이탈도는 현재 모형과 전체 모형의 불일치를 측정합니다. 전체 모형은 관측치당 하나씩 총 n개의 모수가 있는 모형입니다. 전체 모형은 로그 우도 함수를 극대화합니다. 전체 모형은 모수가 n개 미만인 모형의 비교점이 됩니다. 전체 모형과 비교할 때는 척도화된 이탈도를 사용합니다.
각 개별 데이터 점이 척도화된 이탈도에 기여하는 정도는 모형에 따라 다릅니다.
모형
이탈도
이항 분포
포아송 분포
검정의 자유도는 표본 크기와 모형의 항 수에 따라 다릅니다.
표기법
용어
설명
Lf
전체 모형의 로그 우도
Lc
전체 모형 항의 부분 집합이 있는 모형의 로그 우도
yi
데이터의 i번째 행의 사건 수
데이터의 i번째 행의 추정 평균 반응
mi
데이터의 i번째 행의 시행 횟수
n
데이터의 행 수
p
회귀 자유도
Pearson
일반화된 Pearson 카이-제곱 통계량은 관측치와 적합치의 상대적인 차이를 평가합니다.
검정의 자유도는 표본 크기와 모형의 항 수에 따라 다릅니다. Pearson 통계량은 정규 데이터에 대해 정확 카이-제곱 분포를 갖습니다. 이항 분포 및 포아송 분포와 같은 비정규 데이터의 경우, 통계량은 분포를 비동시적으로 근사합니다.
표기법
용어
설명
n
데이터의 행 수
p
회귀 자유도
yi
i 번째 요인/공변량 패턴에 대한 반응 값
i번째 행의 추정 평균 반응
V(·)
아래에 정의된 모형의 분산 함수
분산 함수는 모형에 따라 다릅니다.
모형
분산 함수
이항 분포
포아송 분포
Hosmer-Lemeshow
추정된 확률을 기반으로 하는 그룹화 데이터 기반의 이항 반응이 포함된 모형에 대한 적합도 검정입니다. 관측 빈도와 추정된 기대 빈도의 2 × g 표의 카이-제곱 통계량으로, 여기서 g는 그룹의 수입니다. 검정에 대한 자유도는 g − 2입니다.
공식은 다음과 같습니다.
Minitab에서는 그룹을 형성하기 위해 추정 확률의 순서를 지정한 다음 크기가 같은 그룹 10개를 만들려고 시도합니다.

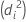
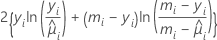
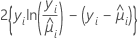

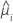
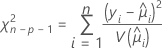
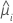
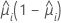
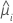
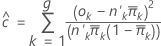
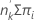

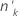
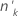 요인/공변량 패턴 중 사건의 수
요인/공변량 패턴 중 사건의 수