이 항목의 내용
연결 함수
Minitab은 로짓(기본값), 노밋 및 곰핏이라는 세 가지 연결 함수를 제공합니다. 연결 함수는 광범위한 종류의 순서형 반응 모형을 적합시키기 위해 사용할 수 있습니다. 로짓은 표준 누적 로지스틱 분포 함수의 역함수입니다. 프로핏이라고도 하는 노밋 함수는 표준 누적 분포 함수의 역함수입니다. 보 로그-로그라고도 하는 곰핏 함수는 Gompertz 분포 함수의 역함수입니다.
공식
g(χk) = θk +x'β, k = 1, ..., K-1
연결 함수는 분포 함수의 역함수입니다. 연결 함수와 해당되는 분포는 아래와 같이 요약됩니다.
| 이름 | 연결 함수 | 분포 |
|---|---|---|
| 로짓 | g(χ) = loge(χ/ (1 – χ)) | 로지스틱 분포 |
| 노밋(프로빗) |
g(χ) = Φ–1(χ) |
정규 분포 |
| 곰핏(보 로그-로그) | g(χ) =loge (–loge(1 – χ)) | Gompertz |
표기법
| 용어 | 설명 |
|---|---|
| K | 반응값의 개별 범주 수 |
| χk | k, (π1+ ...+ πk) 이하 범주까지의 누적 확률 |
| g(χk) | 예측 변수의 벡터 |
| θk | k번째 개별 반응값 범주와 연관된 상수 |
| x | 예측 변수의 벡터 |
| β | 예측 변수와 연관된 계수의 벡터 |
요인/공변량 패턴
데이터 집합의 단일 요인/공변량 값 집합에 대해 설명합니다. Minitab에서는 각 요인/공변량 패턴에 대한 사건 확률, 잔차 및 기타 진단 측도를 계산합니다.
예를 들어 데이터 집합에 성별 및 인종 요인과 나이 공변량이 포함되어 있는 경우, 이런 예측 변수의 조합에는 피실험자 수만큼 많은 공분산 패턴이 포함될 수 있습니다. 데이터 집합에 각각 2개 수준에서 코드화된 인종과 성별 요인만 포함되어 있는 경우, 가능한 요인/공변량 패턴은 4개뿐입니다. 데이터를 빈도나 성공, 시행 또는 실패 횟수로 입력할 경우 각 행에 요인/공변량 패턴이 하나씩 포함됩니다.
사건 확률
사건 확률은 k = 1, 2, ..., K인 경우 πk입니다.
공식
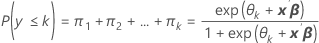
표기법
| 용어 | 설명 |
|---|---|
| k | = 1, ..., K – 1 |
| θk | 상수 |
| β | 로짓 방정식의 계수 벡터 |
누적 사건 확률
반응값이 가능한 각 k에 대해 k 이하로 떨어질 확률입니다. k번째 누적 확률은 다음과 같습니다.
공식
P(y k) = p1 + ... + pk,k = 1, ... , K
k) = p1 + ... + pk,k = 1, ... , K
누적 확률은 반응값의 순서를 나타냅니다. 반응값 범주가 k개인 모형의 경우:
P(y 1) <P(y
1) <P(y 2)
2)  …
… P(y
P(y K) = 1
K) = 1

계수
Minitab에서는 예측 변수의 벡터 x에 k 범주 이하 반응값의 로그 확률에 x가 미치는 영향을 설명하는 모수 β가 있는 비례 확률 모형을 사용합니다. Minitab은 x가 모든 K – 1 범주에 미치는 영향이 같다고 가정하므로, 각 예측 변수에 대해 계수를 1개만 계산합니다. 예측 변수에 대한 계수는 고정된 k에 대해 예측 변수가 한 수준에 있는 경우 반응값 로짓의 변동 추정치를 기준 수준과 비교하여 나타냅니다.
Minitab은 각 K – 1 범주에 대해 상수를 추정합니다. 누적 확률 모형을 사용하여 각 범주에 대해 추정되는 확률을 계산하려면 모수 추정치를 사용합니다.
공식
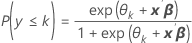
추정 계수는 최대 우도 추정과 동등한 반복 재가중 최소 제곱법을 사용하여 계산합니다.1,2
참고 문헌
- D.W. Hosmer and S. Lemeshow (2000). Applied Logistic Regression. 2nd ed. John Wiley & Sons, Inc.
