참고
이 명령은 에서 사용할 수 있습니다예측 분석 모듈. 모듈을 활성화하는 방법에 대한 자세한 내용은 여기를 클릭하십시오.
연구원 팀은 심장병에 영향을 미치는 요인에 관하여 상세한 정보를 수집하고 게시합니다. 변수는 나이, 성별, 콜레스테롤 수치, 최대 심장 박동 등을 포함합니다. 이 예제는 심장병에 대한 자세한 정보를 제공하는 공개 데이터 세트를 기반으로 합니다. 원래 데이터는 archive.ics.uci.edu에서 볼 수 있습니다.
중요한 예측 변수를 식별하기 위해 초기 탐색 CART® 분류 후 연구원은 동일한 데이터 세트에서 더 집약적인 모델을 만들기 위해 와 TreeNet® 분류 를 모두 Random Forests® 분류 사용합니다. 연구원은 모형 요약 표와 결과의 ROC 그림을 비교하여 어떤 모형이 더 나은 예측 결과를 제공하는지 평가합니다. 다른 분석의 결과는 CART® 분류 예제 및 Random Forests® 분류 예제에서 확인하십시오.
- 표본 데이터 심장질환바이너리.MWX를 엽니다.
- 을 선택합니다.
- 드롭다운 목록에서 이항 반응을 선택합니다.
- 반응에 '심장 병'를 입력합니다.
- 반응 사건에서 환자에게 심장병이 확인되었음을 나타내려면 예를 선택합니다.
- 계량형 예측 변수 에는 연령, '나머지 혈압', 콜레스테롤, '최대 심박수', '올드 피크' 를 입력합니다..
- 범주형 예측 변수에는 섹스, '흉통 유형', '단식 혈당', '레스트 심전도', '운동 협 심 증', 경사, '주요 선박', 탈를 입력합니다.
- 확인을 클릭합니다.
결과 해석
이 분석을 위해 Minitab은 300개의 트리를 키우고 최적의 트리 수는 298개입니다. 최적의 트리 수가 모형이 키우는 최대 트리 수에 근접해지기 때문에 연구원들은 더 많은 트리로 분석을 반복합니다.
모형 요약
| 전체 예측 변수 | 13 |
|---|---|
| 중요 예측 변수 | 13 |
| 성장한 트리 수 | 300 |
| 최적의 트리 수 | 298 |
| 통계량 | 교육 | 검정 |
|---|---|---|
| 평균 음수 로그 우도 | 0.2556 | 0.3881 |
| ROC 곡선 아래 면적 | 0.9796 | 0.9089 |
| 95% CI | (0.9664, 0.9929) | (0.8759, 0.9419) |
| 향상도 | 2.1799 | 2.1087 |
| 오분류 비율 | 0.0891 | 0.1617 |
500개의 트리가 있는 예
- 결과에서 하이퍼파라미터 튜닝 를 선택합니다.
- 트리 수에 500를 입력합니다.
- 결과 표시을 클릭합니다.
결과 해석
이 분석을 위해 500개의 트리가 자라고 최적의 트리 수는 351개였습니다. 최상의 모형은 학습 속도 0.01을 사용하고, 0.5의 하위 표본 부분을 사용하며, 6을 최대 단말 노드 수로 사용합니다.
