검정 집합을 사용한 검증을 OOB 검증에 추가하는 경우 학습 집합 및 검정 집합에 대한 별도의 통계가 표에 포함됩니다.
N
검정 집합을 사용한 검증을 추가할 때 이 통계가 표에 포함됩니다. 숫자는 검정 및 학습 집합에 누락되지 않은 반응 값의 수입니다.
N의 비율(%)
검정 집합을 사용한 검증을 추가할 때 이 통계가 표에 포함됩니다. 숫자는 학습 데이터 집합에 있고 검정 데이터 집합에 있는 관측치 백분율입니다.
평균
일반적으로 사용되는 숫자 배치의 중앙 측정입니다. 평균은 평균이라고도 합니다. 모든 관측치의 합을 (비결측) 관측치 수로 나눈 값입니다.
StDev
데이터 집합에 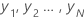 평균
평균 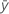 인 경우 표본의 표준 편차는 다음과 같습니다.
인 경우 표본의 표준 편차는 다음과 같습니다.

평균 인 경우 표본의 표준 편차는 다음과 같습니다.
| 용어 | 설명 |
|---|---|
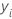 | 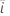 관측치 관측치 |
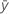 | 관측치의 평균 |
| N | 비결측 관측치 수 |
최소값
데이터 집합에서 가장 작은 값입니다.
Q1
표본 관측치의 25%가 제1 사분위수 값보다 작거나 같습니다. 따라서 제1 사분위수를 25번째 백분위수라고도 합니다.
중위수
표본 중위수는 데이터의 중간에 있습니다.
N 값이 포함된 데이터 집합이 있다고 가정합니다. 중위수를 계산하려면 먼저 데이터를 가장 작은 값에서 가장 큰 값 순으로 정렬하십시오. N이 홀수이면 표본 중위수는 중간에 있는 값입니다. N이 짝수이면 표본 중위수는 중간에 있는 두 값의 평균입니다.
Q3
표본 관측치의 75%가 제3 사분위수 값보다 작거나 같습니다. 따라서 제3 사분위수를 75번째 백분위수라고도 합니다.
최대값
데이터 집합에서 가장 큰 값입니다.