의료 제공자는 약물 남용 치료 서비스를 제공하는 시설을 운영합니다. 시설의 서비스 중 하나는 정기적인 치료 과정이 1일에서 30일까지 지속될 수 있는 외래 환자 해독 프로그램입니다. 인력 및 소모품을 계획하는 팀은 환자가 프로그램에 들어갈 때 환자에 대해 수집할 수 있는 정보를 기반으로 환자가 서비스를 사용하는 기간에 대해 더 나은 예측을 할 수 있는지 여부를 연구하고자 합니다. 이 변수는 환자의 약물 남용에 대한 인구 통계학적 정보 및 변수를 포함합니다.
첫째, 팀은 Minitab에서 기존의 회귀 분석을 고려합니다. 데이터의 결측값 패턴으로 인해 분석에서 데이터의 70% 이상이 생략됩니다. 이러한 많은 비율의 데이터가 누락되면 많은 정보가 손실됩니다. 누락된 데이터가 없는 사례의 분석 결과는 전체 데이터 세트를 사용하는 결과와 매우 다를 수 있습니다. 예측 변수의 누락 값을 자동으로 처리하기 때문 CART® 회귀 분석 에, 팀은 데이터를 더 평가하기 위해 이 도구를 사용 CART® 회귀 분석 하기로 결정했습니다.
- 표본 데이터 세트를 엽니다 서비스기간.MWX.
- 을 선택합니다 .
- 에 반응'' 를 입력합니다서비스 기간.
- 에 계량형 예측 변수'입학 연령'-''를교육 연도입력합니다.
- 에 범주형 예측 변수''다른 자극제 사용'-''를DSM 진단입력합니다.
- 검증을 클릭합니다.
- 검증 방법에서 K-접기 교차 검증를 선택합니다.
- ID 열별로 각 접기의 행 할당을 선택합니다.
- ID 열에 접어입력합니다.
- 각 대화 상자에서 확인를 클릭합니다.
결과 해석
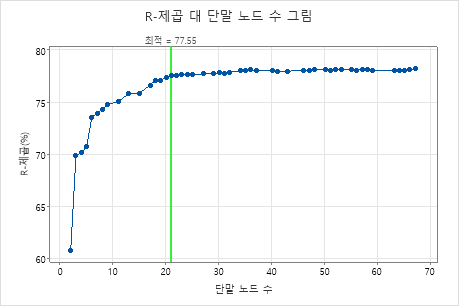
기본적으로 Minitab은 R2 값이 최대 R2 값인 트리에서 1 표준오차 이내의 가장 작은 트리를 표시합니다. 의료팀이 k-중개 검증을 사용하기 때문에, 기준은 최대 k-중개 R2 값입니다. 이 트리에는 21개의 터미널 노드가 있습니다.
대립 트리 선택
- 출력에서 대립 트리 선택을 클릭합니다.
- 그림에서 17노드 트리를 선택합니다.
- 트리 만들기을 클릭합니다.
결과 해석
연구진은 교차 검증과 터미널 노드 수를 통해 R2 통계량의 그래프를 살펴봅니다. 17노드가 있는 트리는 그래프에서 가장 큰 값에 가까운 R2 통계량을 가지므로, 나머지 출력의 결과는 17노드가 있는 트리에 해당합니다.
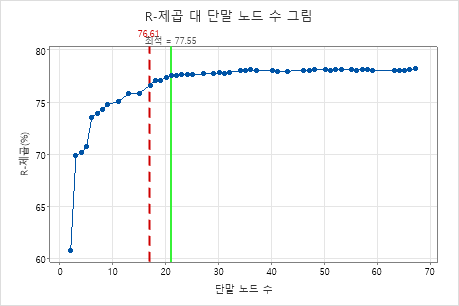
연구원은 더 작은 트리의 성능을 평가하기 위해 모형 요약을 먼저 살펴봅니다. 훈련 통계와 교차 검증 통계값이 가까워 트리가 과적합하지 않은 것처럼 보입니다. R2 통계량은 21노드 트리와 거의 비슷하므로, 연구자들은 17개 노드를 가진 트리를 사용해 예측 변수와 응답값 간의 관계를 탐구하기로 결정했습니다.