방법
| 최적 트리 수 선택 기준 | 최대 로그 우도 |
|---|---|
| 모형 검증 | 5-접기 교차 검증 |
| 학습률 | 0.01 |
| 하위 표본 선택 방법 | 완전 랜덤 |
| 하위 표본 부분 | 0.5 |
| 트리당 최대 터미널 노드 수 | 6 |
| 최소 단말 노드 크기 | 3 |
| 노드 분할을 위해 선택된 예측 변수 수 | 총 예측 변수 수 = 13 |
| 사용된 행 | 303 |
이항 반응 정보
| 변수 | 등급 | 카운트 | % |
|---|---|---|---|
| 심장 병 | 예 (사건) | 139 | 45.87 |
| 아니요 | 164 | 54.13 | |
| 모두 | 303 | 100.00 |
방법
| 최적 트리 수 선택 기준 | 최대 로그 우도 |
|---|---|
| 모형 검증 | 5-접기 교차 검증 |
| 학습률 | 0.001, 0.01, 0.1 |
| 하위 표본 부분 | 0.5, 0.7 |
| 트리당 최대 터미널 노드 수 | 6 |
| 최소 단말 노드 크기 | 3 |
| 노드 분할을 위해 선택된 예측 변수 수 | 총 예측 변수 수 = 13 |
| 사용된 행 | 303 |
이항 반응 정보
| 변수 | 등급 | 카운트 | % |
|---|---|---|---|
| 심장 병 | 예 (사건) | 139 | 45.87 |
| 아니요 | 164 | 54.13 | |
| 모두 | 303 | 100.00 |
하이퍼파라미터 최적화
| 모형 | 최적의 트리 수 | 평균 음수 로그 우도 | ROC 곡선 아래 면적 | 분류 율 잘못 | 학습률 | 하위 표본 부분 | 최대 단말 노드 |
|---|---|---|---|---|---|---|---|
| 1 | 500 | 0.542902 | 0.902956 | 0.171749 | 0.001 | 0.5 | 6 |
| 2* | 351 | 0.386536 | 0.908920 | 0.175027 | 0.010 | 0.5 | 6 |
| 3 | 33 | 0.396555 | 0.900782 | 0.161694 | 0.100 | 0.5 | 6 |
| 4 | 500 | 0.543292 | 0.894178 | 0.178142 | 0.001 | 0.7 | 6 |
| 5 | 374 | 0.389607 | 0.906620 | 0.165082 | 0.010 | 0.7 | 6 |
| 6 | 39 | 0.393382 | 0.901399 | 0.174973 | 0.100 | 0.7 | 6 |
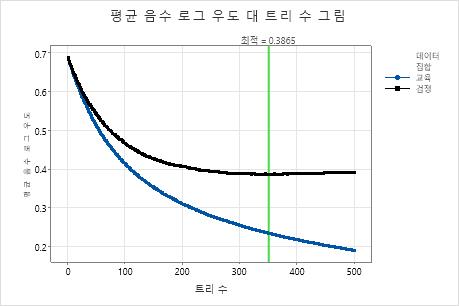
평균 – 로그우도 대 트리 수 그림은 성장한 트리 수에 대한 전체 곡선을 보여줍니다. 검정 데이터에 대한 최적의 값은 트리 수가 351인 경우 0.3865입니다.
모형 요약
| 전체 예측 변수 | 13 |
|---|---|
| 중요 예측 변수 | 13 |
| 성장한 트리 수 | 500 |
| 최적의 트리 수 | 351 |
| 통계량 | 교육 | 검정 |
|---|---|---|
| 평균 음수 로그 우도 | 0.2341 | 0.3865 |
| ROC 곡선 아래 면적 | 0.9825 | 0.9089 |
| 95% CI | (0.9706, 0.9945) | (0.8757, 0.9421) |
| 향상도 | 2.1799 | 2.1087 |
| 오분류 비율 | 0.0759 | 0.1750 |
모형 요약
| 전체 예측 변수 | 13 |
|---|---|
| 중요 예측 변수 | 13 |
| 통계량 | OOB |
|---|---|
| 평균 음수 로그 우도 | 0.4004 |
| ROC 곡선 아래 면적 | 0.9028 |
| 95% CI | (0.8693, 0.9363) |
| 향상도 | 2.1079 |
| 오분류 비율 | 0.1848 |
모형 요약 표는 트리 수가 351일 때 평균 음수 로그 우도가 학습 데이터에 대해 약 0.23이며 검정 데이터에 대해 약 0.39임을 보여줍니다. 이러한 통계는 Minitab Random Forests®에서 만드는 모형과 유사한 모형을 나타냅니다. 오분류 비율도 비슷합니다.
