참고
이 명령은 예측 분석 모듈에서 사용할 수 있습니다. 모듈을 활성화하는 방법에 대한 자세한 내용은 여기를 클릭하십시오.
중요한 변수
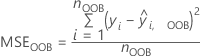
| 용어 | 설명 |
|---|---|
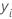 | 행 i에 대한 반응 변수값 |
 | 전체 포리스트에 대한 OOB 데이터에 표시되는 번호 행 |
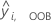 | 행 i에 대한 OOB 예측 |
그런 다음, OOB 데이터를 통해 변수의 값 xm을 임의로 순열합니다. 응답 값과 다른 예측 변수 값을 동일하게 둡니다. 그런 다음 동일한 단계를 사용하여 순열된 데이터에 대한 평균 제곱 오차를 계산합니다.  까지 평가할 예측 변수의 다양한 수를 선택할 수 있는 옵션이 있습니다.
까지 평가할 예측 변수의 다양한 수를 선택할 수 있는 옵션이 있습니다.
변수 x m의 중요성은 두 평균 제곱 오차의 차이에서 비롯됩니다.

Minitab은 10–7보다 작은 값을 0으로 반올림합니다.

OOB 및 검정 예측
모형 정확도의 다음 측정값에 대한 예측 계산은 검증 방법에 따라 다릅니다. OOB 예측은 행이 OOB인 트리에서만 나옵니다. 지정된 트리의 경우 j는 분석에서 트리를 사용하여 OOB 데이터를 예측합니다. 포리스트의 모든 트리에 대한 예측을 반복합니다. 그런 다음 OOB 데이터에 한 번 이상 나타나는 각 행의 OOB 예측 평균을 계산합니다. OOB 데이터를 사용한 모형의 평가의 경우 반응 변수의 평균은 OOB 데이터의 모든 행에 걸쳐 평균입니다.
검정 데이터 집합의 경우 포리스트의 각 트리를 사용하여 검정 데이터 집합의 각 값을 예측합니다. 그런 다음 모든 트리의 예측을 평균하여 모형에 대한 예측을 가져옵니다. 검정 집합을 사용한 모형 평가의 경우 평균 반응은 검정 집합의 행 평균입니다.
R-제곱
R2의 계산은 OOB 데이터 또는 검정 데이터를 사용합니다. 예측은 이 두 경우에 다릅니다. 일반적으로 R2에 대한 공식에는 다음과 같은 양식이 있습니다.

루트 평균 제곱 오차(RMSE)

평균 제곱 오차(MSE)
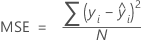
평균 절대 편차(MAD)
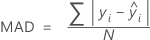
평균 절대 백분율 오차(MAPE)

표기법
| 용어 | 설명 |
|---|---|
| yi | 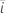 관측된 반응 값 관측된 반응 값 |
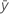 | 평균 반응 |
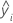 | 에 대한 예측 반응 값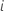 |
| N | 행 수 |