참고
이 명령은 예측 분석 모듈에서 사용할 수 있습니다. 모듈을 활성화하는 방법에 대한 자세한 내용은 여기를 클릭하십시오.
중요한 예측 변수
- 예측 변수가 노드를 분할할 때 평균 제곱 오류의 감소를 찾습니다.
- 예측 변수가 노드 스플리터인 모든 노드에서 모든 감소를 추가합니다.
그런 다음 예측 변수의 중요도 점수는 모든 트리에 걸쳐 모형 개선 점수의 합계와 같습니다.

이항 응답의 평균 -로그 우도
학습 데이터 또는 검증 없음
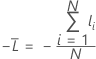
설명
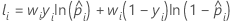
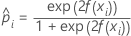
학습 데이터 표기법 또는 검증 없음
| 용어 | 설명 |
|---|---|
| N | 전체 또는 학습 데이터의 집합의 표본 크기 |
| wi | 전체 또는 학습 데이터 집합의 i번째 관측치에 대한 가중치 |
| yi | 사건에 대해 1이고 전체 또는 학습 데이터 집합에서 0인 i번째 반응 값 |
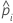 | 전체 또는 학습 데이터 세트의 i번째 행에 대한 사건의 예측 확률 |
 | 모형의 적합치 |
K-접기 교차 검증
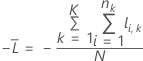
설명
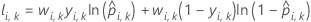

k-접기 교차 검증 표기법
| 용어 | 설명 |
|---|---|
| N | 전체 또는 학습 데이터의 표본 크기 |
| nk | 폴드 k의 표본 크기 |
| wi, k | 폴드 k에서 i번째 관측치에 대한 가중치 |
| yi, k | 폴드 k에서 i 사례의 이항 반응 값. yi, k = 사건 클래스의 경우 1, 그렇지 않으면 0. |
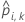 | 폴드 k에서 i 사례에 대한 예측 확률. 예측 확률은 폴드 k에서 데이터를 사용하지 않는 모형에서 나온 것입니다. |
 | 폴드 k에서 i 사례에 대한 적합치. 적합치는 폴드 k에서 데이터를 사용하지 않는 모형에서 나온 것입니다. |
검정 데이터 집합
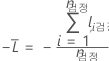
설명
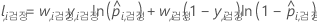

검정 데이터 집합 표기법
| 용어 | 설명 |
|---|---|
| nTest | 검정 데이터 집합의 표본 크기 |
| wi, Test | 검정 데이터 세트의 i번째 관측치에 대한 가중치 |
| yi, Test | 검정 데이터 집합의 폴드 k에서 i 사례의 이항 반응 값입니다. yi, k = 사건 클래스의 경우 1, 그렇지 않으면 0. |
 | 검정 데이터 집합에서 i 사례의 사건 예측 확률 |
 | 검정 데이터 집합에서 i 사례의 적합치 |
다항 반응의 평균 -로그 우도 확률
 은(는) 반응 변수의 수준 수입니다.
은(는) 반응 변수의 수준 수입니다. 학습 데이터 또는 검증 없음
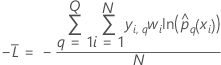
설명
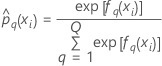
학습 데이터 표기법 또는 검증 없음
| 용어 | 설명 |
|---|---|
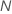 | 전체 또는 학습 데이터의 집합의 표본 크기 |
| wi | 전체 또는 학습 데이터 집합의 i번째 관측치에 대한 가중치 |
| yi, q | i번째 반응 값은 1 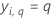 및 그렇지 않으면 0 및 그렇지 않으면 0 |
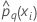 | 전체 또는 학습 데이터 학습에서 i번째 행에 대한 반응의 q번째 수준의 예측 확률 |
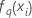 | 반응의 q번째 예측 확률을 계산하는 데 사용되는 i번째 행에 대한 트리의 q번째 시퀀스의 적합치 |
K-폴드 교차 검증
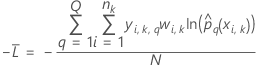
설명
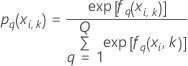
k-접기 교차 검증 표기법
| 용어 | 설명 |
|---|---|
| N | 학습 데이터의 표본 크기 |
| nk | 폴드 k의 표본 크기 |
| wi, k | 폴드 k에서 i번째 관측치에 대한 가중치 |
| yi, k, q | 폴드 k에서 i 사례의 i번째 반응 값은 1  및 그렇지 않으면 0. 및 그렇지 않으면 0. |
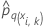 | 폴드 k에서 i번째 행에 대한 반응의 q번째 수준의 예측 확률 예측 확률은 폴드 k에서 데이터를 사용하지 않는 모형에서 나온 것입니다. |
 | 반응의 q번째 예측 확률을 계산하는 데 사용되는 폴드 k의 i번째 행에 대한 트리의 q번째 시퀀스의 적합치 적합치는 폴드 k에서 데이터를 사용하지 않는 모형에서 나온 것입니다. |
검정 데이터 집합
설명
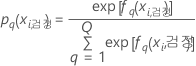
검정 데이터 집합 표기법
| 용어 | 설명 |
|---|---|
| n검정 | 검정 데이터 집합의 표본 크기 |
| wi, 검정 | 검정 데이터의 i번째 관측치에 대한 가중치 |
| yi, 검정, q | 검정 데이터 집합에서 i 사례의 i번째 반응 값은 1  및 그렇지 않으면 0. 및 그렇지 않으면 0. |
 | 검정 데이터에서 i번째 행에 대한 응답의 q번째 수준의 예측 확률. 예측 확률은 검정 데이터를 사용하지 않는 모형에서 나온 것입니다. |
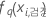 | 반응의 q번째 예측 확률을 계산하는 데 사용되는 검정 데이터에서 i번째 행에 대한 트리의 q번째 시퀀스의 적합치. 예측 확률은 검정 데이터를 사용하지 않는 모형에서 나온 것입니다. |
ROC 곡선 아래 면적
수식


