1단계: 대립 트리 조사
결정계수 대 터미널 노드 수 그림에는 각 트리에 대한 결정계수 값이 표시됩니다. 기본적으로 초기 회귀 트리는 결정계수 값을 최대화하는 트리의 1 표준 오차 내에 결정계수 값을 가진 가장 작은 트리입니다. 분석에서 교차 검증 또는 검정 데이터 세트를 사용하는 경우 결정계수 값은 검증 표본에서 나온 것입니다. 검증 표본에 대한 값은 일반적으로 트리가 커질수록 평준화되고 결국 감소하기 시작합니다.
대립 트리 선택을 클릭하여 모형 요약 통계 표를 포함하는 대화형 그림을 엽니다. 그림을 사용하여 성능이 비슷한 대립 트리를 조사합니다.
- Minitab이 선택하는 트리는 기준이 향상되는 패턴의 일부입니다. 노드가 몇 개 더 있는 하나 이상의 트리는 동일한 패턴의 일부입니다. 일반적으로 최대한 많은 예측 정확도를 가진 트리에서 예측을 하려고 합니다.
- Minitab이 선택하는 트리는 기준이 비교적 평평한 패턴의 일부입니다. 모형 요약 통계가 비슷한 하나 이상의 트리에는 최적의 트리보다 훨씬 적은 수의 노드가 있습니다. 일반적으로 터미널 노드 수가 더 적은 트리는 각 예측 변수가 반응 값에 미치는 영향을 보다 명확하게 파악할 수 있습니다. 더 작은 트리는 또한 쉽게 추가 연구에 대한 몇 가지 대상 그룹을 식별할 수 있습니다. 더 작은 트리에 대한 예측 정확도의 차이를 무시할 수 있는 경우 더 작은 트리를 사용하여 반응 변수와 예측 변수 간의 관계를 평가할 수도 있습니다.
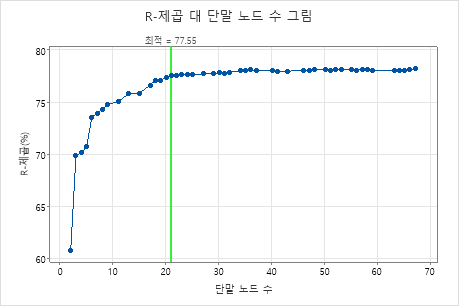
주요 결과: 21개의 터미널 노드가 있는 트리에 대한 결정계수 대 터미널 노드 수 그림
21개의 터미널 노드가 있는 회귀 트리의 결정계수 값은 약 0.78입니다. 이 트리는 트리 생성 기준이 최대 결정계수 값의 1 표준 오차 내의 결정계수 값을 가진 가장 작은 트리이기 때문에 "최적" 레이블이 있습니다. 이 차트는 결정계수 값이 약 70개의 노드가 있는 트리에 비해 약 20개의 노드가 있는 트리가 비교적 안정적이라는 것을 보여주므로 연구원은 결과에서 트리와 유사한 더 작은 일부 트리의 성능을 보고 싶어합니다. 다음 그래프를 비교하여 17개의 노드가 있는 트리의 결과를 확인합니다.
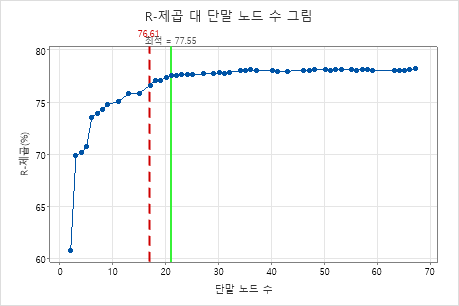
주요 결과: 17개의 터미널 노드가 있는 트리에 대한 결정계수 대 터미널 노드 수 그림
17개의 터미널 노드가 있는 회귀 트리의 결정계수 값은 0.7661입니다. 초기 결과의 트리는 대립 트리 선택을 사용하여 다른 트리에 대한 결과를 작성할 때 "최적" 레이블을 유지합니다.