방법
| 노드 분할 | 최소 제곱 오차 |
|---|---|
| 최적 트리 | 최대 R-제곱의 2.5 표준 오차 이내 |
| 모형 검증 | 접어에 의해 정의된 행을 사용한 교차 검증 |
| 사용된 행 | 4453 |
반응 정보
| 평균 | 표준 편차 | 최소값 | Q1 | 중위수 | Q3 | 최대값 |
|---|---|---|---|---|---|---|
| 17.5960 | 9.29097 | 1 | 10 | 18 | 26 | 30 |
모형 요약
| 전체 예측 변수 | 44 |
|---|---|
| 중요 예측 변수 | 33 |
| 단말 노드 수 | 17 |
| 최소 단말 노드 크기 | 49 |
| 통계량 | 교육 | 교차 검증 |
|---|---|---|
| R-제곱 | 77.99% | 76.61% |
| 루트 평균 제곱 오차(RMSE) | 4.3585 | 4.4932 |
| 평균 제곱 오차(MSE) | 18.9967 | 20.1887 |
| 평균 절대 편차(MAD) | 3.4070 | 3.5226 |
| 평균 절대 백분율 오차(MAPE) | 0.6535 | 0.6674 |
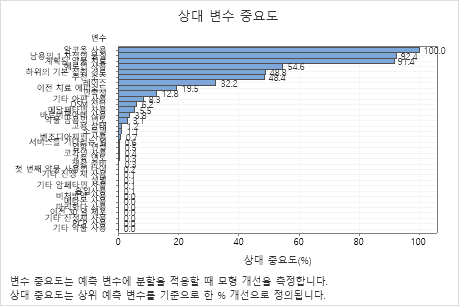
- 남용의 1 차적인 물질 그리고 계획된 약물 치료 는 와 약 92%의 중요성 알코올 사용을 가집니다.
- 헤로인 사용 약 55 %가 알코올 사용중요합니다.
- 하위의 기본 섭취 경로 그리고 추천 소스 는 와 약 48%의 중요성 알코올 사용을 가집니다.
이러한 결과에는 긍정적인 중요도를 가진 33개의 변수가 포함되지만 상대 순위는 특정 응용 프로그램을 제어하거나 모니터링할 변수 수에 대한 정보를 제공합니다. 한 변수에서 다음 변수로 상대적 중요도 값이 급격하게 떨어지면 제어하거나 모니터링할 변수에 대한 결정을 내릴 수 있습니다. 예를 들어 이러한 데이터에서 가장 중요한 세 변수에는 다음 변수에 대한 상대적 중요도가 거의 40% 감소하기 전에 비교적 가까워지는 중요도 값이 있습니다. 마찬가지로 세 변수는 50%에 가까운 유사한 중요도 값을 가집니다. 다른 그룹에서 변수를 제거하고 분석을 다시 실행하여 다양한 그룹의 변수가 모형 요약 표의 예측 정확도 값에 미치는 영향을 평가할 수 있습니다.
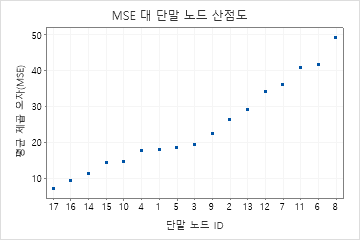
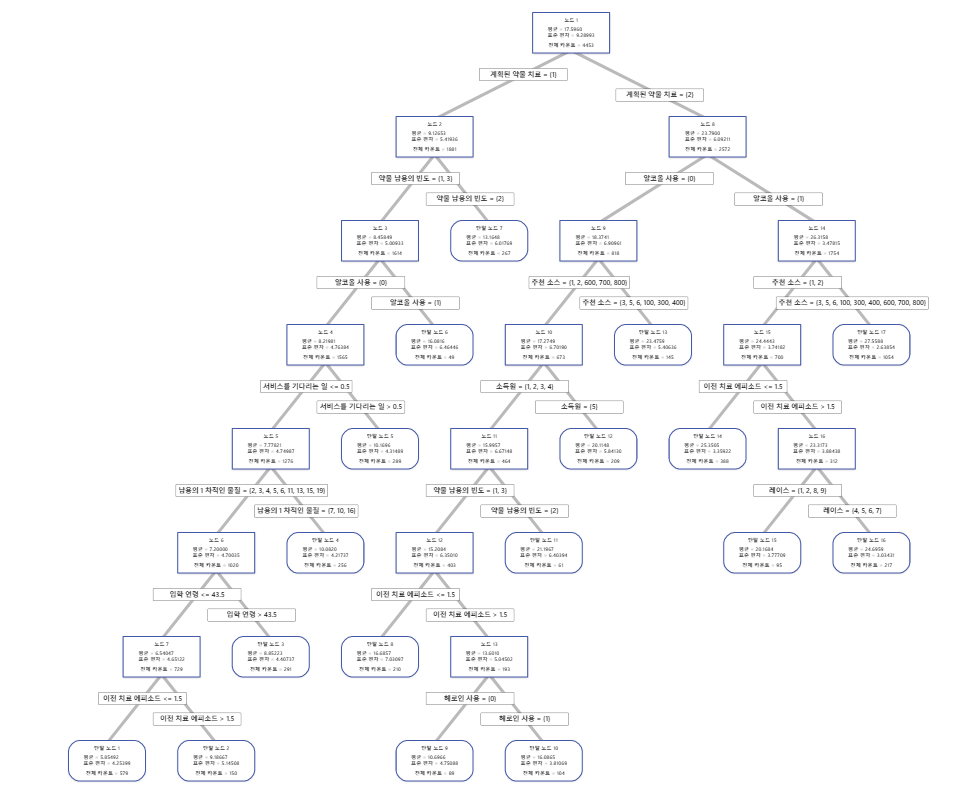
k-폴드 교차 검증을 통한 분석의 경우 수형도는 전체 데이터 세트의 모든 4453개 사례를 표시합니다. 트리 보기를 상세 보기와 노드 분할 보기 간에 전환할 수 있습니다. 적합치 및 오차 통계 표와 피실험자를 분류하는 기준은 터미널 노드에 대한 추가 정보를 제공합니다.
