참고
이 명령은 에예측 분석 모듈서 사용할 수 있습니다. 모듈을 활성화하는 방법에 대한 자세한 내용은 여기를 클릭하십시오.
이 항목의 내용
최상의 모델 유형 검색
연구원 팀은 심장병에 영향을 미치는 요인에 관하여 상세한 정보를 수집하고 게시합니다. 변수는 나이, 성별, 콜레스테롤 수치, 최대 심장 박동 등을 포함합니다. 이 예제는 심장병에 대한 자세한 정보를 제공하는 공개 데이터 세트를 기반으로 합니다. 원래 데이터는 archive.ics.uci.edu에서 볼 수 있습니다.
연구원들은 가능한 가장 정확한 예측을 할 수 있는 모델을 찾고 싶어합니다. 연구원들은 최고의 모형 검색(이항 반응)를 사용하여 4가지 유형의 모델(이진 로지스틱 회귀, TreeNet®, Random Forests® 및 CART®)의 예측 성능을 비교합니다. 연구원들은 최고의 예측 성능을 가진 모델 유형을 더 자세히 탐구할 계획입니다.
- 표본 데이터 심장병바이너리최고의모델.MWX를 엽니다.
- 을 선택합니다.
- 반응에, '심장 병'를 입력합니다.
- 계량형 예측 변수에 , 연령, '나머지 혈압', 콜레스테롤, '최대 심박수', 및 ' 올드 피크‘ 를 입력합니다.
- 범주형 예측 변수에 섹스, ' 흉통 유형', '단식 혈당', '레스트 심전도', '운동 협 심 증', 경사, '주요 선박', 및 탈를 입력합니다.
- 확인을 클릭합니다.
결과 해석
모델 선택 테이블은 다양한 모델 유형의 성능을 비교합니다. Random Forests® 모델은 평균 – 로그 우도의 최소값을 갖습니다. 다음 결과는 최상의 Random Forests® 모델에 대한 것입니다.
오분류 비율 대 트리 수 그림은 성장한 트리 수에 대한 전체 곡선을 보여줍니다. 오분류 비율은 약 0.16입니다.
모형 요약 표는 평균 음의 로그 우도가 약 0.39임을 보여줍니다.
상대 변수 중요도 그래프는 트리 시퀀스에 대한 예측 변수에 분할이 이루어질 때 모형 개선에 미치는 영향 순으로 예측 변수를 표시합니다. 가장 중요한 예측 변수는 Thal입니다. 상위 예측 변수인 Thal의 기여도가 100%인 경우 다음으로 중요한 변수인 주요 출혈은 98.9%의 기여도를 가집니다. 이것은 주요 출혈이 이 분류 모형의 Thal만큼 중요한 98.9%임을 의미합니다.
혼동행렬은 모델이 클래스를 얼마나 올바르게 분리하는지 보여줍니다. 이 예에서 이벤트가 올바르게 예측될 확률은 약 87%입니다. 비사건이 올바르게 예측될 확률은 약 81%입니다.
오분류 비율은 모형이 새 관측치를 정확하게 예측하는지 여부를 나타내는 데 도움이 됩니다. 사건 예측의 경우 OOB 오차 오차는 약 13%입니다. 비사건 예측의 경우 오분류 오차는 약 19%입니다. 전체적으로 검정 데이터의 오분류 오류는 약 16%입니다.
Random Forests® 모델의 ROC 곡선 아래 영역은 Out-of-bag 데이터의 경우 약 0.90입니다.
