총 예측 변수
트리에 사용할 수 있는 총 예측 변수 수입니다. 지정한 계량형 예측 변수와 범주형 예측 변수의 합계입니다.
중요한 예측 변수
트리의 중요한 예측 변수 수입니다. 중요한 예측 변수는 기본 또는 대체 분할로 사용되는 변수입니다.
해석
상대 변수 중요도 그림을 사용하여 상대 변수 중요도의 순서를 표시할 수 있습니다. 예를 들어 20개의 예측 변수 중 10개가 트리에서 중요하다고 가정하면 상대 변수 중요도 그림은 변수를 중요도 순서대로 표시합니다.
단말 노드 수
단말 노드는 더 이상 분할할 수 없는 최종 노드입니다.
해석
단말 노드 정보를 사용하여 예측을 수행할 수 있습니다.
최소 단말 노드 크기
최소 단말 노드 크기는 사례 수가 가장 적은 단말 노드입니다.
해석
기본적으로 Minitab은 단말 노드에 허용되는 최소 사례 수를 3개의 사례로 설정합니다. 그러나 트리의 최소 단말 노드 크기는 분석에서 허용하는 최소 개수보다 클 수 있습니다. 이 분계점 값을 옵션 하위 대화 상자에서 변경할 수 있습니다.
결정계수
R2는 모형에서 설명하는 반응의 변동 비율입니다. 특이치는 MAD 및 MAPE보다 R2에 더 큰 영향을 미칩니다.
검증 방법을 사용하는 경우 표에는 학습 데이터 세트에 대한 R2 결정계수 통계와 검정 데이터 세트에 대한 R2 결정계수 통계가 포함됩니다. 검증 방법이 k-폴드 교차 검증인 경우 트리 빌드에서 해당 폴드를 제외할 때 검정 데이터 세트는 각 폴드입니다. 검정 R2 결정계수 통계는 일반적으로 새 데이터에 대해 모형이 작동하는 방식을 더 잘 측정합니다.
해석
R2 결정계수를 사용하여 모형이 데이터를 얼마나 적합시키는지 확인합니다. R2 결정계수 값이 높을수록 모형이 데이터를 더 잘 적합시킵니다. R2 결정계수는 항상 0%에서 100% 사이입니다.
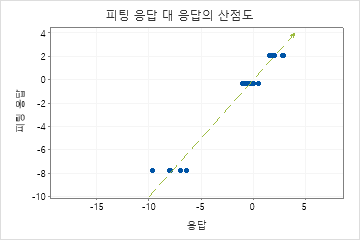
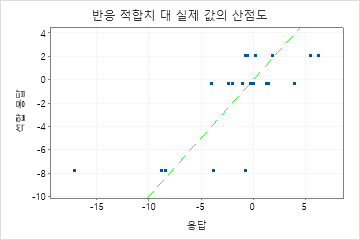
학습 R2 결정계수보다 실질적으로 적은 검정 R2 결정계수는 트리가 새 사례에 대한 반응 값을 예측하지 못할 수 있으며 트리가 현재 데이터 세트를 적합시킴을 나타냅니다.
루트 평균 제곱 오차(RMSE)
루트 평균 제곱 오차(RMSE)는 트리의 정확도를 측정합니다. 특이치는 MAD 및 MAPE보다 RMSE에 더 큰 영향을 미칩니다.
검증 방법을 사용하는 경우 표에는 학습 데이터 세트에 대한 RMSE 통계와 검정 데이터 세트에 대한 RMSE 통계가 포함됩니다. 검증 방법이 k-폴드 교차 검증인 경우 트리 빌드에서 해당 폴드를 제외할 때 검정 데이터 세트는 각 폴드입니다. 검정 RMSE 통계는 일반적으로 새 데이터에 대해 모형이 작동하는 방식을 더 잘 측정합니다.
해석
다른 트리의 적합을 비교하는 데 사용합니다. 값이 작을수록 더 잘 적합함을 나타냅니다. 학습 RMSE보다 훨씬 큰 검정 RMSE는 트리가 새 케이스에 대한 반응 값을 예측하지 못할 수 있으며 트리가 현재 데이터 세트를 적합함을 나타냅니다.
