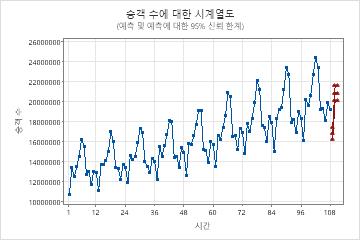
한 분석가가 108개월 동안 항공사 승객 수에 대한 데이터를 수집했습니다. 분석가는 ARIMA 모델을 사용하여 데이터에 대한 예측을 생성하려고 합니다. 분석가는 이전에 데이터의 시계열 플롯을 조사하고 계절주기의 변동이 시간이 지남에 따라 증가한다는 것을 관찰했습니다. 분석가는 데이터의 자연스러운 로그 변환이 적절하다고 결론지었습니다. 변환 후 분석가는 변환된 데이터의 시계열 플롯과 변환된 데이터의 ACF(자기 상관 함수) 플롯을 조사했습니다. 두 플롯 모두 모델의 시작점은 비계절적 차이 보관의 순서에 대해 1을, 계절 차이 보관의 순서에 대해 1을 선택하는 것임을 제안합니다. 분석가는 향후 3개월 동안 예측을 요청합니다.
모델 선택 테이블은 AICc에 의해 순서대로 검색에서 모델의 순위를 매깁니다. ARIMA(0, 1, 1)(1, 1, 0) 모델에는 AICc가 가장 적습니다. 다음 ARIMA 결과는 ARIMA(0, 1, 1)(1, 1, 0) 모델에 대한 것입니다.
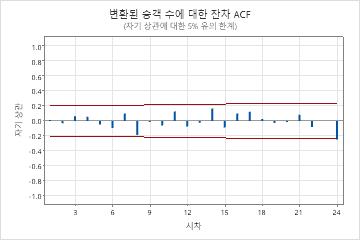
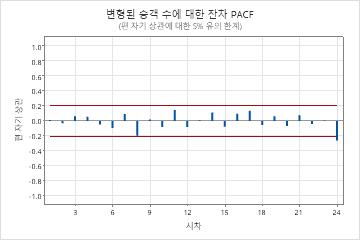
매개변수 테이블의 p-값은 모형 항이 0.05 수준에서 유의하다는 것을 보여줍니다. 분석가는 계수가 모델에 속한다는 결론을 내립니다. 수정된 박스-피어스(Ljung-Box) 통계에 대한 p-값은 모두 0.05 레벨에서 중요하지 않습니다. 잔차의 ACF 및 잔차의 PACF는 지연(24)에서 스파이크를 나타낸다. 높은 지연 숫자에서 큰 스파이크는 일반적으로 거짓 긍정이고 테스트 통계는 모두 중요하지 않기 때문에 분석가는 모형이 잔차가 독립적이라는 가정을 충족한다는 결론을 내립니다. 분석가는 예측을 검토하는 것이 합리적이라고 결론지었습니다.
* 경고 * 상수 항을 포함하지 않는 추정 불가능한 ARIMA(p, d, q)(P, D, Q) 모형: (2, 1, 1)(1, 1, 1)
방법
계절 기간
12
최상의 모형에 대한 기준
최소 AICc
Box-Cox 변환
사용자 지정 λ
0
변환된 계열 = ln(승객 수)
사용된 행
108
사용되지 않은 행
0
모형 선택
모델(d = 1, D = 1)
로그 우도
AICc
AIC
BIC
p = 0, q = 1, P = 1, Q = 0*
243.477
-480.690
-480.954
-473.292
p = 2, q = 0, P = 0, Q = 1
243.903
-479.362
-479.806
-469.590
p = 1, q = 1, P = 1, Q = 0
243.496
-478.547
-478.992
-468.776
p = 0, q = 2, P = 1, Q = 0
243.480
-478.516
-478.961
-468.745
p = 2, q = 0, P = 1, Q = 1
244.424
-478.174
-478.848
-466.079
p = 0, q = 1, P = 0, Q = 0
237.930
-471.729
-471.859
-466.752
p = 1, q = 2, P = 0, Q = 0
239.930
-471.415
-471.859
-461.644
p = 1, q = 1, P = 0, Q = 0
237.929
-469.594
-469.858
-462.196
p = 0, q = 2, P = 0, Q = 0
237.924
-469.584
-469.848
-462.186
p = 1, q = 0, P = 0, Q = 1
237.442
-468.619
-468.883
-461.221
p = 1, q = 0, P = 1, Q = 1
237.551
-466.658
-467.102
-456.887
p = 2, q = 2, P = 0, Q = 0
238.267
-465.860
-466.534
-453.765
p = 2, q = 0, P = 0, Q = 0
232.478
-458.693
-458.957
-451.295
p = 0, q = 0, P = 0, Q = 1
226.062
-447.993
-448.124
-443.016
p = 0, q = 0, P = 1, Q = 1
226.282
-446.300
-446.563
-438.902
p = 2, q = 1, P = 0, Q = 0
226.105
-443.766
-444.211
-433.995
p = 1, q = 0, P = 0, Q = 0
222.409
-440.687
-440.818
-435.710
p = 2, q = 0, P = 1, Q = 0
220.456
-432.467
-432.911
-422.696
p = 0, q = 0, P = 1, Q = 0
218.236
-432.342
-432.472
-427.364
p = 1, q = 2, P = 1, Q = 1
220.708
-428.461
-429.416
-414.092
p = 0, q = 2, P = 0, Q = 1
215.116
-421.787
-422.232
-412.016
p = 0, q = 1, P = 0, Q = 1
213.007
-419.751
-420.015
-412.353
p = 2, q = 1, P = 0, Q = 1
214.469
-418.265
-418.939
-406.169
p = 1, q = 0, P = 1, Q = 0
211.232
-416.199
-416.463
-408.801
p = 2, q = 2, P = 0, Q = 1
213.877
-414.799
-415.754
-400.431
p = 2, q = 2, P = 1, Q = 1
214.698
-414.109
-415.397
-397.520
p = 1, q = 2, P = 0, Q = 1
211.492
-412.310
-412.984
-400.215
p = 1, q = 1, P = 0, Q = 1
208.149
-407.854
-408.299
-398.083
p = 0, q = 1, P = 1, Q = 1
204.745
-401.046
-401.490
-391.275
p = 0, q = 2, P = 1, Q = 1
203.978
-397.282
-397.956
-385.187
p = 1, q = 1, P = 1, Q = 1
203.564
-396.453
-397.127
-384.358
p = 1, q = 2, P = 1, Q = 0
170.812
-330.950
-331.624
-318.855
p = 2, q = 2, P = 1, Q = 0
167.845
-322.735
-323.690
-308.367
p = 2, q = 1, P = 1, Q = 0
-202.538
415.751
415.076
427.846
모수의 최종 추정치
유형
계수
SE 계수
T-값
P-값
SAR 12
-0.403
0.103
-3.92
0.000
MA 1
0.8704
0.0510
17.08
0.000
모형 요약
DF
SS
MS
MSD
AICc
AIC
BIC
93
0.0311326
0.0003348
0.0003277
-480.690
-480.954
-473.292
수정된 Box-Pierce(Ljung-Box) 카이-제곱 통계량
시차
12
24
36
48
카이-제곱
9.47
26.44
33.99
50.66
DF
10
22
34
46
P-값
0.489
0.233
0.468
0.295
* 경고 * 상수 항을 포함하지 않는 추정 불가능한 ARIMA(p, d, q)(P, D, Q) 모형: (2, 1, 1)(1, 1, 1)