방법
| 선형 항 및 순서 2의 항이 포함된 단계적 로지스틱 회귀 모델을 적합합니다. |
|---|
| 6 TreeNet® 분류 모델을 적합합니다. |
| 교육 데이터 크기 303과(와) 동일한 부트스트랩 표본 크기로 3 Random Forests® 분류 모델을 적합합니다. |
| 최적의 CART® 분류 모델을 적합합니다. |
| 5 접기 교차 검증에서 최대 로그 우도가 있는 모델을 선택합니다. |
| 행의 총 수: 303 |
| 로지스틱 회귀 모형에 사용되는 행: 303 |
| 트리 기반 모형에 사용되는 행: 303 |
이항 반응 정보
| 변수 | 등급 | 카운트 | % |
|---|---|---|---|
| 심장 병 | 1 (사건) | 165 | 54.46 |
| 0 | 138 | 45.54 | |
| 모두 | 303 | 100.00 |
| 유형 내에서 최고의 모형 | 평균 음수 로그 우도 | ROC 곡선 아래 면적 | 분류 율 잘못 |
|---|---|---|---|
| Random Forests®* | 0.3904 | 0.9048 | 0.1584 |
| TreeNet® | 0.3907 | 0.9032 | 0.1520 |
| 로지스틱 회귀 | 0.4671 | 0.9142 | 0.1518 |
| CART® | 1.8072 | 0.7991 | 0.2080 |
최고의 Random Forests® 모형에 대한 하이퍼파라미터
| 부트스트랩 표본 수 | 300 |
|---|---|
| 표본 크기 | 학습 데이터 크기 303과 동일 |
| 노드 분할을 위해 선택된 예측 변수 수 | 총 예측 변수 수의 제곱근 = 3 |
| 최소 내부 노드 크기 | 8 |
모형 요약
| 전체 예측 변수 | 13 |
|---|---|
| 중요 예측 변수 | 13 |
| 통계량 | OOB |
|---|---|
| 평균 음수 로그 우도 | 0.3904 |
| ROC 곡선 아래 면적 | 0.9048 |
| 95% CI | (0.8706, 0.9389) |
| 향상도 | 1.7758 |
| 오분류 비율 | 0.1584 |
오차 행렬
| 예측 등급(OOB) | ||||
|---|---|---|---|---|
| 실제 등급 | 카운트 | 1 | 0 | 정답률(%) |
| 1 (사건) | 165 | 143 | 22 | 86.67 |
| 0 | 138 | 26 | 112 | 81.16 |
| 모두 | 303 | 169 | 134 | 84.16 |
| 통계량 | OOB(%) |
|---|---|
| 진양성률(민감도 또는 검정력) | 86.67 |
| 가양성률(유형 I 오차) | 18.84 |
| 가음성률(유형 II 오차) | 13.33 |
| 진음성률(특이성) | 81.16 |
오분류
| OOB | |||
|---|---|---|---|
| 실제 등급 | 카운트 | 오분류됨 | 오차율(%) |
| 1 (사건) | 165 | 22 | 13.33 |
| 0 | 138 | 26 | 18.84 |
| 모두 | 303 | 48 | 15.84 |
대체 모형 선택
연구원은 최상의 모델을 찾기 위해 다른 모델에 대한 결과를 볼 수 있습니다. TreeNet® 모델의 경우 검색에 포함된 모델에서 선택하거나 다른 모델에 대한 하이퍼파라미터를 지정할 수 있습니다.
- 대체 모델 선택을 선택합니다.
- 모형 유형에서 TreeNet®를 선택합니다.
- 에서 기존 모형 선택최소 평균 -loglikelihood의 가장 좋은 값을 가진 세 번째 모델을 선택합니다.
- 결과 표시을 클릭합니다.
결과 해석
이 분석에서는 300그루의 나무를 키우며 최적의 나무 수는 46개입니다. 이 모델은 학습률 0.1과 하위 표본 부분 0.5을 사용합니다. 트리당 최대 터미널 노드 수는 6개입니다.
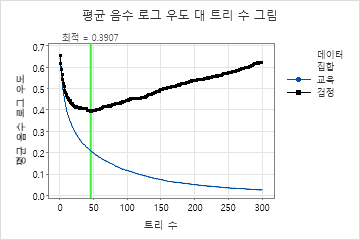
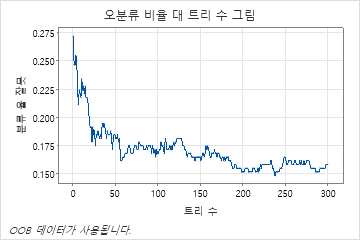
평균 – 로그우도 대 트리 수 그림은 성장한 트리 수에 대한 전체 곡선을 보여줍니다. 검정 데이터에 대한 최적의 값은 트리 수가 46인 경우 0.3907입니다.
모형 요약
| 전체 예측 변수 | 13 |
|---|---|
| 중요 예측 변수 | 13 |
| 성장한 트리 수 | 300 |
| 최적의 트리 수 | 46 |
| 통계량 | 교육 | 검정 |
|---|---|---|
| 평균 음수 로그 우도 | 0.2088 | 0.3907 |
| ROC 곡선 아래 면적 | 0.9842 | 0.9032 |
| 95% CI | (0.9721, 0.9964) | (0.8683, 0.9381) |
| 향상도 | 1.8364 | 1.7744 |
| 오분류 비율 | 0.0726 | 0.1520 |
트리 수가 46개인 경우 모형 요약 표는 평균 음의 로그 우도가 학습 데이터의 경우 약 0.21이고 검정 데이터의 경우 약 0.39임을 나타냅니다.