- P. McCullagh and J.A. Nelder (1992). Generalized Linear Model. Chapman & Hall.
계수 표준 오차
추정 계수의 정확도를 나타내는 점근적 표준 오차. 표준 오차가 작을수록 추정값이 더 정확합니다.
자세한 내용은 [1]과 [2]를 참조하십시오.
- A. Agresti (1990). Categorical Data Analysis. John Wiley & Sons, Inc.
- P. McCullagh and J.A. Nelder (1992). Generalized Linear Model. Chapman & Hall.
Z
Z는 예측 변수가 반응과 유의한 연관이 있는지 확인하기 위해 사용합니다. Z의 절대값이 클수록 관계가 유의함을 나타냅니다. p-값은 정규 분포에서 Z가 어디에 위치하는지 나타냅니다.
공식
Z = βi / 표준 오차
상수 공식은 다음과 같습니다.
Z = θk / 표준 오차
표본이 작은 경우, 우도 비율 검정이 더 신뢰할 수 있는 유의도 검정일 수 있습니다.
p-값(P)
귀무 가설을 기각하거나 받아들이는 가설 검정에서 사용됩니다. p-값은 귀무 가설이 참인 경우 최소한 실제로 계산된 값만큼 극단적인 검정 통계량을 얻을 확률입니다. 일반적으로 사용되는 p-값에 대한 컷오프 값은 0.05입니다. 예를 들어, 검정 통계량의 계산된 p-값이 0.05보다 작으면 귀무 가설을 기각합니다.
승산비
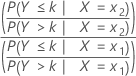
Minitab에서는 순서형 로지스틱 회귀 분석에 비례 확률 모형을 사용합니다. 각 예측 변수에 대해 모수 하나와 승산비 하나만 계산합니다. 승산비는 누적 확률과 누적 확률의 보를 사용합니다. 2개 수준 x1과 x2가 있는 예측 변수의 경우 누적 승산비는 다음과 같습니다.
공식
신뢰 구간
공식
βi 에 대한 큰 표본 신뢰 구간은 다음과 같습니다.
β i + Zα /2*(표준 오차)
확률 비율의 신뢰 구간을 구하려면 신뢰 구간의 하한 및 상한을 멱승하십시오. 구간은 예측 변수의 모든 단위 변동에 대해 확률이 하락할 수 있는 범위를 정합니다.
표기법
| 용어 | 설명 |
|---|---|
| α | 유의 수준 |
로그 우도
식은 개별 확률 밀도 함수로부터 도출되며, β의 최적 값을 산출하기 위해 극대화됩니다. 로그 우도는 표본 크기에 좌우되므로 단독으로 측도로 사용할 수 없지만, 두 모형을 비교하기 위해 사용할 수 있습니다.
순서형 로지스틱 회귀 분석의 경우, 각각 k개의 범주를 포함하는 n개의 독립적인 다항 벡터가 있습니다. 이런 관측치는 y1, ..., yn로 표시되며, 여기서 yi = (yi1, ..., yik)이고 Σjyij = mi는 각 i에 대해 고정되어 있습니다. i번째 관측치 yi에서 로그 우도에 대한 기여는 다음과 같습니다.
공식
L(πi ; yi) = Σkyik log πik
총 로그 우도는 n개 관측치의 기여를 각각 합한 값입니다.
L(π ; y) = Σi L(πi; yi)
표기법
| 용어 | 설명 |
|---|---|
| πik | k번째 범주에 대한 i번째 관측치의 확률 |
분산-공분산 행렬
p + K – 1 차원을 포함하는 사각 행렬. 각 계수의 분산은 대각 셀에 있고 각 계수 쌍의 공분산은 해당 대각 외 셀에 있습니다. 분산은 계수 제곱의 표준 오차입니다.
분산-공분산 행렬은 점근적이며, 정보 역행렬의 마지막 반복으로부터 얻습니다.
