원하는 방법 또는 공식을 선택하십시오.
혼합 모형의 계수
행렬 항에서 계수의 벡터는 다음과 같습니다.
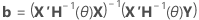
표기법
| 용어 | 설명 |
|---|---|
| X | 설계 행렬(상수 포함) |
| X' | X의 전치 |
| Y | 반응 데이터 |
 | 의 역  |
 |
 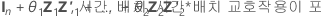  |
 | 행과 열이 n개인 단위 행렬 |
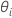 | 모형의 i번째 랜덤 효과에 대한 분산 비율 |
 | 모형의 i번째 랜덤 효과에 대한 알려진 코드화의 n x mi 행렬 |
| mi | i번째 랜덤 효과에 대한 수준 수 |
| c | 모형의 랜덤 효과 수 c = 2(시간, 배치, 시간*배치 교호작용이 포함된 모형의 경우) c = 1(시간과 배치가 포함된 모형의 경우) |
혼합 모형에 있는 계수의 표준 오차
계수의 표준 오차는 고정 효과에 대한 검정 방법에 따라 달라집니다. 표기법에 대한 자세한 내용은 방법 및 고정 효과 검정 섹션에서 확인하십시오.
Kenward-Roger의 근사
추정된 계수의 표준 오차는 행렬 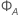 의 대각 원소의 제곱근입니다.
의 대각 원소의 제곱근입니다.
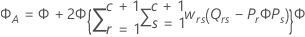
설명:

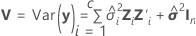
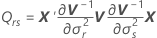
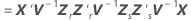
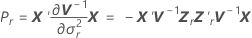
Satterthwaite 근사
표준 오차는 행렬  의 대각 원소 제곱근입니다.
의 대각 원소 제곱근입니다.

의 대각 원소 제곱근입니다.
설명:
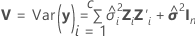
계수에 대한 자유도
다음은 계수의 검정에 대한 가설입니다.
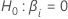
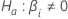
다음 방정식은 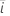 계수에 대한 자유도를 제공합니다.
계수에 대한 자유도를 제공합니다.

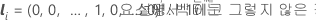
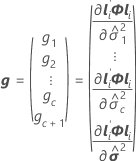

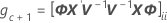
계수에 대한 자유도를 제공합니다.
표기법에 대한 자세한 내용은 방법 및 고정 효과 검정 섹션에서 확인하십시오.
계수에 대한 신뢰 구간
다음 순서의 계수에 대한 (1 − α)% 신뢰 구간:  은 다음 방정식을 갖습니다.
은 다음 방정식을 갖습니다.

은 다음 방정식을 갖습니다.
표기법
| 용어 | 설명 |
|---|---|
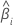 | 추정된 계수 |
 | 자유도가 df인 t 분포의 1 − α/2 백분위수 |
 | 추정된 계수의 표준 오차 |
t-값
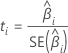
표기법
| 용어 | 설명 |
|---|---|
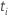 | 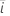 계수에 대한 검정 통계량 계수에 대한 검정 통계량 |
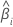 | 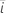 추정된 계수 추정된 계수 |
 | 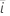 추정된 계수의 표준 오차 추정된 계수의 표준 오차 |
p-값(P)
다음 방정식은 계수가 0이라는 귀무 가설에 대한 양측 p-값을 제공합니다.

표기법
| 용어 | 설명 |
|---|---|
 | 귀무 가설 하에 T가 계산된 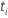 의 절대값보다 작을 확률입니다. 여기서 T는 자유도가 df인 t-분포를 따릅니다. 의 절대값보다 작을 확률입니다. 여기서 T는 자유도가 df인 t-분포를 따릅니다. |
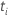 | 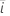 계수에 대한 t 값. 계수에 대한 t 값. |