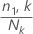ROC 곡선의 점에 대한 절차는 검증 방법에 따라 다릅니다. 다항 반응 변수의 경우 Minitab은 각 클래스를 차례로 사건으로 처리하는 여러 차트를 표시합니다.
학습 데이터 세트 또는 검증 없음
학습 데이터 세트에 대한 차트의 경우 차트의 각 점은 트리의 터미널 노드를 나타냅니다. 사건 확률이 가장 높은 터미널 노드는 차트의 첫 번째 지점이며 가장 왼쪽에 나타납니다. 다른 터미널 노드는 사건 확률을 줄이는 순서입니다.
다음 프로세스를 사용하여 차트의 x 및 y 좌표를 찾습니다.
각 터미널 노드의 사건 확률을 계산합니다.
설명
n1,k는 k번째 노드의 사례 수입니다.
Nk는 k번째 노드의 사례 수입니다.
터미널 노드의 순위를 가장 높은 노드에서 가장 낮은 사건 확률로 지정합니다.
모든 사건 확률을 분계점으로 사용합니다. 특정 분계점의 경우 예상 사건 확률이 분계점보다 크거나 같은 사례는 예측 등급으로 1을, 그렇지 않으면 0을 얻습니다. 그런 다음 관측 클래스가 행으로 지정되고 예측 클래스가 열로 지정된 모든 사례에 대해 2x2 표를 형성하여 각 터미널 노드에 대한 가양성률과 진양성률을 계산할 수 있습니다. 가양성률은 차트의 x 좌표이며 진양성률은 y 좌표입니다.
예를 들어 다음 표에서 4개의 터미널 노드가 있는 트리를 요약한다고 가정합니다.
A: 터미널 노드
B: 사건 수
C: 비사건 수
D: 사례 수
E: 분계점(B/D)
4
18
12
30
0.60
1
25
42
67
0.37
3
12
44
56
0.21
2
4
32
36
0.11
합계
59
130
189
다음은 가양성률과 소수점 2자리로 올림된 진양성률을 가진 해당 4개의 표입니다.
표 1. 분계점 = 0.60.
가양성률 = 12 / (12 + 118) = 0.09
진양성률 = 18 / (18 + 41) = 0.31
예측
사건
비사건
관측
사건
18
41
비사건
12
118
표 2. 분계점 = 0.37.
가양성률 = (12 + 42) / 130 = 0.42
진양성률 = (18 + 25) / 59 = 0.73
예측
사건
비사건
관측
사건
43
16
비사건
54
76
표 3. 분계점 = 0.21.
가양성률 = (12 + 42 + 44) / 130 = 0.75
진양성률 = (18 + 25 + 12) / 59 = 0.93
예측
사건
비사건
관측
사건
55
4
비사건
98
32
표 4. 분계점 = 0.11.
가양성률 = (12 + 42 + 44 + 32) / 130 = 1
진양성률 = (18 + 25 + 12 + 4) / 59 = 1
예측
사건
비사건
관측
사건
59
0
비사건
130
0
별도의 검정 데이터 세트
학습 데이터 세트 절차와 동일한 단계를 사용하지만 검정 테스트 세트의 사례에서 사건 확률을 계산합니다.
k-폴드 교차 검증을 통한 검정
k-폴드 교차 검증을 사용하여 ROC 곡선 차트에서 x 및 y 좌표를 정의하는 절차에는 추가 단계가 있습니다. 이 단계에서는 여러 가지 고유한 사건 확률을 만듭니다. 예를 들어 수형도에 4개의 터미널 노드가 포함되어 있다고 가정합니다. 10-폴드 교차 검증이 있으면 그런 다음 i번째 접기의 경우 데이터의 9/10 부분을 사용하여 접기 i의 사례에 대한 사건 확률을 추정합니다. 이 프로세스가 각 접기에 대해 반복되면 고유 사건 확률의 최대 수는 4 *10 = 40입니다. 그런 다음 모든 고유한 사건 확률을 감소 순서로 정렬합니다. 사건 확률을 각 분계점으로 사용하여 전체 데이터 세트의 사례에 대해 예측된 클래스를 할당합니다. 이 단계 후 학습 데이터 세트 절차의 3단계에서 마지막 단계는 x 및 y 좌표를 찾기 위해 적용됩니다.