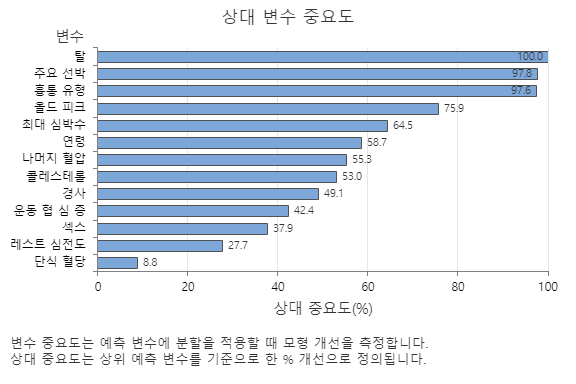
상대 변수 중요도 그래프는 트리 시퀀스에 대한 예측 변수에 분할이 이루어질 때 모형 개선에 미치는 영향 순으로 예측 변수를 표시합니다. 가장 중요한 예측 변수는 Thal입니다. 상위 예측 변수인 Thal의 기여도가 100%인 경우 다음으로 중요한 변수인 주요 출혈은 97.8%의 기여도를 가집니다. 이것은 주요 출혈이 이 분류 모형의 Thal만큼 중요한 97.8%임을 의미합니다.
오차 행렬
| 예측된 등급(교육) | 예측된 등급(검정) | ||||||
|---|---|---|---|---|---|---|---|
| 실제 등급 | 카운트 | 예 | 아니요 | 정답률(%) | 예 | 아니요 | 정답률(%) |
| 예 (사건) | 139 | 124 | 15 | 89.21 | 110 | 29 | 79.14 |
| 아니요 | 164 | 8 | 156 | 95.12 | 24 | 140 | 85.37 |
| 모두 | 303 | 132 | 171 | 92.41 | 134 | 169 | 82.51 |
| 통계량 | 교육(%) | 검정(%) |
|---|---|---|
| 진양성률(민감도 또는 검정력) | 89.21 | 79.14 |
| 가양성률(유형 I 오차) | 4.88 | 14.63 |
| 가음성률(유형 II 오차) | 10.79 | 20.86 |
| 진음성률(특이성) | 95.12 | 85.37 |
오차 행렬은 모형이 등급을 올바르게 구분하는 방법을 보여줍니다. 이 예제에서 사건이 올바르게 예측될 확률은 79.14%입니다. 비사건이 올바르게 예측될 확률은 85.37%입니다.
오분류
| 교육 | 검정 | ||||
|---|---|---|---|---|---|
| 실제 등급 | 카운트 | 오분류됨 | 오차율(%) | 오분류됨 | 오차율(%) |
| 예 (사건) | 139 | 15 | 10.79 | 29 | 20.86 |
| 아니요 | 164 | 8 | 4.88 | 24 | 14.63 |
| 모두 | 303 | 23 | 7.59 | 53 | 17.49 |
오분류 비율은 모형이 새 관측치를 정확하게 예측할지 여부를 나타내는 데 도움이 됩니다. 사건 예측의 경우 검정 오분류 오차는 20.86%입니다. 비사건 예측의 경우 오분류 오류는 14.63%이며 전체적으로 오분류 오차는 17.49%입니다.
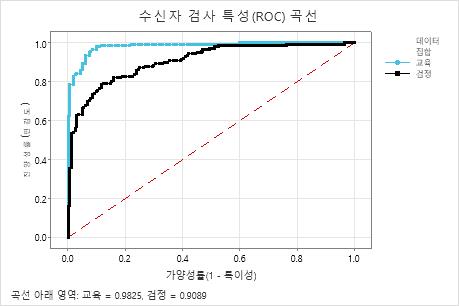
351개의 트리 수가 351일 때 ROC 곡선 아래의 면적은 학습 데이터에 대해 약 0.98이며 검정 데이터에 대해 약 0.91입니다. 이것은 모델에 비해 좋은 개선을 CART® 분류 보여줍니다. Random Forests® 분류 모델의 테스트 AUROC는 0.9028이므로 이 두 가지 방법은 비슷한 결과를 제공합니다.
