모형 방정식
이중 지수 평활은 각 기간에서의 수준 성분과 추세 성분을 사용합니다. 이중 지수 평활은 두 개의 가중치(평활화 모수라고도 함)를 사용하여 각 기간의 성분을 업데이트합니다. 이중 지수 평활 방정식은 다음과 같습니다.
공식
Lt= αYt+ (1 – α) [Lt–1 + Tt–1]
Tt= γ [Lt – Lt–1] + (1 – γ) Tt–1
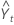 = Lt−1
+ Tt−1
= Lt−1
+ Tt−1
첫 번째 관측치에는 번호 1이 매겨진 경우 시간 0에서의 수준 및 추세 성분 추정치가 초기화되어야 계속할 수 있습니다. 평활값을 얻는 방법을 결정하는 데 사용되는 초기화 방법에는 두 가지가 있습니다. 한 가지는 최적 가중치를 사용하는 방법이고 다른 한 가지는 지정된 가중치를 사용하는 방법입니다.
표기법
| 용어 | 설명 |
|---|---|
| Lt | 시간 t에서의 수준 성분 |
| α | 수준 성분에 대한 가중치 |
| Tt | 시간 t에서의 추세 |
| γ | 추세에 대한 가중치 |
| Yt | 시간 t에서의 데이터 값 |
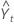 | 시간 t에 대한 예측값 |
가중치
최적 ARIMA 가중치
- Minitab에서는 오차 제곱의 합을 최소화하기 위해 데이터에 ARIMA(0,2,2) 모형을 적합시킵니다.
- 그런 다음 추세 성분과 수준 성분이 후진 예측을 통해 초기화됩니다.
지정된 가중치
- Minitab에서는 선형 회귀 모형을 시계열 데이터(y 변수) 대 시간(x 변수)에 적합시킵니다.
- 이 회귀 모형에서 얻은 상수는 수준 성분의 초기 추정치이고 기울기 계수는 추세 성분의 초기 추정치입니다.
같은 근의 ARIMA(0, 2, 2) 모형에 해당하는 가중치를 지정할 경우 Holt의 방법은 Brown의 방법으로 세분화됩니다1.
수준 및 추세에 대한 초기 값을 계산하는 방법
은(는) 수준 및 추세에 대한 추정치를 저장할 수 있습니다. Minitab은 대화 상자에서 지정한 옵션에 따라 다음 방법 중 하나를 사용하여 이러한 열의 첫 번째 행의 값을 계산합니다.
이중 지수 평활에서 최적 ARIMA 옵션을 선택하면 Minitab은 다음 방법을 사용하여 수준 및 추세의 첫 번째 값을 계산합니다. 이러한 단계를 수작업으로 수행할 수 있습니다.
- 을(를) 선택한 다음 ARIMA를 사용하여 최적의 가중치 값을 계산합니다. 다음과 같이 대화 상자를 완료합니다.
- 자기회귀에 0을 입력합니다.
- 차분에 2을 입력합니다.
- 이동 평균[MA]에 2을 입력합니다.
- 모형에 상수 항 포함을(를) 선택 해제합니다.
- 저장을(를) 클릭하고 잔차을(를) 선택합니다. 각 대화 상자에서 확인를 클릭합니다.
- Minitab은 ARIMA 출력의 MA 값을 사용하여 다음과 같이 최적의 가중치를 계산합니다.
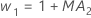
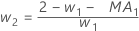
- 그런 다음 Minitab은 이후 관측치의 데이터를 사용하여 초기 관측치로 다시 계산합니다.
설명:
용어 설명 pi 번째 평탄한 관측치의 예측 값 xi 번째 시계열의 관측치 의 값 ei 위의 ARIMA로부터 저장된 번째 잔류물의 값 -
- Minitab은 수준(L1)의 초기 값을 계산합니다.

- Minitab은 추세(T1)의 초기 값을 계산합니다.
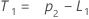

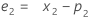
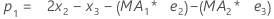
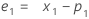
- 시계열 데이터의 열 길이와 동일한 시간 인덱스열을 만듭니다. 1에서 n까지의 정수 열로 충분합니다.
- 을 선택합니다.
- 반응에 시계열 데이터 열을 입력합니다. 계량형 예측 변수에 인덱스 열을 입력합니다.
- 저장을(를) 클릭하고 계수을(를) 선택합니다. 각 대화 상자에서 확인를 클릭합니다.
- 수준에 대한 초기 값은 다음과 같습니다.
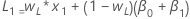
- 추세의 초기 값은 다음과 같습니다.
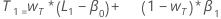 설명:
설명:용어 설명 L1 수준에 대한 초기 값 x1 시계열의 첫 번째 관측치 값 T1 추세에 대한 초기 값 wL 수준에 대한 가중치 값 wT 추세에 대한 가중치 값 β0 회귀 모형에서 상수 항의 상관 계수 β1 회귀 모형에서 예측 변수 항 상관 계수
예측값
이중 지수 평활에서는 수준 및 추세 성분을 사용하여 예측값을 생성합니다. 시간 t인 지점에서 m기간 이후에 대한 예측값은 다음과 같습니다.
공식
Lt + mTt
평활에는 예측시점 시간까지의 데이터가 사용됩니다.
표기법
| 용어 | 설명 |
|---|---|
| Lt | 시간 t에서의 수준 성분 |
| Tt | 시간 t에서의 추세 성분 |
예측 한계
공식
- 상한 = 예측값 + 1.96 × dt × MAD
- 하한 = 예측값 – 1.96 × dt × MAD
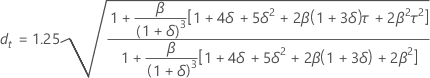
표기법
| 용어 | 설명 |
|---|---|
| β | max{α, γ) |
| δ | 1 – β |
| α | 수준 평활화 상수 |
| γ | 추세 평활화 상수 |
| τ |  |
| b0(T) | 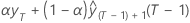 |
| b1(T) | 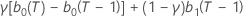 |
MAPE
평균 절대 백분율 오차(MAPE)는 적합된 시계열 값의 정확도를 측정합니다. MAPE는 정확도를 백분율로 표시합니다.
공식
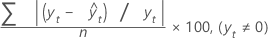
표기법
| 용어 | 설명 |
|---|---|
| yt | 시간 t에서의 실제 값 |
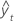 | 적합치 |
| n | 관측치 수 |
MAD
평균 절대 편차(MAD)는 적합된 시계열 값의 정확도를 측정합니다. MAD는 데이터와 같은 단위로 정확도를 표시하여 오차의 양을 개념화하는 데 사용됩니다.
공식
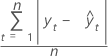
표기법
| 용어 | 설명 |
|---|---|
| yt | 시간 t에서의 실제 값 |
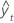 | 적합치 |
| n | 관측치 수 |
MSD
평균 제곱 편차(MSD)는 모형에 관계없이 항상 동일한 분모 n을 사용하여 계산됩니다. MSD는 매우 큰 예측 오차에 대해 MAD보다 더 민감한 측도입니다.
공식
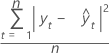
표기법
| 용어 | 설명 |
|---|---|
| yt | 시간 t에서의 실제 값 |
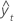 | 적합치 |
| n | 관측치 수 |