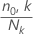향상도 차트의 점에 대한 절차는 검증 방법에 따라 다릅니다. 다항 반응 변수의 경우 Minitab은 각 클래스를 차례로 사건으로 처리하는 여러 차트를 표시합니다.
학습 데이터 세트 또는 검증 없음
학습 데이터 세트에 대한 차트의 경우 차트의 각 점은 트리의 터미널 노드를 나타냅니다. 사건 확률이 가장 높은 터미널 노드는 차트의 첫 번째 지점이며 가장 왼쪽에 나타납니다. 다른 터미널 노드는 사건 확률을 줄이는 순서입니다.
다음 프로세스를 사용하여 점에 대한 x 및 y 좌표를 찾습니다.
각 터미널 노드의 사건 확률을 계산합니다.
설명
n1,k 는 사건 클래스의 사례 수입니다.
k번째 노드
Nk 는 사례 수
k번째 노드
터미널 노드의 순위를 가장 높은 노드에서 가장 낮은 사건 확률로 지정합니다.
각 터미널 노드의 경우 터미널 노드에서 사건 클래스에 사례를 할당하고, 다른 터미널 노드의 경우 비사건 클래스에 사례를 할당합니다.
예를 들어 다음 표에서 4개의 터미널 노드가 있는 트리를 요약한다고 가정합니다.
A 터미널 노드
B: 사건 발생 횟수
C: 사례 수
D: 분계점(B/C)
4(4)
18
30
0.60
0
25
67
0.37
3(3)
12
56
0.21
2
4(4)
36
0.11
합계
59
189
그런 다음 진양성률이 소수점 2자리인 항목은 다음과 같습니다.
A 터미널 노드
B: 사건 발생 횟수
C: 진양성률
4(4)
18
18 / 59 = 0.31
0
25
25 / 59 = 0.42
3(3)
12
12 / 59 = 0.20
2
4(4)
4 / 59 = 0.07
합계
59
정렬된 터미널 노드에서 터미널 노드의 모집단 백분율을 찾습니다.
설명
Nk 는 사례 수
k번째 노드
N 는 학습 데이터 세트의 사례 수입니다.
y 좌표의 향상도를 찾으려면 진양성률과 모집단의 백분율을 다음과 같이 나눕니다.
정렬된 터미널 노드의 경우 각 터미널 노드에 있는 데이터의 누적 백분율을 계산합니다. 이러한 누적 값은 차트의 x 좌표입니다.
예를 들어 예측 확률이 가장 높은 터미널 노드에 0.16의 데이터가 포함되어 있고 사건 확률이 두 번째로 높은 터미널 노드가 0.35의 모집단을 가지면 첫 번째 터미널 노드에 대한 데이터의 누적 백분율이 0.16이고 두 번째 터미널 노드에 대한 모집단의 누적 백분율은 0.16 + 0.35 = 0.51입니다.
다음 표에서는 작은 트리에 대한 계산의 예를 표시합니다. 값은 소수점 2자리입니다.
A 터미널 노드
B: 사건 발생 횟수
C: 사례 수
D: 정렬에 대한 사건 확률(B/C)
E: 진양성률
F: 데이터 백분율(C/C 합계)
G: 데이터의 누적 백분율, x 좌표
H: 향상도(E/F), y 좌표
4(4)
18
30
0.60
0.31
0.16
0.16
1.94
0
25
67
0.37
0.42
0.35
0.51
1.20
3(3)
12
56
0.21
0.20
0.30
0.81
0.67
2
4(4)
36
0.11
0.07
0.19
1.00
0.37
별도의 검정 데이터 세트
학습 데이터 세트 사례와 동일한 단계를 사용하지만 검정 데이터 세트의 사례에서 사건 확률을 계산합니다.
k-폴드 교차 검증을 통한 검정
k-폴드 교차 검증을 사용하여 향상도 차트에서 x 및 y 좌표를 정의하는 절차에는 추가 단계가 있습니다. 이 단계에서는 여러 가지 고유한 사건 확률을 만듭니다. 예를 들어 수형도에 4개의 터미널 노드가 포함되어 있다고 가정합니다. 10-폴드 교차 검증이 있으면 i번째 폴드의 경우 데이터의 9/10 부분을 사용하여 폴드 i의 사례에 대한 사건 확률을 추정합니다. 이 프로세스가 각 폴드에 대해 반복되면 고유 사건 확률의 최대 수는 4 *10 = 40입니다. 그런 다음 모든 고유한 사건 확률을 감소 순서로 정렬하고 적절한 저장소를 형성하기 위해 더 많은 사례가 필요한 고유한 사건 확률을 결합합니다. 이 단계 후 학습 데이터 세트 절차의 3단계에서 마지막 단계는 x 및 y 좌표를 찾기 위해 적용됩니다.