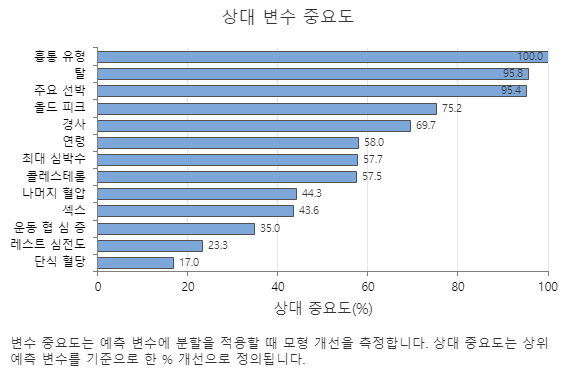
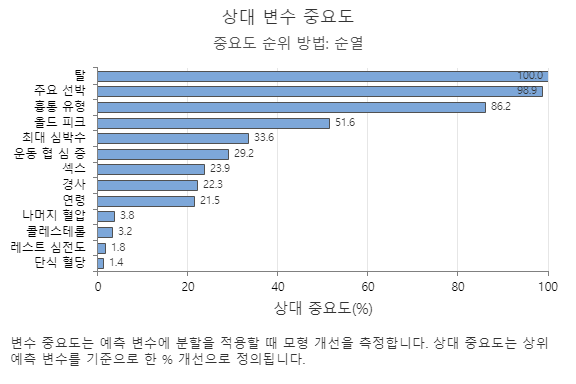
상대 변수 중요도 그래프는 트리 시퀀스에 대한 예측 변수에 분할이 이루어질 때 모형 개선에 미치는 영향 순으로 예측 변수를 표시합니다. 가장 중요한 예측 변수는 흉통 유형입니다. 상위 예측 변수인 흉통 유형(Chest Pain Type)의 기여도가 100%인 경우 다음으로 중요한 변수인 Thal의 기여도는 95.8%입니다. 이는 이 분류 모델에서 Thal이 흉통 유형보다 95.8% 중요하다는 것을 의미합니다.
오차 행렬
| 예측된 등급(교육) | 예측된 등급(검정) | ||||||
|---|---|---|---|---|---|---|---|
| 실제 등급 | 카운트 | 1 | 0 | 정답률(%) | 1 | 0 | 정답률(%) |
| 1 (사건) | 165 | 156 | 9 | 94.55 | 147 | 18 | 89.09 |
| 0 | 138 | 13 | 125 | 90.58 | 28 | 110 | 79.71 |
| 모두 | 303 | 169 | 134 | 92.74 | 175 | 128 | 84.82 |
| 통계량 | 교육(%) | 검정(%) |
|---|---|---|
| 진양성률(민감도 또는 검정력) | 94.55 | 89.09 |
| 가양성률(유형 I 오차) | 9.42 | 20.29 |
| 가음성률(유형 II 오차) | 5.45 | 10.91 |
| 진음성률(특이성) | 90.58 | 79.71 |
혼동행렬은 모델이 클래스를 얼마나 올바르게 분리하는지 보여줍니다. 이 예에서 이벤트가 올바르게 예측될 확률은 약 89%입니다. 비사건이 올바르게 예측될 확률은 약 80%입니다.
오분류
| 교육 | 검정 | ||||
|---|---|---|---|---|---|
| 실제 등급 | 카운트 | 오분류됨 | 오차율(%) | 오분류됨 | 오차율(%) |
| 1 (사건) | 165 | 9 | 5.45 | 18 | 10.91 |
| 0 | 138 | 13 | 9.42 | 28 | 20.29 |
| 모두 | 303 | 22 | 7.26 | 46 | 15.18 |
오분류 비율은 모형이 새 관측치를 정확하게 예측하는지 여부를 나타내는 데 도움이 됩니다. 사건 예측의 경우 검정 오분류 오차는 약 11%입니다. 비사건 예측의 경우 오분류 오차는 약 20%입니다. 전체적으로 검정 데이터의 오분류 오류는 약 15%입니다.