2단계: 수형도에서 관심 노드 조사
트리를 선택한 후 수형도에서 고유 터미널 노드를 조사합니다. 예를 들어 평균이 크거나 표준 편차가 작은 노드에 관심이 있을 수 있습니다. 세부 보기에서 각 노드의 평균, 표준 편차 및 전체 카운트를 볼 수 있습니다.
참고
수형도를 마우스 오른쪽 단추로 클릭하여 다음과 같은 교호작용을 수행합니다.
- 노드에 대한 적합치에서 가장 작은 변동을 가진 5개의 노드를 강조 표시합니다. 이러한 노드는 최적 노드입니다.
- 트리 기준에 따라 가장 높은 평균 또는 중앙값을 가진 5개의 노드를 강조 표시합니다.
- 트리 기준에 따라 가장 낮은 평균 또는 중앙값을 가진 5개의 노드를 강조 표시합니다.
- 선택한 노드로 이어지는 예측 변수의 값을 복사합니다. 이러한 값은 노드 규칙입니다.
- 노드 분할 보기를 표시합니다. 이 보기는 큰 트리가 있고 노드를 분할하는 변수만 보려는 경우에 유용합니다.
터미널 노드를 추가 그룹으로 분할할 수 없을 때까지 노드가 계속 분할됩니다. 다른 노드를 탐색하여 가장 흥미로운 변수를 확인합니다.
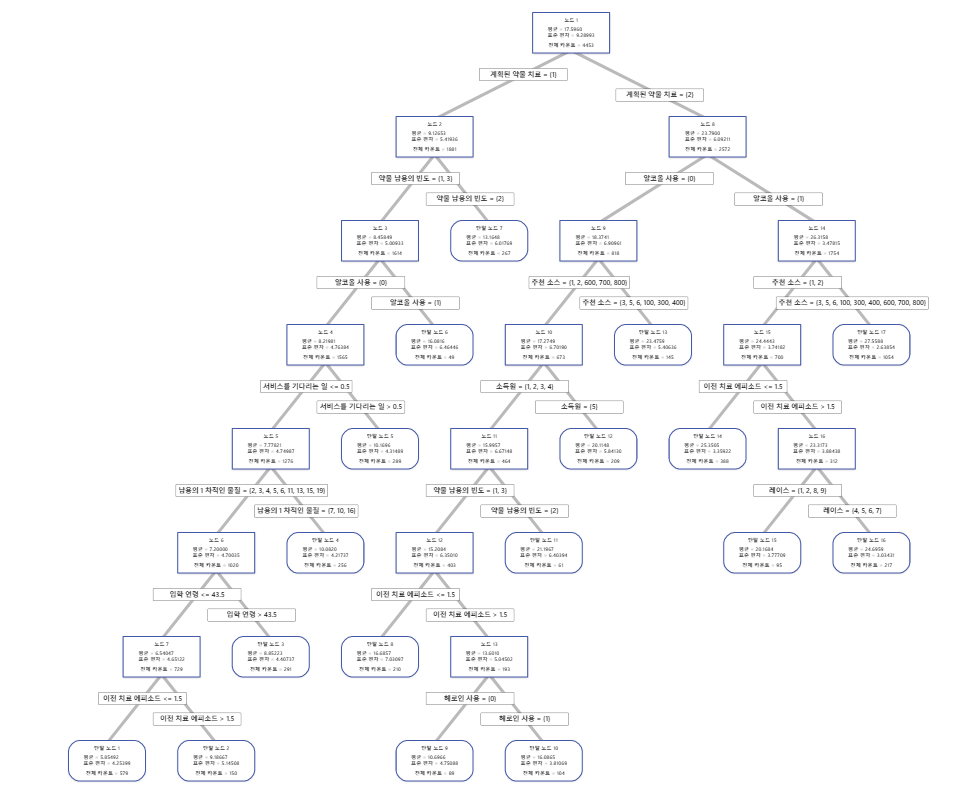
주요 결과: 노드가 17개인 트리의 수형도
수형도는 전체 데이터 세트의 모든 4453개 사례를 표시합니다. 트리 보기를 상세 보기와 노드 분할 보기 간에 전환할 수 있습니다.
