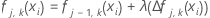TreeNet® 모형은 단일 분류 또는 회귀 트리보다 더 정확하고 과도 적합에 대한 내성이 더 높은 분류 및 회귀
분석 문제를 해결하기 위한 접근 방식입니다. 공정에 대한 광범위하고 일반적인 설명은 작은 회귀 트리를 초기 모형으로 시작한다는 것입니다. 해당
트리에서 다음 회귀 트리에 대한 반응 변수가 되는 데이터의 모든 행에 대한 잔차가 옵니다. 다른 작은 회귀 트리를 만들어 첫 번째 트리 잔차를
예측하고 결과 잔차를 다시 계산합니다. 최소 예측 오차가 있는 최적의 트리 수가 검증 방법을 사용하여 식별될 때까지 이 순서를 반복합니다.
결과 트리 순서는 TreeNet® 분류 모형을 만듭니다.
분류 사례의 경우 이항 반응을 사용하여 분석 및 다항 반응의 분석을 위해 몇 가지 수학적 세부 정보를 추가할 수 있습니다.
이항 반응
모형 생성에서는 다음 정보를 사용합니다.
반응 변수, ,
다음 값이 나옵니다: {-1, 1}.
일반화 잔차 계산을 위한 초기 적합치의 형식은 다음과
같습니다.
설명 은
사건 수이며 은
비사건 수입니다.
모형 생성에서는 분석가의 다음 입력도 사용합니다.
입력
기호
학습 속도
표본 비율
트리당 최대 단말 노드 수
트리 수
이 프로세스에는
j번째 트리,
j=1,...,J를 성장시키는 데 따르는 일반적인 단계가 있습니다.
학습 데이터에서 크기
s *
N의 임의 표본을 그립니다. 여기에서
N은 학습 데이터의 행 수입니다.
일반화 잔차,
gi, j를 계산합니다, 에 대한 :
설명
및 는
학습 데이터에서 예측 변수 값의
i번째 행을 나타내는 벡터입니다.
최대
M개 터미널 노드가 있는 회귀 트리를 일반화 잔차에 적합합니다. 트리는 관측치를 최대
M개의 상호 배타적 그룹으로 분할합니다.
회귀 트리의
m번째 단말 노드의 경우 다음과 같이 이전 트리의 적합치에 대한 노드 내 업데이트를 계산합니다.
설명
용어
설명
트리
j에서의 단말 노드
m에 있는 사건 수
트리
j에서의 단말 노드
m에 있는 사례 수
의 산술 평균
트리
j에서단말 노드
m의 모든 경우
학습 속도에 따라 노드 내 업데이트를 축소하고 값을
적용하여 업데이트된 반응 표면
fj, k(xi)를 가져옵니다.
분석에서 각
J의 트리에 대해 1~5단계를 반복합니다.
다항 반응
K 수준을 가진 다항 반응의 경우 분석은 각 반복의 각 반응 변수 수준에 트리를 적합합니다. 트리 중 하나에 대한 일반화 잔차 계산을
위한 초기 적합치의 형식은 다음과 같습니다.
설명 는
반응 값이
k이고
N이 학습 데이터의 행 수인 경우 사례 수입니다.
모형 생성에서는 분석가의 다음 입력도 사용합니다.
입력
기호
학습 속도
표본 비율
트리당 최대 단말 노드 수
트리 수
적합치의 확률 계산은 이 트리의 종속적 특성을 고려합니다. 그렇지 않으면 공정은 실질적으로 이항 사례와 동일합니다.
학습 데이터에서 크기
s *
N의 임의 표본을 그립니다. 여기에서
N은 학습 데이터 집합의 행 수입니다.
일반화 잔차,
gi, j, k를 계산합니다 에 대한 ,
, 분석에서 트리의 수,
그리고 , 반응 변수의 수준
수:
설명
및 는
학습 데이터 집합에서 예측 변수 값의
i번째 행을 나타내는 벡터입니다.
예를 들어 수준이 3개인 다항 반응에서 1로 코딩된 결과에 대한 확률의 형식은 다음과 같습니다.
설명 는
반응 변수의
q번째 수준에 대한
j–1 트리에서
k번째 행의 적합치입니다.
최대
M개 단말 노드가 있는 회귀 트리를 일반화 잔차에 적합합니다. 트리는 관측치를 최대
M개의 상호 배타적 그룹으로 분할합니다.
j번째 회귀 트리의
m번째 단말 노드의 경우 다음과 같이 이전 트리의 적합치에 대한 노드 내 업데이트를 계산합니다.
설명
용어
설명
트리
j에서의 단말 노드
m에 있는 결과
k에 대한 사례 수
트리
j에서의 단말 노드
m에 있는 사례 수
의 산술 평균 트리
j에서의 단말 노드
m에 대한.
학습 속도에 따라 노드 내 업데이트를 축소하고 값을
적용하여 업데이트된 반응 표면
fj, k, m(xi)를 가져옵니다.
분석에서
J 트리 중 각 트리에 대해 그리고 반응 변수의
K 수준 중 각 수준에 대해 1~5단계를 반복합니다.
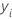 ,
다음 값이 나옵니다: {-1, 1}.
,
다음 값이 나옵니다: {-1, 1}.
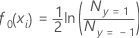
 은
사건 수이며
은
사건 수이며  은
비사건 수입니다.
은
비사건 수입니다.

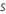
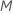
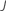
 :
: 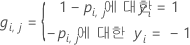

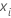 는
학습 데이터에서 예측 변수 값의
i번째 행을 나타내는 벡터입니다.
는
학습 데이터에서 예측 변수 값의
i번째 행을 나타내는 벡터입니다.
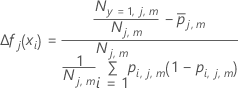 설명
설명

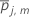
 트리
j에서단말 노드
m의 모든 경우
트리
j에서단말 노드
m의 모든 경우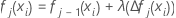
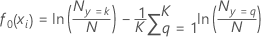
 는
반응 값이
k이고
N이 학습 데이터의 행 수인 경우 사례 수입니다.
는
반응 값이
k이고
N이 학습 데이터의 행 수인 경우 사례 수입니다.

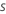
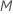
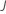
 ,
,
 , 분석에서 트리의 수,
그리고
, 분석에서 트리의 수,
그리고 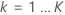 , 반응 변수의 수준
수:
, 반응 변수의 수준
수: 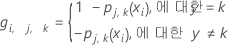
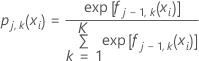
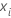 는
학습 데이터 집합에서 예측 변수 값의
i번째 행을 나타내는 벡터입니다.
예를 들어 수준이 3개인 다항 반응에서 1로 코딩된 결과에 대한 확률의 형식은 다음과 같습니다.설명
는
학습 데이터 집합에서 예측 변수 값의
i번째 행을 나타내는 벡터입니다.
예를 들어 수준이 3개인 다항 반응에서 1로 코딩된 결과에 대한 확률의 형식은 다음과 같습니다.설명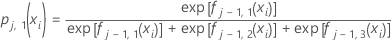
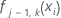 는
반응 변수의
q번째 수준에 대한
j–1 트리에서
k번째 행의 적합치입니다.
는
반응 변수의
q번째 수준에 대한
j–1 트리에서
k번째 행의 적합치입니다.
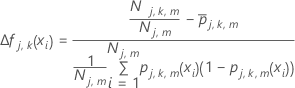
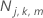

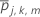
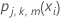 트리
j에서의 단말 노드
m에 대한.
트리
j에서의 단말 노드
m에 대한.