참고
이 명령은 에서 사용할 수 있습니다 예측 분석 모듈. 모듈을 활성화하는 방법에 대한 자세한 내용은 여기를 클릭하십시오.
모델을 만든 후 최고의 모형 검색(계량형 반응)대체 모형 선택 클릭하여 다른 모델을 탐색할 수 있습니다. 랜덤 포리스트 ® 모델을 선택하는 경우 한 가지 옵션은 새 모델에 맞게 하이퍼매개변수를 지정하는 것입니다. 하이퍼매개변수를 지정하면 결과에 하이퍼매개변수 테이블의 최적화가 포함됩니다. 표는 하이퍼파라미터의 조합을 비교합니다. 하이퍼파라미터 테이블의 최적화를 따르는 결과는 최대 R2같은 최적 기준기준을 가장 잘 값인 모델에 대한 것입니다.
결정계수
R2는 모형에서 설명하는 반응의 변동 비율입니다.
해석
R2 결정계수를 사용하여 모형이 데이터를 얼마나 적합시키는지 확인합니다. R2 결정계수 값이 높을수록 모형이 데이터를 더 잘 적합시킵니다. R2 결정계수는 항상 0%에서 100% 사이입니다.
참고
Random Forests®는 OOB 데이터를 사용하여 R2계산하지만 모형을 적합하지 않기 때문에 모형이 과도 적합해도 문제가 되지 않습니다.
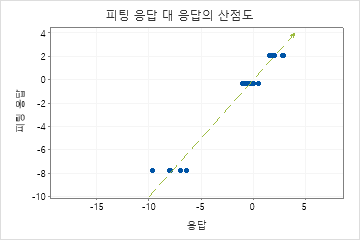
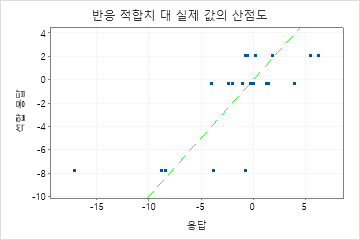
평균 절대 편차(MAD)
평균 절대 편차(MAD)는 데이터와 동일한 단위로 정확도를 표현하므로 오차 양을 개념화하는 데 도움이 됩니다. 특이치는 R2보다 MAD에 미치는 영향이 적습니다.
해석
다른 모형의 적합을 비교하는 데 사용합니다. 값이 작을수록 더 잘 적합함을 나타냅니다.
노드 분할예측변수 수
이 행은 고려해야 할 예측 변수 수의 선택을 나타냅니다.
최소 내부 노드 크기
최소 내부 노드 크기는 노드가 가질 수 있고 더 많은 노드로 분할될 수 있는 최소 사례 수를 나타냅니다.
부트스트랩 표본 수
부트스트랩 표본 수는 분석의 트리 수를 나타냅니다.