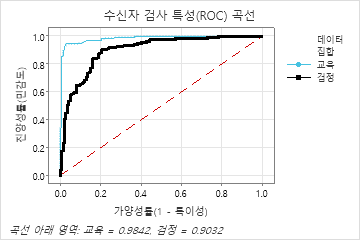
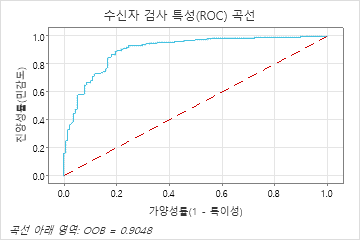
46개의 트리 수가 351일 때 ROC 곡선 아래의 면적은 학습 데이터에 대해 약 0.98이며 검정 데이터에 대해 약 0.90입니다.
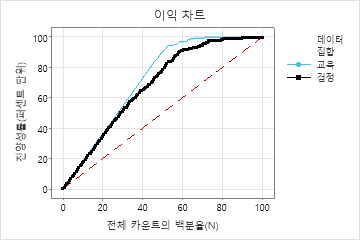
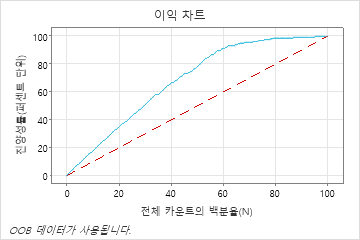
이 예제에서 이익 차트는 기준선 위로 급격히 증가한 다음 평평해집니다. 이 경우 데이터의 약 60%가 진양성의 약 90%를 차지합니다. 이 차이는 모형을 사용하여 산출된 추가 이득입니다.
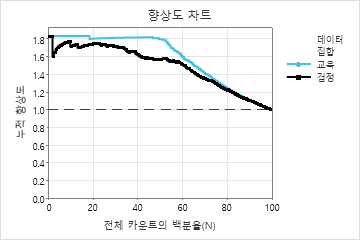
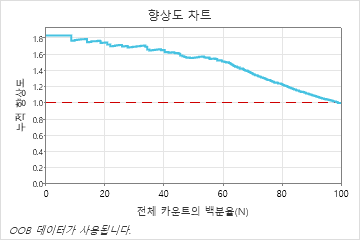
이 예에서 리프트 차트는 총 카운트의 약 50% 후에 더 빠르게 감소하기 시작하는 기준선 위의 큰 증가를 보여줍니다.
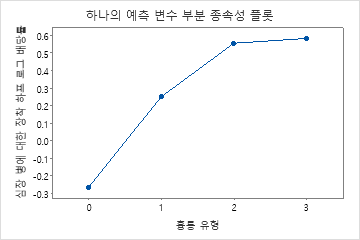
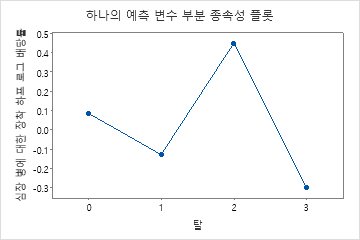
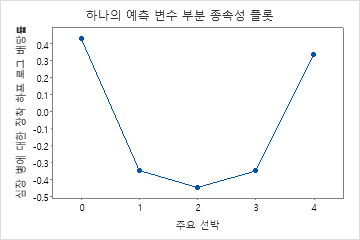
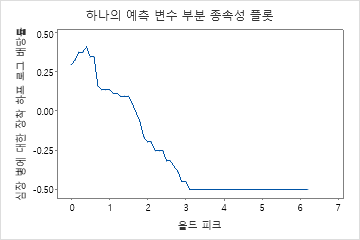
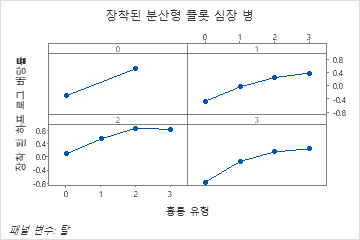
부분 종속성도를 사용하면 중요한 변수 또는 변수 쌍이 적합 반응 값에 어떤 영향을 미치는지 파악할 수 있습니다. 적합된 반응 값은 1/2 로그 척도에 있습니다. 부분 종속성 플롯은 반응과 변수 간의 관계가 선형, 단조로움 또는 더 복잡한지 여부를 보여줍니다.
예를 들어, 흉통 유형의 부분 의존성 그림에서 1/2 로그 확률은 값 3에서 가장 높습니다. 또는 를 선택하여 다른 변수에 대한 그림을 생성합니다.