참고
이 명령은 에서 사용할 수 있습니다예측 분석 모듈. 모듈을 활성화하는 방법에 대한 자세한 내용은 여기를 클릭하십시오.
Random Forests® 모형은 분류 및 회귀 문제를 해결하기 위한 접근 방식입니다. 이 접근 방식은 단일 분류 또는 회귀 트리보다 예측 변수의 변화에 보다 정확하고 강력합니다. Minitab Statistical Software가 부트스트랩 모형에서 단일 트리를 빌드한다는 것이 프로세스에 대한 광범위하고 일반적인 설명입니다. Minitab은 전체 예측 변수 수 가운데 적은 수의 예측 변수를 임의로 선택하여 각 노드에서 최고의 스플리터를 평가합니다. Minitab은 많은 트리를 성장시키기 위해 이 과정을 반복합니다. 회귀의 경우 모형의 예측은 모든 개별 트리의 예측 평균입니다.
회귀 트리를 빌드하기 위해 알고리즘은 최소 제곱 기준을 사용하여 노드의 불순도를 측정합니다. 데스크톱 응용 프로그램의 경우 노드를 분할할 수 없거나 노드가 내부 노드를 분할할 수 있는 최소 사례 수에 도달할 때까지 각 트리가 커집니다. 최소 케이스 수는 분석을 위한 옵션입니다. 웹 앱에서 분석은 각 트리에 4,000개의 터미널 노드 제한이 있다는 제약 조건을 추가합니다. 회귀 트리의 구성에 대한 자세한 내용은 CART® 회귀 분석의 노드 분할 방법(으)로 이동하십시오. Random Forests®에 대한 특정 세부 정보가 따릅니다.
부트스트랩 표본
각 트리를 빌드하기 위해 알고리즘은 전체 데이터 집합에서 대체(부트스트랩 표본)이 있는 랜덤 표본을 선택합니다. 일반적으로 각 부트스트랩 표본은 다르며 원본 데이터 집합과 다른 수의 고유한 행을 포함할 수 있습니다. OOB 검증만 사용하는 경우 부트스트랩 표본의 기본 크기는 원본 데이터 집합의 크기입니다. 표본을 학습 집합 및 검정 집합으로 나누는 경우 부트스트랩 표본의 기본 크기는 학습 집합의 크기와 동일합니다. 어느 경우이든, 부트스트랩 표본이 기본 크기보다 작다는 것을 명시할 수 있는 옵션이 있습니다. 평균적으로 부트스트랩 표본에는 데이터 행의 약 2/3가 포함되어 있습니다. 부트스트랩 표본에 없는 고유한 데이터 행은 검증을 위한 OOB 데이터입니다.
예측 변수의 임의 선택
트리의 각 노드에서 알고리즘은 전체 예측 변수 수의 하위 집합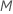 을 임의로 선택하여 스플리터로 평가합니다. 기본적으로 알고리즘은
을 임의로 선택하여 스플리터로 평가합니다. 기본적으로 알고리즘은  예측 변수를 선택하여 각 노드에서 평가합니다. 1에서
예측 변수를 선택하여 각 노드에서 평가합니다. 1에서 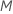 . 를 선택하는 경우
. 를 선택하는 경우 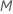 예측 변수를 선택하는 경우 알고리즘이 모든 노드에서 예측 변수를 평가하여 "부트스트랩 포리스트"라는 이름의 분석을 생성합니다.
예측 변수를 선택하는 경우 알고리즘이 모든 노드에서 예측 변수를 평가하여 "부트스트랩 포리스트"라는 이름의 분석을 생성합니다.
각 노드에서 예측 변수의 하위 집합을 사용하는 분석에서 평가된 예측 변수는 일반적으로 각 노드에서 다릅니다. 예측 변수가 다른 평가를 하면 포리스트의 트리가 서로 상관계수가 낮아집니다. 상관 관계가 적은 트리는 느린 학습 효과를 생성하여 더 많은 트리를 빌드할수록 예측이 개선됩니다.
OOB 데이터를 사용한 검증
지정된 트리의 트리 빌드 프로세스의 일부가 아닌 고유한 데이터 행은 OOB 데이터입니다. 모형 성능 측정에 대한 계산은 OOB 데이터를 사용합니다. 자세한 내용은 Random Forests® 회귀 분석의 모형 요약에 대한 방법 및 수식(으)로 이동하십시오.
포리스트에 지정된 트리의 경우 OOB 데이터의 행에 대한 예측은 단일 트리에서 형성됩니다. OOB 데이터의 행에 대한 예측은 개별 트리의 예측 평균입니다.
학습 집합의 행에 대한 예측
포리스트의 각 트리는 학습 집합의 모든 행에 대해 개별 예측을 합니다. 학습 집합의 행에 대한 예측 값은 포리스트에 있는 모든 트리의 예측 값의 평균입니다.