다. 추세 분석을 통해 제공되는 추세 모형을 보다 다양하게 선택할 수 있도록 추세 분석과 분해를 함께 적용할 수도 있습니다. 결합 방법의 단점은 예측값에 대한 신뢰 구간이 올바르지 않다는 것입니다.
다음 표에서는 각 방법에 대해 설명하고 일반적인 데이터의 적합치 및 예측값 그래프를 보여줍니다.
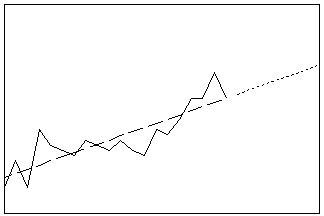
추세 분석
일반적인 추세 모형을 시계열 데이터에 적합시킵니다. 선형, 2차, 지수 성장/감소 및 S-곡선 모형 중에서 하나를 선택할 수 있습니다. 시계열에 계절 성분이 없는 경우에는 추세 분석 절차를 사용하여 추세를 적합시킵니다.
- 길이: 장기
- 프로파일: 추세선의 연장
분해
시계열을 선형 추세 성분, 계절 성분 및 오차로 분리합니다. 이 때 계절 성분과 추세 성분을 더할지(가법) 또는 곱할지(승법) 선택합니다. 시계열에 계절 성분이 있거나 성분 요소의 특성을 조사하려는 경우 이 절차를 사용하여 예측합니다.
- 길이: 장기
- 프로파일: 계절 패턴이 있는 추세
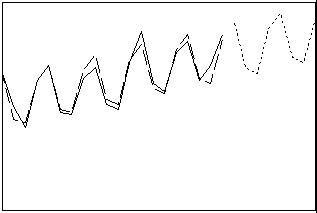
이동 평균[MA]
시계열의 연속적인 관측치를 평균화하여 데이터를 평활합니다. 이 절차는 데이터에 추세 성분이 없는 경우 사용할 수 있습니다. 계절 성분이 있는 경우 이동 평균[MA] 길이를 계절 주기 길이와 같게 설정하십시오.
- 길이: 단기
- 프로파일: 직선
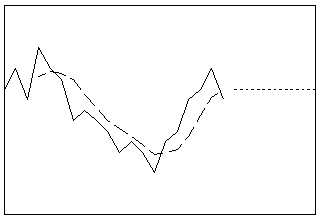
단일 지수 평활
한 단계 앞의 최적 ARIMA(0,1,1) 예측 공식을 사용하여 데이터를 평활합니다. 이 방법은 추세 또는 계절 성분이 없는 경우에 가장 좋습니다. 이동 평균[MA] 모형에서는 수준이 단일 동적 성분입니다.
- 길이: 단기
- 프로파일: 직선
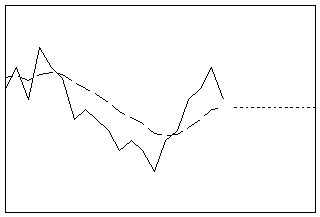
이중 지수 평활
한 단계 앞의 최적 ARIMA (0,2,2) 예측 공식을 사용하여 데이터를 평활합니다. 이 방법은 추세가 있는 경우 좋지만, 일반적인 평활 방법의 역할을 할 수도 있습니다. 이중 지수 평활에서는 수준과 추세, 두 가지 성분에 대한 동적 추정치를 계산합니다.
- 길이: 단기
- 프로파일: 마지막 추세 성분 추정치와 기울기가 같은 직선
Winters의 방법
Holt-Winters 지수 평활 방법으로 데이터를 평활합니다. 이 방법은 추세와 계절성이 존재하고 이 두 성분이 가법적이거나 승법적일 때 사용합니다. Winters의 방법에서는 수준, 추세, 계절 등 세 가지 성분에 대한 동적 추정치를 계산합니다.
- 길이: 단기 ~ 중기
- 프로파일: 계절 패턴이 있는 추세
상관 분석 및 ARIMA 모형화
ARIMA(자기 회귀 누적 이동 평균) 모형화에서도 데이터의 패턴을 사용하지만 이 패턴은 데이터 그래프에서 쉽게 볼 수 없습니다. 대신 ARIMA 모형화에서는 사용 가능한 모형을 쉽게 식별할 수 있도록 차이와 자기상관함수 및 편자기상관함수를 사용합니다.
ARIMA 모형화는 추세 또는 계절 성분이 있는지 여부에 상관없이 여러 가지 시계열을 모형화하고 예측값을 구하는 데 사용될 수 있습니다. 예측 프로파일은 적합되는 모형에 따라 다릅니다. ARIMA 모형화의 장점은 단순 예측 및 평활 방법에 비해 데이터를 적합시키기가 쉽다는 것입니다. 그러나 모형을 식별하고 적합시키는 데 많은 시간이 걸릴 수 있으며 ARIMA 모형화는 쉽게 자동화되지 않습니다.
- 차이
- 시계열의 데이터 값 간 차이를 계산하고 저장합니다. ARIMA 모형을 적합시키려고 하는데 데이터에 추세 또는 계절 성분이 있는 경우 데이터의 차이를 계산하는 것은 올바른 ARIMA 모형을 평가하는 데 일반적인 단계입니다. 차이 계산은 상관 관계 구조를 단순화하여 숨겨진 패턴을 드러내는 데 사용됩니다.
- 시차
- 시계열의 시차를 계산하고 저장합니다. 시계열 시차를 지정할 경우 Minitab에서는 열 아래로 원래 값을 이동하고 열의 맨 위에 결측값을 삽입합니다. 삽입되는 결측값 수는 시차 길이에 따라 다릅니다.
- 자기 상관
- 시계열의 자기 상관을 계산하고 그래프를 생성합니다. 자기 상관은 k 시간 단위로 구분된 시계열의 관측치 간 상관입니다. 자기 상관 그림을 자기상관함수(ACF)라고 합니다. ACF를 확인하면 ARIMA 모형에 포함할 항을 쉽게 선택할 수 있습니다.
- 편 자기 상관
- 시계열의 편 자기 상관을 계산하고 그래프를 생성합니다. 편 자기 상관은 자기 상관과 마찬가지로 정렬된 시계열 데이터 쌍 사이의 상관입니다. 또한 편 자기 상관은 회귀 분석의 편상관과 마찬가지로 설명되는 다른 항과의 관계 정도를 측정합니다. 시차 k에서의 편 자기 상관은 자기 회귀 모형에서 시간 t의 잔차와 자기 회귀 모형에서 모든 중간 시차에 대한 항이 있는 시차 k의 관측치 간 상관입니다. 편 자기 상관 그림을 편 자기 상관 함수(PACF)라고 합니다. PACF를 확인하면 ARIMA 모형에 포함할 항을 쉽게 선택할 수 있습니다.
- 교차 상관
- 두 시계열 사이 교차 상관을 계산하고 그래프를 생성합니다.
- ARIMA
- 시계열에 Box-Jenkins ARIMA 모형을 적합시킵니다. ARIMA에서 "자기 회귀", "누적", "이동 평균[MA]"은 ARIMA 모형을 계산하는 과정에서 랜덤한 잡음만 남을 때까지 수행된 필터링 단계를 나타냅니다. ARIMA를 사용하여 시계열 동작을 모형화하고 예측값을 생성할 수 있습니다.