평균 제곱 오차(MSE)
평균 제곱 오차(MSE)는 트리의 정확도를 측정합니다. 특이치는 MAD 및 MAPE보다 MAPE에 더 큰 영향을 미칩니다.
검증 방법을 사용하는 경우 표에는 학습 데이터 세트에 대한 MSE 통계와 검정 데이터 세트에 대한 MSE 통계가 포함됩니다. 검증 방법이 k-폴드 교차 검증인 경우 트리 빌드에서 해당 폴드를 제외할 때 검정 데이터 세트는 각 폴드입니다. 검정 MSE 통계는 일반적으로 새 데이터에 대해 모형이 작동하는 방식을 더 잘 측정합니다.
해석
다른 트리의 적합을 비교하는 데 사용합니다. 값이 작을수록 더 잘 적합함을 나타냅니다. 훈련 MSE보다 훨씬 더 많은 검정 MSE는 트리가 새 케이스에 대한 반응 값을 예측하지 못할 수 있으며 트리가 현재 데이터 세트를 적합함을 나타냅니다.
평균 절대 편차(MAD)
평균 절대 편차(MAD)는 데이터와 동일한 단위로 정확도를 표현하므로 오차 양을 개념화하는 데 도움이 됩니다. 특이치는 R2 결정계수, RMSE 및 MSE보다 MAD에 미치는 영향이 적습니다.
검증 방법을 사용하는 경우 표에는 학습 데이터 세트에 대한 MAD 통계와 검정 데이터 세트에 대한 MAD 통계가 포함됩니다. 검증 방법이 k-폴드 교차 검증인 경우 트리 빌드에서 해당 폴드를 제외할 때 검정 데이터 세트는 각 폴드입니다. 검정 MAD 통계는 일반적으로 새 데이터에 대해 모형이 작동하는 방식을 더 잘 측정합니다.
해석
다른 트리의 적합을 비교하는 데 사용합니다. 값이 작을수록 더 잘 적합함을 나타냅니다. 검정 MAD가 훈련 MAD보다 훨씬 크면 트리가 새 사례에 대한 반응 값을 예측하지 못할 수 있으며 트리가 현재 데이터 집합을 적합함을 나타냅니다.
평균 절대 백분율 오차(MAPE)
평균 절대 백분율 오차(MAPE)는 정확도를 오차의 백분율로 표현합니다. MAPE는 백분율이므로 다른 정확도 측정 통계보다 이해하기가 더 쉬울 수 있습니다. 예를 들어 MAPE가 평균적으로 0.05인 경우 모든 사례에 걸쳐 적합 오차와 실제 값 간의 평균 비율은 5%입니다. 특이치는 R2 결정계수, RMSE 및 MSE보다 MAPE에 미치는 영향이 적습니다.
그러나 트리가 데이터를 잘 적합시키는 것처럼 보이더라도 매우 큰 MAPE 값이 표시될 수 있습니다. 적합 대 실제 반응 값 그림을 검사하여 데이터 값이 0에 가까운지 확인합니다. MAPE는 절대 오차를 실제 데이터로 나누기 때문에 0에 가까운 값은 MAPE를 크게 팽창시킬 수 있습니다.
검증 방법을 사용하는 경우 표에는 학습 데이터 세트에 대한 MAPE 통계와 검정 데이터 세트에 대한 MAPE 통계가 포함됩니다. 검증 방법이 k-폴드 교차 검증인 경우 트리 빌드에서 해당 폴드를 제외할 때 검정 데이터 세트는 각 폴드입니다. 검정 MAPE 통계는 일반적으로 새 데이터에 대해 모형이 작동하는 방식을 더 잘 측정합니다.
해석
다른 트리의 적합을 비교하는 데 사용합니다. 값이 작을수록 더 잘 적합함을 나타냅니다. 학습 MAPE보다 훨씬 더 많은 테스트 MAPE는 트리가 새 사례에 대한 반응 값을 예측하지 못할 수 있으며 트리가 현재 데이터 집합을 적합함을 나타냅니다.