참고
이 명령은 예측 분석 모듈에서 사용할 수 있습니다. 모듈을 활성화하는 방법에 대한 자세한 내용은 여기를 클릭하십시오.
원하는 방법이나 수식을 선택합니다.
오차 행렬에는 모형의 분류 정확도에 대한 결과가 포함되어 있습니다. 대부분의 경우 행의 분류는 예측 확률이 가장 높은 반응 수준입니다. 예를 들어 이항 반응을 사용하면 사건의 예측 확률이 0.50을 초과할 때 행에 대한 분류가 사건 범주입니다. 그러나 이항 반응의 경우 0.50 이외의 임계값을 지정할 수 있습니다.
카운트
가중치가 없는 경우 개수와 표본 크기는 동일합니다.
가중 카운트
가중치가 있는 사례에서 가중 카운트는 범주에 대한 가중치의 합계입니다. 가중치를 사용하여 백분율과 비율을 계산합니다. 다음의 간단한 예를 고려해 보십시오.
| 반응 수준 | 예측 수준 | 가중치 |
|---|---|---|
| 예 | 예 | 0.1 |
| 예 | 예 | 0.2 |
| 예 | 아니요 | 0.3 |
| 예 | 아니요 | 0.4 |
| 아니요 | 아니요 | 0.5 |
| 아니요 | 아니요 | 0.6 |
| 아니요 | 예 | 0.7 |
| 아니요 | 예 | 0.8 |
이 표는 다음 통계를 제공합니다.
| 실제 클래스 | 가중 카운트 | 예측 클래스 = 예 | 예측 클래스 = 아니요 | 백분율 수정 |
|---|---|---|---|---|
| 예 | 0.1 + 0.2 + 0.3 + 0.4 = 1 | 0.1 + 0.2 = 0.3 | 0.3 + 0.4 = 0.7 | 0.3 / (0.3 + 0.7) ×100 = 30.00% |
| 아니요 | 0.5 + 0.6 + 0.7 + 0.8 = 2.6 | 0.7 + 0.8 = 1.5 | 0.5 + 0.6 = 1.1 | 1.1 / (1.5 + 1.1) × 100 = 42.31% |
| 모두 | 1 + 2.6 = 3.6 | 0.3 + 1.5 = 1.8 | 0.7 + 1.1 = 1.8 | (0.3 + 1.1) / 3.6 × 100 = 38.89% |
진양성률(민감도 또는 검정력)

가양성률(유형 I 오차)
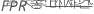
가음성률(유형 II 오차)
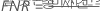
진음성률(특이성)