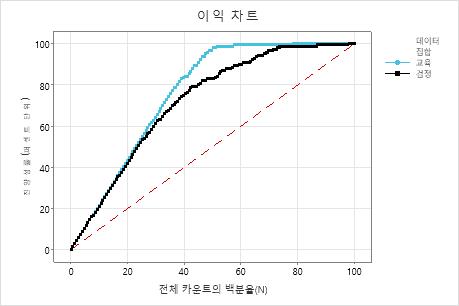
이 예제에서 이익 차트는 기준선 위로 급격히 증가한 다음 평평해집니다. 이 경우 데이터의 약 40%가 진양성의 약 80%를 차지합니다. 이 차이는 모형을 사용하여 산출된 추가 이득입니다.
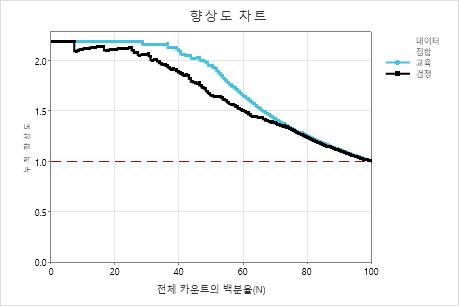
이 예제에서는 향상도 차트가 기준선 위로 크게 증가하고 점차 떨어집니다.
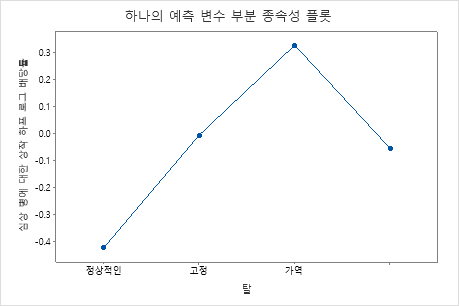
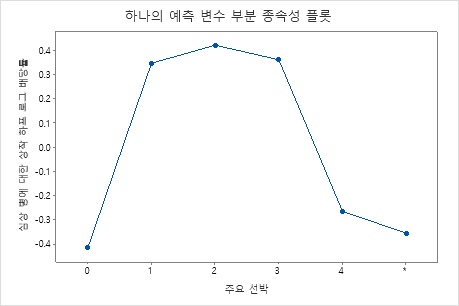
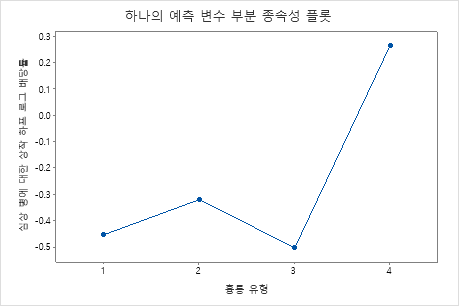
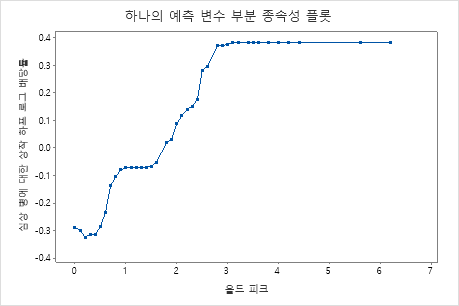
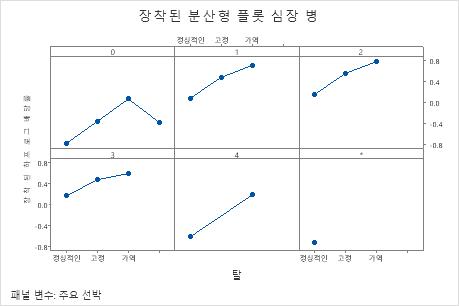
부분 종속성도를 사용하면 중요한 변수 또는 변수 쌍이 적합 반응 값에 어떤 영향을 미치는지 파악할 수 있습니다. 적합된 반응 값은 1/2 로그 척도에 있습니다. 부분 종속성 플롯은 반응과 변수 간의 관계가 선형, 단조로움 또는 더 복잡한지 여부를 보여줍니다.
예를 들어, 흉통 유형의 부분 종속성 플롯에서 1/2 로그 승산비는 달라지고 급격하게 증가합니다. 흉통 유형이 4인 경우 심장병 발생률의 1/2 로그 승산비는 약 -0.04에서 0.03으로 증가합니다. 또는 를 선택하여 다른 변수에 대한 그림을 생성합니다.