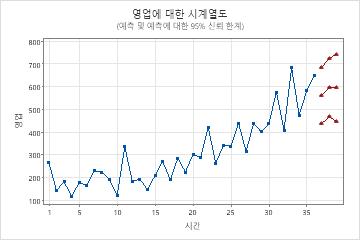
한 마케팅 분석가가 ARIMA 모델을 사용하여 샴푸 제품의 판매에 대한 단기 예측을 생성하려고 합니다. 분석가는 이전 삼 년간의 판매 데이터를 수집합니다. 분석가는 이전에 계열에 대한 시계열 플롯과 ACF(자기 상관 함수) 플롯을 조사했습니다. 두 플롯 모두 계절적이지 않은 차이점 보관의 순서에 대한 시작점으로 1을 제안합니다. 데이터는 시계열 플롯에 계절 패턴을 나타내지 않으므로 분석가는 비계절 모델로 시작하기로 선택합니다. 분석가는 향후 3개월 동안 예측을 요청합니다.
모델 선택 테이블은 AICc에 의해 순서대로 검색에서 모델의 순위를 매깁니다. ARIMA(0, 1, 2) 모델에는 AICc가 가장 적습니다. 다음 ARIMA 결과는 ARIMA (0, 1, 2) 모델에 대한 것입니다.
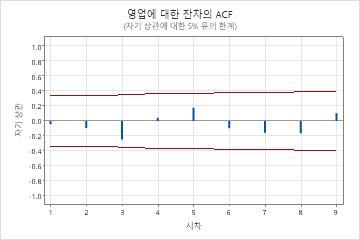
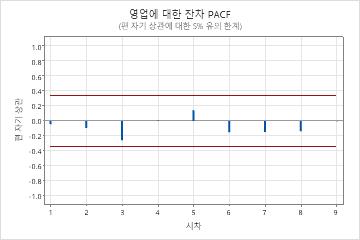
매개변수 테이블의 p-값은 이동 평균 항이 0.05 수준에서 유의하다는 것을 보여줍니다. 분석가는 계수가 모델에 속한다는 결론을 내립니다. 수정된 박스-피어스(Ljung-Box) 통계에 대한 p-값은 모두 0.05 레벨에서 중요하지 않습니다. 잔차의 ACF와 잔차의 PACF는 모두 각 플롯에서 0.05 한계 내에 있습니다. 분석가는 모형이 잔차가 서로 독립적이라는 가정을 충족한다는 결론을 내립니다. 분석가는 예측을 검토하는 것이 합리적이라고 결론지었습니다.
* 경고 * 상수 항을 포함하지 않는 추정 불가능한 ARIMA(p, d, q) 모형: (2, 1, 2)
방법
최상의 모형에 대한 기준
최소 AICc
사용된 행
36
사용되지 않은 행
0
모형 선택
모델(d = 1)
로그 우도
AICc
AIC
BIC
p = 0, q = 2*
-197.052
400.878
400.103
404.769
p = 1, q = 2
-196.989
403.311
401.978
408.199
p = 1, q = 0
-201.327
407.029
406.654
409.765
p = 2, q = 0
-200.239
407.251
406.477
411.143
p = 1, q = 1
-200.440
407.655
406.880
411.546
p = 2, q = 1
-201.776
412.884
411.551
417.773
p = 0, q = 1
-204.584
413.542
413.167
416.278
p = 0, q = 0
-213.614
429.350
429.229
430.784
모수의 최종 추정치
유형
계수
SE 계수
T-값
P-값
MA 1
1.257
0.132
9.52
0.000
MA 2
-0.882
0.133
-6.62
0.000
모형 요약
DF
SS
MS
MSD
AICc
AIC
BIC
33
131017
3970.21
3743.34
400.878
400.103
404.769
수정된 Box-Pierce(Ljung-Box) 카이-제곱 통계량
시차
12
24
36
48
카이-제곱
15.90
27.15
*
*
DF
10
22
*
*
P-값
0.103
0.206
*
*
* 경고 * 상수 항을 포함하지 않는 추정 불가능한 ARIMA(p, d, q) 모형: (2, 1, 2)