원하는 방법 또는 공식을 선택하십시오.
이 항목의 내용
회귀 방정식
측정 오차 모형은 다음과 같습니다.
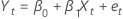
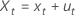
직교 회귀 분석에서는 표시된 점에서 선까지의 가중 직교 거리를 최소화하는 선이 최상의 적합선입니다. 오차 분산 비율이 1인 경우 가중 거리는 Euclid 거리입니다.
표기법
| 용어 | 설명 |
|---|---|
| Yt | 관측 반응값 |
| β0 | 절편 |
| β1 | 기울기 |
| Xt | 관측된 예측 변수 |
| xt | 예측 변수의 실제 및 미관측 값 |
| et, ut | 측정 오류, et, ut가 독립적이고 평균은 0이고 오차 분산이 δe2 및 δu2입니다. |
표본 공분산 행렬
표본 평균이 (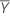 ,
, 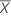 )이고 표본 공분산 행렬이 다음과 같은 경우
)이고 표본 공분산 행렬이 다음과 같은 경우
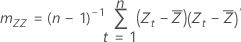
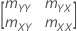
, )이고 표본 공분산 행렬이 다음과 같은 경우
표기법
| 용어 | 설명 |
|---|---|
| Zt | (Yt, Xt) |
 |  |
| n | 표본 크기 |
오차 분산
표본 공분산 행렬은 2 × 2 행렬입니다.
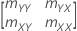
표본 공분산 행렬의 mXY 원소가 0이 아닌 경우 다음과 같습니다.
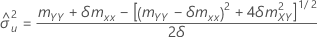
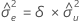
mxy = 0이고 myy < δm xx'안 경우,

표기법
| 용어 | 설명 |
|---|---|
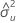 | X에 대한 오차 분산 추정치 |
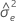 | Y에 대한 오차 분산 추정치 |
| δ | 오차 분산 비율 |
| mXY | 표본 공분산 행렬의 원소 |
| mYY | 표본 공분산 행렬의 원소 |
| mXX | 표본 공분산 행렬의 원소 |
계수
표본 공분산 행렬의 mXY 원소가 0이 아니면 다음과 같습니다.
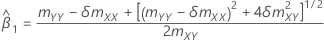
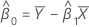

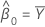
mxy = 0이고 myy < δm xx'안 경우,'
mxy = 0이고 myy > δmxx인 경우 나머지 모수 추정치는 정의되지 않습니다.
표기법
| 용어 | 설명 |
|---|---|
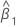 | 기울기 추정치 |
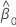 | 절편 추정치 |
| mxy | 표본 공분산 행렬의 원소 |
| myy | 표본 공분산 행렬의 원소 |
| δ | 오차 분산 비율 |
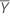 | 반응 값의 평균 |
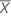 | 예측 변수 값의 평균 |
근사 분포의 공분산 행렬
절편과 기울기 근사 분포의 공분산 행렬 추정치:
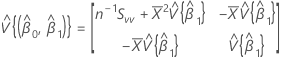
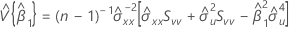
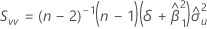
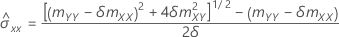
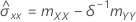
설명:
및
mXY가 0과 같지 않은 경우:
mXY가 0이고 mYY < δmXX인 경우:
표기법
| 용어 | 설명 |
|---|---|
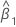 | 기울기 추정치 |
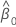 | 절편 추정치 |
| mXY | 표본 공분산 행렬의 원소 |
| mYY | 표본 공분산 행렬의 원소 |
| mXX | 표본 공분산 행렬의 원소 |
| δ | 오차 분산 비율 |
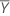 | 반응 값의 평균 |
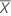 | 예측 변수 값의 평균 |
절편에 대한 신뢰 구간
β0에 대한 100(1 - α)% 신뢰 구간은 다음과 같습니다.
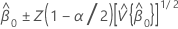
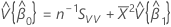 이는 근사 분포의 공분산 행렬의 원소입니다.
이는 근사 분포의 공분산 행렬의 원소입니다.
Z (1 - α / 2)는 표준 정규 분포의 100 * (1 - α / 2) 백분위수입니다.
그리고
이는 근사 분포의 공분산 행렬의 원소입니다. 표기법
| 용어 | 설명 |
|---|---|
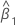 | 기울기 추정치 |
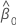 | 절편 추정치 |
| α | 유의 수준 |
기울기에 대한 신뢰 구간
β1에 대한 100(1 - α)% 신뢰 구간은 다음과 같습니다.
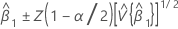
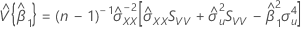
설명:
Z(1 - α / 2)는 표준 정규 분포의 100 * (1 - α / 2) 백분위수입니다.
그리고
표기법
| 용어 | 설명 |
|---|---|
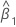 | 기울기 추정치 |
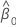 | 절편 추정치 |
| α | 유의 수준 |
x에 대한 적합치
직교 회귀 분석의 예측 변수 x에 대한 적합치는 다음과 같습니다.
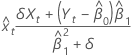
표기법
| 용어 | 설명 |
|---|---|
| δ | 오차 분산 비율 |
| Yt | t번째 반응 값 |
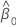 | 절편 추정치 |
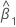 | 기울기 추정치 |
y에 대한 적합치
직교 회귀 분석의 반응값 y에 대한 적합치는 다음과 같습니다.
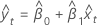
표기법
| 용어 | 설명 |
|---|---|
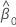 | 절편 추정치 |
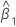 | 기울기 추정치 |
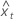 | x에 대한 t번째 적합치 |
잔차
직교 회귀 분석의 관측치 잔차는 다음과 같습니다.
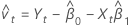
표기법
| 용어 | 설명 |
|---|---|
| Yt | t번째 반응 값 |
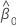 | 절편 |
| Xt | t번째 예측 변수 값 |
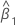 | 기울기 |
표준화 잔차
표준화 잔차는 특이치를 식별하는 데 유용하며, 다음과 같이 계산합니다.


설명
표기법
| 용어 | 설명 |
|---|---|
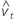 | 잔차 |
 | 잔차의 표준 편차 |
| δ | 오차 분산 비율 |
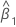 | 기울기 추정치 |
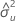 | X에 대한 오차 분산 추정치 |
Y의 예측 변수
Yn + 1의 예측 변수는 다음과 같습니다.
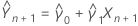
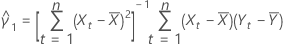
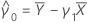
설명:
및
표기법
| 용어 | 설명 |
|---|---|
| Xt | t번째 예측 변수 값 |
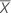 | 예측 변수 값의 평균 |
| Yt | t번째 반응 값 |
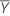 | 반응 값의 평균 |
예측 오차의 표준 편차

설명:
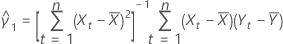
표기법
| 용어 | 설명 |
|---|---|
| myy | Y의 표본 분산 |
| mxy | X와 Y 랜덤 변수 간 표본 공분산 |