참고
이 명령은 예측 분석 모듈에서 사용할 수 있습니다. 모듈을 활성화하는 방법에 대한 자세한 내용은 여기를 클릭하십시오.
하나의 예측 변수 부분 종속성 플롯
x1,x2,..., x m로 표시된 학습 데이터 집합에 m 예측 변수가 있다고가정합니다. 먼저, 학습 데이터 집합에서 예측 변수 x1의 고유 값을 오름차순으로 정렬합니다. x 11을x1의첫 번째 고유 값으로 나타냅니다. 그런 다음 x11은 그림의 왼쪽 지점에 대한 x 좌표입니다.
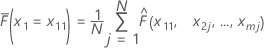
| 용어 | 설명 |
|---|---|
| N | 학습 데이터 집합의 전체 행 수 |
 | 에
대한 관측 값  학습 데이터 집합의 학습 데이터 집합의 |
| j | J 행의 각 개별 행 |
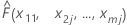 | x1 = x11, x2 = x2j,...., xm = xmj일 때 모형의 적합치 |
x11을 x1의 각 고유 값별로 교체하면 그림에 나머지 점에 대한 y 좌표가 표시됩니다. 나머지 예측 변수에 대한 계산도 유사하게 수행됩니다.
x의 모든 고유 값에 대한 모든 y 좌표 계산은 큰 데이터 집합에 시간이 많이 걸릴 수 있습니다. TreeNet®의 경우 더 빠르게 계산하는 방법이 있습니다. Refer to Friedman, J. H. (2001). Greedy function approximation: A gradient boosting machine. The Annals of Statistics, 29(5), page 1221.
다항 반응 사례에 대한 계산은 비슷합니다. 여기에서 적합치는 각 개별 클래스의 모형에서 나온 것입니다.
두 개의 예측 변수 부분 종속성 플롯 2개
x1,x2,..., x m로 표시된 학습 데이터 집합에 m 예측 변수가 있다고가정합니다. 먼저 학습 데이터 집합에서 예측 변수x1, x2의 고유 값을 오름차순으로 정렬합니다. x11, x21을 별개의 쌍 중 하나로 나타냅니다. 그런 다음 각 쌍은 표면도의 점에 대해 x 및 y 좌표를 만듭니다.
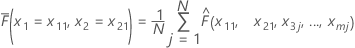
| 용어 | 설명 |
|---|---|
| N | x1 = x11, x2 = x21의 공통점을 공유하는 학습 데이터 집합의 전체 행 수 |
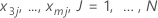 | 에
대한 관측 값 학습
데이터 집합의 학습
데이터 집합의 |
| j | J 행의 각 개별 행 |
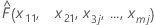 | x1 = x11, x2 = x21, x3 = x3j...., xm = xmj일 때 모형의 적합치 |
x1 및 x2의 모든 고유 값 조합에 대한 계산이 완료되면 윤곽도 또는 표면도에 대한 모든 z 좌표가 생성됩니다. 대용량 데이터 집합의 경우 모든 고유한 x 및 y 쌍의 계산에 시간이 많이 걸립니다. TreeNet® 모형의 경우 더 빠르게 계산하는 방법이 있습니다. Refer to Friedman, J. H. (2001). Greedy function approximation: A gradient boosting machine. The Annals of Statistics, 29(5), page 1221.