 의 경우
의 경우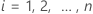 관찰된 데이터를 나타냅니다. 이 표현은 다음 정의를 사용합니다.
관찰된 데이터를 나타냅니다. 이 표현은 다음 정의를 사용합니다.
| 용어 | 설명 |
|---|---|
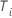 | ith 샘플 단위 또는 개인에 대한 연구 시간 |
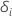 | 피사체 i가 검열되는 경우, 그러한 경우를 위한 지표 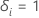 피험자 i 가 사건을 경험하고 피험자 i 가 사건을 경험하고 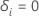 그렇지 않으면 그렇지 않으면 |
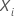 | 설계 매트릭스의 ith 행과 동등한 ith 개별에 대한 예측변수의 p-성분벡터 |
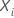 , 예측변수의 값은 연구의 시작 부분에 알려져 있으며, 연구 과정에서 변경되지 않는다. 예측 변수의 이러한 고정값은 연구 시점에 의존하지 않습니다. Minitab은 계산에서 다음과 같은 특성이 있는 행을 제외합니다.
, 예측변수의 값은 연구의 시작 부분에 알려져 있으며, 연구 과정에서 변경되지 않는다. 예측 변수의 이러한 고정값은 연구 시점에 의존하지 않습니다. Minitab은 계산에서 다음과 같은 특성이 있는 행을 제외합니다.
- 결측값이 있는 행 제거
- 이벤트 시간이 0인 행
- 음수 이벤트 시간을 가진 행
- 이벤트 시간이 응모 시간과 동일한 행
콕스 비례 위험 모델
 예측 변수 값의 벡터를 가진 개별 i의 경우
예측 변수 값의 벡터를 가진 개별 i의 경우 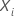 . 의 경우 수식의 형식은 다음과 같습니다.
. 의 경우 수식의 형식은 다음과 같습니다.

설명  생존 시간의 불특정 분포를 특징으로 하는 기준 위험률및
생존 시간의 불특정 분포를 특징으로 하는 기준 위험률및  예측 변수의 효과에 대한 알 수 없는 p-구성요소 벡터입니다. Cox 비례 위험 모델은 기준 위험 률의 분포에 대해 가정하지 않습니다.
예측 변수의 효과에 대한 알 수 없는 p-구성요소 벡터입니다. Cox 비례 위험 모델은 기준 위험 률의 분포에 대해 가정하지 않습니다.
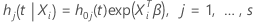
설명 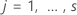 다른 지층을 나타냅니다. 이 사양은 회귀 계수가 지층 간에 동일하다고 가정합니다. 이 가정은 경사가 일정하다는 문과 동일합니다. 기본 위험 함수는 지층 간에 변경될 수 있습니다.
다른 지층을 나타냅니다. 이 사양은 회귀 계수가 지층 간에 동일하다고 가정합니다. 이 가정은 경사가 일정하다는 문과 동일합니다. 기본 위험 함수는 지층 간에 변경될 수 있습니다.
관측 중단
신뢰도 분석에서 고장 데이터에는 보통 개별 수명이 포함됩니다. 예를 들어, 특정 온도에서 작동하는 부품의 수명을 수집할 수 있습니다. 여러 가지 온도 하에서 또는 다양한 조합의 스트레스 변수 하에서 수명 표본을 수집할 수도 있습니다.
때로는 정확한 수명을 기록합니다. 어떤 경우에는 검사 단위의 정확한 수명을 알 수 없습니다. 이 경우, 데이터를 관측 중단 데이터라고 합니다. 고장 데이터는 일반적으로 여러 방법으로 관측 중단됩니다. Minitab 통계 소프트웨어에서 Cox 비례 위험 모델은 단위 또는 피사체의 마지막 관찰에 의해 이벤트가 발생하지 않는 행을 고려합니다. 이러한 행은 오른쪽 검열입니다.
왼쪽 잘림
왼쪽 잘림은 연구의 기원에서 일어나지 않는 연구의 잠재적 인 과목의 관찰이 일어나지 않는 경우이지만 주제는 특정 나중에 연구에 입력합니다. 이 시간은 나중에 입력 시간입니다. 예를 들어, 장기 이식 대기자 명단에 있는 환자는 환자가 장기를 받을 때까지 연구에 참여하지 않습니다. 이벤트 시간 t에 대한 위험 세트R(t)은표현을 만족시키는 모든 피사체의 집합입니다. 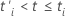 어디서
어디서 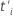 및
및 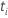 대상은 각각 응모 시간 및 주제 입력 시간 지연입니다. 이벤트 시간에 설정된 위험에는 응모 시간이 이벤트 시간보다 큰 과목을 포함하지 않습니다.
대상은 각각 응모 시간 및 주제 입력 시간 지연입니다. 이벤트 시간에 설정된 위험에는 응모 시간이 이벤트 시간보다 큰 과목을 포함하지 않습니다.
- 잘되지 않고 오른쪽 검열
- 왼쪽 잘린 오른쪽 검열
- 무단 및 무수정
왼쪽 잘림은 왼쪽 검열과 다릅니다. 주제를 관찰하기 전에 이벤트가 발생하는 경우 주제 이벤트 시간이 왼쪽으로 검열됩니다. 왼쪽 검열 데이터를 사용하면 관찰된 시간이 이벤트 시간보다 큽습니다. Minitab 통계 소프트웨어는 Cox 회귀 분석에서 왼쪽 검열 된 데이터를 제외합니다.
상관 관찰 및 견고한 공변성 추정기
일부 모델에서는 설계가 관측의 하위 그룹과 상관 관계를 맺습니다. 예를 들어, 주체 관측값은 반복 또는 반복 이벤트를 포함하는 모델에서 상관 관계가 있습니다. 린과 웨이 (1989)1주체 내 관찰 간의 상관 관계를 설명하기 위해 공변 행렬의 조정을 제안합니다. 그러면  점수 잔류의 행렬이 될 수 있습니다. 분산-공분산 행렬의 형식은 다음과 같습니다.
점수 잔류의 행렬이 될 수 있습니다. 분산-공분산 행렬의 형식은 다음과 같습니다.

설명 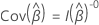 및
및  붕괴된 점수 잔류 매트릭스입니다. 붕괴된 점수 잔류 행렬을 얻으려면 각 잔여 행 클러스터를 잔여 행의 합계로 바꿉다.
붕괴된 점수 잔류 매트릭스입니다. 붕괴된 점수 잔류 행렬을 얻으려면 각 잔여 행 클러스터를 잔여 행의 합계로 바꿉다.
- 추론에 대한 계산은 강력한 분산-코바변 매트릭스를 사용합니다.
- 맞춤이 좋은 테이블의 Wald 및 Score 테스트는 강력한 분산-코바변 매트릭스를 사용합니다. 적합성 표의 가능성 비율 테스트는 가능성 비율 테스트가 클러스터 내의 관측값이 독립적이라고 가정하기 때문에 누락되었습니다.
- ANOVA 테이블은 Wald 테스트만 사용할 수 있습니다.