- 노드 2에는 계획된 약물 치료 = 1인 사례가 있습니다. 이 노드에는 1881개의 사례가 있습니다. 노드의 평균은 전체 평균보다 적습니다. 노드 2의 표준 편차는 약 5.4이며 분할이 더 많은 순수 노드를 생성하기 때문에 전체 표준 편차보다 적습니다.
- 노드 8에는 계획된 약물 치료 = 2인 사례가 있습니다. 이 노드에는 2572개의 사례가 있습니다. 노드의 평균은 전체 평균보다 큽니다. 노드 8의 표준 편차는 약 6.1이며 전체 표준 편차보다도 적습니다.
그런 다음 노드 2가 약물 남용의 빈도에 의해 분할되고 노드 8이 알코올 사용에 의해 분할됩니다. 터미널 노드 17에는 계획된 약물 치료 = 2, 알코올 사용 = 1, 추천 소스 = 3, 5, 6, 100, 300, 400, 600, 700 또는 800에 대한 사례가 있습니다. 연구원들은 터미널 노드 17에 가장 큰 평균, 최소 표준 편차 및 대부분의 사례가 있음을 주목합니다.
터미널 노드 1에는 가장 작은 평균과 약 4.3의 표준 편차가 있습니다. 터미널 노드 1의 평균은 약 5.9이고 반응 값은 음수일 수 없으므로 노드 통계에 따르면 터미널 노드 1의 데이터가 오른쪽으로 치우져 있음을 알 수 있습니다.
3단계: 중요한 변수 결정
상대 변수 중요도 차트를 사용하여 트리에 가장 중요한 변수인 예측 변수를 확인합니다.
중요한 변수는 트리의 기본 또는 대체 분할입니다. 개선 점수가 가장 높은 변수가 가장 중요한 변수로 설정되고 다른 변수의 순위가 적절하게 매겨집니다. 상대 변수 중요도는 해석의 용이성을 위해 중요도 값을 표준화합니다. 상대적 중요도는 가장 중요한 예측 변수에 대한 백분율 개선으로 정의됩니다.
상대 변수 중요도 값의 범위는 0%에서 100%입니다. 가장 중요한 변수는 항상 100%의 상대적 중요도를 가집니다. 변수가 트리에 없는 경우 해당 변수는 중요하지 않습니다.
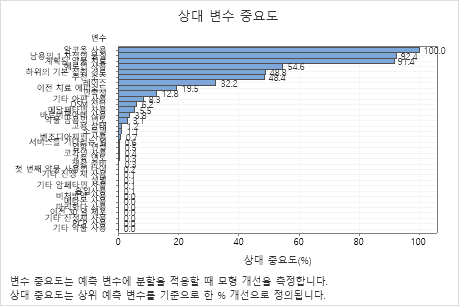
주요 결과: 상대 변수 중요도
- 남용의 1 차적인 물질 및 계획된 약물 치료의 중요도는 알코올 사용와 같이 약 92%입니다.
- 헤로인 사용의 중요도는 알코올 사용와 같이 약 55%입니다.
- 하위의 기본 섭취 경로 및 추천 소스의 중요도는 알코올 사용와 같이 약 48%입니다.
이러한 결과에는 긍정적인 중요도를 가진 33개의 변수가 포함되지만 상대 순위는 특정 응용 프로그램을 제어하거나 모니터링할 변수 수에 대한 정보를 제공합니다. 한 변수에서 다음 변수로 상대적 중요도 값이 급격하게 떨어지면 제어하거나 모니터링할 변수에 대한 결정을 내릴 수 있습니다. 예를 들어 이러한 데이터에서 가장 중요한 세 변수에는 다음 변수에 대한 상대적 중요도가 거의 40% 감소하기 전에 비교적 가까워지는 중요도 값이 있습니다. 마찬가지로 세 변수는 50%에 가까운 유사한 중요도 값을 가집니다. 다른 그룹에서 변수를 제거하고 분석을 다시 실행하여 다양한 그룹의 변수가 모형 요약 표의 예측 정확도 값에 미치는 영향을 평가할 수 있습니다.