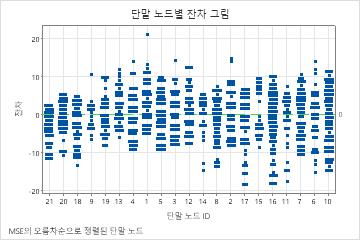
잔차는 각 노드의 오차에 대한 그래픽 요약을 제공합니다. 그림은 노드의 정확도 비교를 단순화합니다.
해석
잔차는 노드의 오차를 요약하고 적합도가 좋지 않은 경우를 식별하는 데 도움이 될 수 있습니다. 반응 변수의 배율에 비해 잔차가 작은 노드의 적합치에 대해 가장 높은 신뢰도를 가질 수 있습니다. 잔차가 더 넓은 노드는 더 많은 변동을 줄이거나 설명할 수 있는 기회를 나타낼 수 있습니다. 비정상적인 패턴을 표시하는 사례를 조사할지 여부를 선택할 수 있습니다.
기본적으로 노드는 최소 오차부터 최대 오차까지 순서대로 정렬됩니다. 분석을 실행하면 그래프 단추를 눌러 식별 번호로 노드를 정렬하는 옵션을 찾을 수 있습니다.
분석에서 검정 데이터 세트를 사용하는 경우 그래프에는 학습 및 검정 데이터에 대한 별도의 그림이 포함됩니다. 검정 데이터에 대한 트리의 성능은 일반적으로 트리가 새 데이터에 대해 수행하는 방식을 더 잘 표현합니다. 검정 데이터와 학습 데이터 간의 큰 차이점을 조사해야 합니다.
다음 그림에서 터미널 노드 1에 최대 잔차도 포함됩니다. 터미널 노드 13에는 음의 잔차가 있습니다. 이러한 점을 자세히 조사하면 트리가 노드의 다른 점뿐만 아니라 이러한 점을 적합하지 않는 이유를 알 수 있습니다. 터미널 노드 17은 터미널 노드의 최소 MSE를 가집니다. 터미널 노드 17의 잔차 범위는 그림의 반대편에 있는 노드에 비해 상대적으로 작습니다.