분산 분석은 모델의 각 예측변수에 대한 통계적 유의성 테스트를 제공합니다.
+ DF
승산비에 대한 해석은 예측 변수가 범주형인지 아니면 계량형인 지에 따라 달라집니다. 범주형 예측자의 경우 자유도는예측변수(k – 1)에서 레벨, k,레벨 수보다 1배 적습니다. 연속 예측변수의 경우 자유도는 항상 1입니다. 고차 적인 용어의 경우, 자유의 정도는 복합 용어에서 자유도의 산물입니다. 예를 들어, 두 3단계 범주 예측자 간의 상호 작용에 대한 자유도는 2 × 2 = 4입니다.
카이-제곱 분포
- Wald 검정
- 우도 비 검정
- 점수 테스트
클러스터가 설계에 있는 경우 가능성은 비율 및 점수 메서드가 클러스터 내의 관측이 독립적이라고 가정하기 때문에 Minitab은 Wald 테스트를 기반으로 ANOVA 테이블을 제공합니다.
응답 변수에 응답 시간이 묶여 있지 않으면 점수 테스트가 잘 알려진 로그 랭크 테스트와 동일합니다.
정의:
모든 3가지 유형의 테스트에 대한 계산은 다음 정의를 사용합니다.
그러면 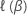 는 Breslow 편우도 함수 또는 β 에서 평가된 Efron 편우도 함수입니다.
는 Breslow 편우도 함수 또는 β 에서 평가된 Efron 편우도 함수입니다.
그러면 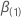 q-구성요소 벡터및
q-구성요소 벡터및 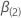 2 p-성분 계수 벡터가 다음과 같은 정의를 갖을 수 있도록(p – q)-성분 벡터가 될 수 있습니다.
2 p-성분 계수 벡터가 다음과 같은 정의를 갖을 수 있도록(p – q)-성분 벡터가 될 수 있습니다. 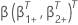 및
및 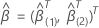 까지 평가할 예측 변수의 다양한 수를 선택할 수 있는 옵션이 있습니다.
까지 평가할 예측 변수의 다양한 수를 선택할 수 있는 옵션이 있습니다.
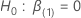

그러면 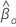 (부분) 최대 확률이 될 수 있습니다.
(부분) 최대 확률이 될 수 있습니다.  제한된 모델 에서
제한된 모델 에서 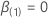 . 그런 다음 null 가설에 따른 최대 가능성 추정치에는 다음과 같은 양식이 있습니다.
. 그런 다음 null 가설에 따른 최대 가능성 추정치에는 다음과 같은 양식이 있습니다.
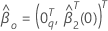
설명  제로의 q-구성요소 벡터이며
제로의 q-구성요소 벡터이며  (부분) 최대 가능성
(부분) 최대 가능성  하면
하면  .
.
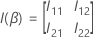
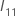 q × q 행렬입니다.
q × q 행렬입니다.
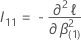
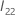 q 매트릭스는 다음과 같은 p – q × p – q 매트릭스입니다.
q 매트릭스는 다음과 같은 p – q × p – q 매트릭스입니다.
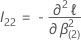
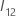 및
및  에는 다음과 같은 정의가 있습니다.
에는 다음과 같은 정의가 있습니다.

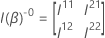
null 가설에 따라 세 가지 테스트(Wald, 가능성 비율 및 점수 테스트)에 대한 테스트 통계는 자유의 q 도가 있는 대명토틱 치스퀘어 분포를 가지고 있습니다. 확장 분포는 모델의 매개 변수 수에 비해 관찰된 이벤트 수가 클 때 유효합니다. 범주형 예측변수의 경우 각 레벨의 이벤트 수도 충분히 커야 합니다.
Wald 검정
Wald 테스트의 경우 테스트 통계에는 다음과 같은 양식이 있습니다.
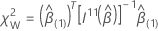
설명 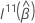 상부 q × q 서브 매트릭스
상부 q × q 서브 매트릭스  .
.
디자인에 클러스터가 있는 경우 계산은 Lin & Wei (1989)1. 그러면  점수 잔류의 행렬이 될 수 있습니다. 분산-공분산 행렬의 형식은 다음과 같습니다.
점수 잔류의 행렬이 될 수 있습니다. 분산-공분산 행렬의 형식은 다음과 같습니다.

설명 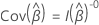 및
및  붕괴된 점수 잔류 매트릭스입니다. 붕괴된 점수 잔류 행렬을 얻으려면 각 잔여 행 클러스터를 잔여 행의 합계로 바꿉다.
붕괴된 점수 잔류 매트릭스입니다. 붕괴된 점수 잔류 행렬을 얻으려면 각 잔여 행 클러스터를 잔여 행의 합계로 바꿉다.
우도 비 검정
우도 비 검정의 가설은 다음과 같습니다.
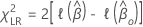
설명 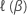 적절한 모델 부분 로그 가능성 함수입니다.
적절한 모델 부분 로그 가능성 함수입니다.
클러스터가 설계에 있는 경우 가능성은 비율 및 점수 메서드가 클러스터 내의 관측이 독립적이라고 가정하기 때문에 Minitab은 Wald 테스트를 기반으로 ANOVA 테이블을 제공합니다.
점수 테스트
그러면  로그 가능성 함수의 부분 파생 상품의 벡터가 될 수 있습니다.
로그 가능성 함수의 부분 파생 상품의 벡터가 될 수 있습니다. 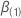 . 특히, 이 q-구성요소 벡터는 다음과 같은 형태를 가지고 있습니다.
. 특히, 이 q-구성요소 벡터는 다음과 같은 형태를 가지고 있습니다.
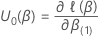
그런 다음 점수 테스트에 대한 테스트 통계에는 다음과 같은 양식이 있습니다.
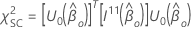
클러스터가 설계에 있는 경우 가능성은 비율 및 점수 메서드가 클러스터 내의 관측이 독립적이라고 가정하기 때문에 Minitab은 Wald 테스트를 기반으로 ANOVA 테이블을 제공합니다.
P-값
수정된 p-값은 다음과 같은 식으로 계산됩니다.

설명  치스퀘어 분포를 따르는 임의의 변수입니다.
치스퀘어 분포를 따르는 임의의 변수입니다.  자유도.
자유도.  는 검정 통계량입니다.
는 검정 통계량입니다.