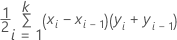
여기서 k는 고유한 사건 확률의 수이고 (x0, y0)은 점(0, 0)입니다.
검정 데이터 세트 또는 교차 검증된 데이터에서 곡선에 대한 면적을 계산하려면 해당 곡선의 점을 사용합니다.
표기법
| 용어 | 설명 |
|---|---|
| TPR | 진양성률 |
| FPR | 가양성률 |
| TP | 진양성, 올바르게 평가된 사건 |
| FN | 가음성, 잘못 평가된 사건 |
| P | 실제 긍정적인 사건의 수 |
| FP | 가양성, 잘못 평가된 비사건 |
| N | 실제 부정적인 사건 수 |
| FNR | 가음성률 |
| TNR | 진음성률 |
예제
| x(가양성률) | y(진양성률) |
|---|---|
| 0.0923 | 0.3051 |
| 0.4154 | 0.7288 |
| 0.7538 | 0.9322 |
| 1 | 1 |
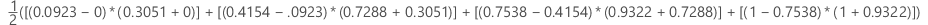

ROC 곡선 아래 면적에 대한 95% CI
다음 간격은 신뢰 구간에 대한 상한 및 하한을 제공합니다.
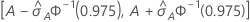
ROC 곡선 아래 면적의 표준 오차 계산(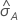 )은 Salford Predictive Modeler®에서 제공됩니다. ROC 곡선 아래의 면적 분산 추정에 대한 일반적인 정보는 다음 참조 자료를 참고하십시오.
)은 Salford Predictive Modeler®에서 제공됩니다. ROC 곡선 아래의 면적 분산 추정에 대한 일반적인 정보는 다음 참조 자료를 참고하십시오.
Engelmann, B. (2011). Measures of a ratings discriminative power: Applications and limitations. In B. Engelmann & R. Rauhmeier (Eds.), The Basel II Risk Parameters: Estimation, Validation, Stress Testing - With Applications to Loan Risk Management (2nd ed.) Heidelberg; New York: Springer. doi:10.1007/978-3-642-16114-8
Cortes, C. and Mohri, M. (2005). Confidence intervals for the area under the ROC curve. Advances in neural information processing systems, 305-312.
Feng, D., Cortese, G., & Baumgartner, R. (2017). 작은 표본 크기의 연속 진단 검정을 위해 ROC 곡선 아래의 면적에 대한 신뢰도/신뢰할 수 있는 구간 방법의 비교입니다. Statistical Methods in Medical Research, 26(6), 2603-2621. doi:10.1177/0962280215602040
표기법
| 용어 | 설명 |
|---|---|
| A | ROC 곡선 아래 면적 |
 | 표준 정규 분포의 0.975 백분위수 |
향상도
누적 향상도에 대한 일반적인 계산은 TreeNet® 분류를 통한 모형 적합 및 주요 예측 변수 검색에 대한 향상도 차트에 대한 방법 및 수식에서 확인하십시오.
오분류 비율
가중치가 있는 사례에서 개수 대신 가중 카운트를 사용합니다.

k-접기 교차 검증의 경우 오분류 카운트는 각 접기가 검정 데이터 세트인 오분류 합계입니다.
검정 데이터 세트를 사용한 검증에서 오분류 카운트는 검정 데이터 세트의 오분류 합계이며 전체 카운트는 검정 데이터 세트에 대한 것입니다.