혼합 모형 및 로그 우도
혼합 모형의 일반 형태
혼합 효과 모형에는 고정 효과와 랜덤 효과가 모두 포함됩니다. 혼합 효과 모형의 일반적인 형태는 다음과 같습니다.
y = Xβ + Z1μ1+ Z2μ2 + ... + Zcμc + ε
표기법
| 용어 | 설명 |
|---|---|
| y | 반응 값의 n x 1 벡터 |
| X | 고정 효과에 대한 n x p 설계 행렬, p ≤ n |
| Zi | 모형의 i번째 랜덤 효과에 대한 n x mi 설계 행렬 |
| β | 알 수 없는 모수의 p x 1 벡터 |
| μi | N(0, σ2i)의 독립 변수의 mi x 1 벡터 |
| ε | N(0, σ2i)의 독립 변수의 ni x 1 벡터 |
| c | 모형의 랜덤 효과 수 |
혼합 모형의 특수 형태
안정성 연구는 변량 배치 요인을 사용하여 두 개의 모형을 적합합니다. 최대 모형에는 시간, 변량 배치 요인, 시간과 배치 간의 변량 교호작용이 포함됩니다.
y = Xβ + Z1μ1+ Z2μ2 + ε
더 작은 모형에는 시간과 변량 배치 요인이 포함됩니다.
y = Xβ + Z1μ1+ε
반응 벡터 y의 일반 분산-공분산 행렬은 다음과 같습니다.
V(σ2) = V(σ2, σ21, ... , σ2c) = σ2In + σ21Z1Z'1 + ... + σ2cZcZ'c
설명:
σ2 = (σ2, σ21, ... , σ2c)'
σ2, σ21, ... , σ2c는 분산 성분이라고도 합니다.
분산에서 요인을 구분하여 혼합 모형의 로그 우도를 계산하는 H(θ)의 표현을 찾을 수 있습니다.
V(σ2) = σ2H(θ) = σ2[In + θ1Z1Z'1 + ... + θcZcZ'c]
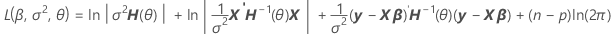
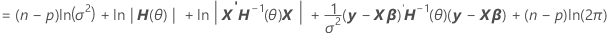
표기법
| 용어 | 설명 |
|---|---|
| n | 관측치 수 |
| p | β의 모수 수, 안정성 연구의 경우 2 |
| σ2 | 오차 분산 성분 |
| X | 고정 항, 상수 및 시간에 대한 설계 행렬 |
| H(θ) | In + θ1Z1Z'1 + ... + θcZcZ'c |
| In | 행과 열이 n개인 단위 행렬 |
| θi | 오차 분산에 대한 i번째 랜덤 항의 분산 비율 |
| Zi | 모형의 i번째 랜덤 효과에 대한 알려진 코드화의 n x mi 행렬 |
| mi | i번째 랜덤 효과에 대한 수준 수 |
| c | 모형의 랜덤 효과 수 |
| |H(θ)| | H(θ)의 행렬식 |
| X' | X의 전치 |
| H-1(θ) | H(θ)의 역 |
Box-Cox 변환
Box-Cox 변환은 아래와 같이 잔차 제곱합을 최소화하는 람다 값을 선택합니다. 결과 변환은 λ ≠ 0일 때 Y λ, λ = 0일 때 ln(Y)입니다. λ < 0인 경우 Minitab에서는 변환되지 않은 반응의 순서를 유지하기 위해 변환된 반응에 −1을 곱합니다.
Minitab은 -2와 2 사이의 최적 값을 검색합니다. 이 구간을 벗어나는 값의 결과는 더 적합하지 않을 수 있습니다.
Y'가 데이터 Y의 변환인 일반적인 변환의 몇 가지 예는 다음과 같습니다.
| 람다(λ) 값 | 변환 |
|---|---|
| λ = 2 | Y′ = Y 2 |
| λ = 0.5 | Y′ = |
| λ = 0 | Y′ = ln(Y ) |
| λ = −0.5 | |
| λ = −1 | Y′ = −1 / Y |
변량 배치 모형 선택
- 시간 + 배치 + 배치*시간(배치의 기울기와 절편이 같지 않음)
- 시간 + 배치(배치의 기울기와 절편이 같음)
- 시간(배치의 기울기와 절편이 같음)
배치*시간 교호작용이 유의하면 분석에서 첫 번째 모형을 적합합니다. 교호작용이 유의하지 않지만 두 번째 모형에서 배치 항이 유의하면 분석에서 두 번째 모형을 적합합니다. 그렇지 않으면 분석에서 세 번째 모형을 적합합니다.
두 검정 모두 카이-제곱 분포에 종속되지만, 배치를 합동할 것인 지에 대한 검정은 배치를 포함하기 위한 검정과 약간 다릅니다. 검정 통계량 및 p-값에 대한 공식은 다음과 같습니다.
모형 1과 모형 2 간의 검정
차이 = −2L2 − (−2L1)
p = 0.5 * 확률(χ21 > 차이) + 0.5 * 확률(χ22 > 차이)
모형 2와 모형 3 간의 검정
차이 = −2L3 − (−2L2)
p = 0.5 * Prob(χ21 > 차이)
표기법
| 용어 | 설명 |
|---|---|
| La | 모형 a의 로그 우도 |
| p | 검정에 대한 p-값 |
| 확률(χ21> 차이) | 자유도가 1인 카이-제곱 분포의 랜덤 변수가 차이보다 클 확률 |
| 확률(χ22> 차이) | 자유도가 2인 카이-제곱 분포의 랜덤 변수가 차이보다 클 확률 |
참고 문헌
- Searle, S.R. Casella, G. and McCuloch, C.E. (1992). Variance Components
- West, B.T., Welch, K.B. and Galecki, A.T. (2007). Linear Mixed Models: A Practical Guide Using Statistical Software.
- Chow, S. (2007). Statistical Design and Analysis of Stability Studies.