표기법
| 용어 | 설명 |
|---|---|
| p | 예측 변수의 수 |
| K | 반응의 범주 수 |
Pearson
모형이 데이터에 적합한 정도를 나타내는 Pearson 잔차에 기초한 요약 통계량. Pearson은 공분산의 개별 값 수가 관측치 수와 거의 같은 경우 유용하지 않지만, 공분산 수준이 같은 반복 관측치가 있는 경우 유용합니다. χ2 검정 통계량이 높고 p-값이 낮을수록 모형이 데이터에 적합하지 않을 수 있음을 나타냅니다.
공식은 다음과 같습니다.
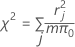
여기서 r = Pearson 잔차, m = j번째 요인/공분산 패턴의 시행 횟수, 그리고 π0 = 비율 가설 값입니다.
이탈도
모형이 데이터에 적합한 정도를 나타내는 이탈도 잔차에 기초한 요약 통계량. 이탈도는 공분산의 개별 값 수가 관측치 수와 거의 같은 경우 유용하지 않지만, 공분산 수준이 같은 반복 관측치가 있는 경우에는 유용합니다. D 값이 더 높고 p-값이 더 낮을수록 모형이 데이터에 적합하지 않을 수 있음을 나타냅니다. 검정에 대한 자유도는 (k - 1)*J − (p)이며, 여기서 k는 반응값의 숫자 범주이고 J는 개별 요인/공분산 패턴의 수이며 p는 계수의 수입니다.
공식은 다음과 같습니다.
D =2 Σ yik log p ik− 2 Σ yik log π ik
여기서 πik = k번째 범주에 대한 i번째 관측치의 확률입니다.
연관성 측정
일치 및 불일치 쌍은 모형이 데이터를 얼마나 잘 예측하는지 나타냅니다. 일치 쌍이 많을수록 모형의 예측 능력이 더 우수합니다.
일치, 불일치 및 같은 값 쌍 표는 반응 값이 서로 다른 관측치의 모든 가능한 쌍을 구성하여 계산합니다. 반응 값이 1, 2, 3이라고 가정합니다. Minitab에서는 반응 값이 1인 모든 관측치를 반응 값이 2와 3인 모든 관측치와 짝지은 다음 반응 값이 2인 모든 관측치를 반응 값이 1과 3인 모든 관측치와 짝짓습니다. 쌍의 총 수는 반응 값이 1인 관측치 수 곱하기 반응 값이 2인 관측치 수 더하기 반응 값이 1인 관측치 수 곱하기 반응 값이 3인 관측치 수 더하기 반응 값이 2인 관측치 수 곱하기 반응 값이 3인 관측치 수입니다.
Minitab은 쌍이 일치 또는 불일치 쌍인지 확인하기 위해 각 관측치의 누적 예측 확률을 계산하고 해당 값을 각 관측치 쌍에 대해 비교합니다.
- 일치
- 가장 낮은 반응 값(위 예에서는 1)을 포함하는 쌍의 경우, 가장 낮은 반응 값까지의 누적 확률이 반응 값이 가장 작은 관측치보다 반응 값이 가장 높은 관측치보다 더 크면 일치 쌍입니다. 반응 값이 가장 높은 쌍(위 예에서는 반응 값이 2와 3인 쌍)의 경우 반응 값이 2인 관측치보다 반응 값이 3인 관측치에서 2까지의 누적 확률이 더 크면 일치 쌍입니다.
- 불일치
- 가장 낮은 반응 값(위 예에서는 1)을 포함하는 쌍의 경우, 가장 낮은 반응 값까지의 누적 확률이 반응 값이 더 큰 관측치보다 반응 값이 더 낮은 관측치보다 더 크면 불일치 쌍입니다. 반응 값이 가장 높은 쌍(위 예에서는 반응 값이 2와 3인 쌍)의 경우, 2까지의 누적 확률이 반응 값이 3인 관측치보다 반응 값이 2인 관측치에서 더 크면 불일치 쌍입니다.
- 같은 값
- 관측치들이 같은 누적 확률을 갖는 경우 같은 값을 갖는 쌍이라고 합니다.
공식
Minitab은 일치, 불일치 및 같은 값 쌍 표를 사용하여 다음 요약 측도를 계산합니다.


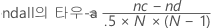
표기법
| 용어 | 설명 |
|---|---|
| nc | 일치 쌍의 수 |
| nd | 불일치 쌍의 수 |
| nt | 같은 값 쌍의 수 |
| N | 총 관측치 수 |