- 노드 2에는 계획된 약물 치료 = 1인 사례가 포함됩니다. 이 노드에는 1881개의 사례가 있습니다. 노드의 평균은 전체 평균보다 적습니다. 노드 2의 표준 편차는 약 5.4이며 분할이 더 많은 순수 노드를 생성하기 때문에 전체 표준 편차보다 적습니다.
- 노드 8에는 계획된 약물 치료 = 2인 사례가 포함됩니다. 이 노드에는 2572개의 사례가 있습니다. 노드의 평균은 전체 평균보다 큽니다. 노드 8의 표준 편차는 약 6.1이며 전체 표준 편차보다도 적습니다.
그런 다음 노드 2가 약물 남용의 빈도에 의해 분할되고 노드 8이 알코올 사용에 의해 분할됩니다. 터미널 노드 17에는 계획된 약물 치료 = 2, 알코올 사용 = 1, 추천 소스 = 3, 5, 6, 100, 300, 400, 600, 700 또는 800에 대한 사례가 있습니다. 연구원들은 터미널 노드 17에 가장 큰 평균, 최소 표준 편차 및 대부분의 사례가 있음을 주목합니다.
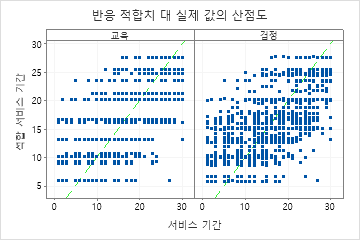
결과에는 적합된 반응 값과 실제 반응 값의 산점도가 포함됩니다. 훈련 데이터 세트와 교차 검증 결과 세트의 포인트는 유사한 패턴을 보입니다. 이러한 유사성은 새 데이터에 대한 트리의 성능이 학습 데이터에 대한 트리의 성능에 가깝다는 것을 시사합니다.
- 계획된 약물 치료 = {2}
- 알코올 사용 = {0}
- 추천 소스 = {1, 2, 600, 700, 800}
- 소득원 = {1, 2, 3, 4}
- 약물 남용의 빈도 = {1, 3}
- 이전 치료 에피소드 <= 1.5
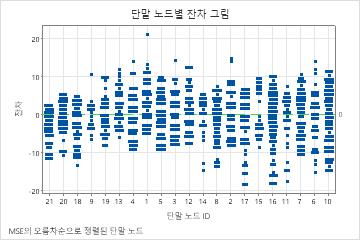
터미널 노드별 잔차 그림은 적합치가 터미널 노드 8에 있는 환자의 작은 군집에 대해 너무 크다는 것을 보여줍니다. 분석가는 이 환자 중 몇 명이 그룹의 전형적인 환자보다 더 적은 시간 동안 서비스를 사용하는 이유에 대한 조사를 고려합니다. 예를 들어, 이 환자가 터미널 노드에 있는 기타 환자와 다른 지리적 위치에 있는 경우 다른 정부 및 보험 규정은 서비스를 사용하는 기간에 영향을 미칠 수 있었습니다.
터미널 노드별 잔차 그림은 분석가가 군집 또는 특이치를 조사하도록 선택할 수 있는 다른 사례를 보여줍니다. 예를 들어, 이러한 데이터에는 터미널 노드 1과 터미널 노드 7의 다른 잔차보다 훨씬 더 크게 나타나는 잔차가 하나 있습니다. 분석가는 이 환자가 터미널 노드에 있는 기타 환자보다 더 오래 서비스를 사용한 이유를 조사하기로 결정합니다.
교차 검증 R2 값이 개선 여지를 남기고, 잔여 플롯이 트리가 잘 맞지 않는 경우를 보여주기 때문에, 연구자들은 적합도를 개선하기 위해 a TreeNet® 회귀 분석 와 a Random Forests® 회귀 분석 중 어느 것을 사용할지 고민합니다.