1단계: 대립 트리 조사
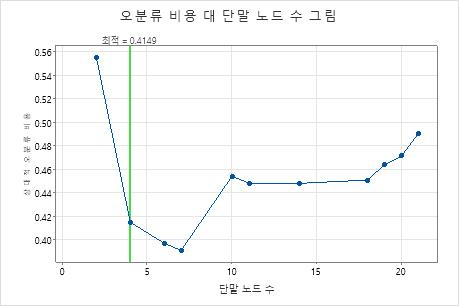
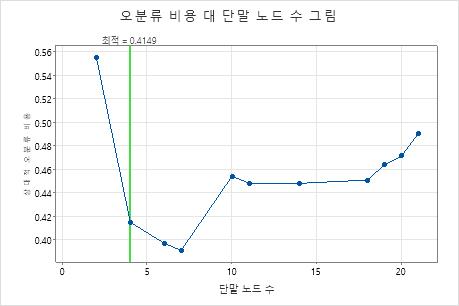
오분류 비용 대 터미널 노드 수 그림은 최적의 트리를 생성하는 시퀀스의 각 트리에 대한 오분류 비용을 표시합니다. 기본적으로 초기 최적 트리는 오분류 비용을 최소화하는 트리의 표준 오차 하나 내에서 오분류 비용이 있는 가장 작은 트리입니다. 분석에서 교차 검증 또는 검정 데이터 세트를 사용하는 경우 오분류 비용이 검증 표본에서 나온 것입니다. 검증 표본에 대한 오분류 비용은 일반적으로 트리가 커질수록 평준화되고 결국 증가합니다.
- 최적의 트리는 오분류 비용이 감소하는 패턴의 일부입니다. 노드가 몇 개 더 있는 하나 이상의 트리는 동일한 패턴의 일부입니다. 일반적으로 최대한 많은 예측 정확도를 가진 트리에서 예측을 하려고 합니다. 트리가 충분히 단순하다면 이 트리를 사용하여 각 예측 변수가 반응 값에 미치는 영향을 이해할 수도 있습니다.
- 최적 트리는 오분류 비용이 상대적으로 평평한 경우 패턴의 일부입니다. 모형 요약 통계가 비슷한 하나 이상의 트리에는 최적 트리보다 훨씬 적은 수의 노드가 있습니다. 일반적으로 터미널 노드 수가 더 적은 트리는 각 예측 변수가 반응 값에 미치는 영향을 보다 명확하게 파악할 수 있습니다. 더 작은 트리는 또한 쉽게 추가 연구에 대한 몇 가지 대상 그룹을 식별할 수 있습니다. 더 작은 트리에 대한 예측 정확도의 차이를 무시할 수 있는 경우 더 작은 트리를 사용하여 반응 변수와 예측 변수 간의 관계를 평가할 수도 있습니다.
모형 요약
| 전체 예측 변수 | 13 |
|---|---|
| 중요 예측 변수 | 13 |
| 단말 노드 수 | 4 |
| 최소 단말 노드 크기 | 27 |
| 통계량 | 교육 | 검정 |
|---|---|---|
| 평균 음수 로그 우도 | 0.4772 | 0.5164 |
| ROC 곡선 아래 면적 | 0.8192 | 0.8001 |
| 95% CI | (0.3438, 1) | (0.7482, 0.8520) |
| 향상도 | 1.6189 | 1.8849 |
| 오분류 비용 | 0.3856 | 0.4149 |
주요 결과: 노드가 4개인 트리에 대한 그림 및 모형 요약
노드가 4개인 시퀀스의 트리는 0.41에 가까운 오분류 비용을 가집니다. 오분류 비용이 감소하는 패턴이 4-노드 트리 후에도 계속됩니다. 이와 같은 경우 분석가는 오분류 비용이 낮은 다른 간단한 트리를 탐색하기로 결정합니다.
모형 요약
| 전체 예측 변수 | 13 |
|---|---|
| 중요 예측 변수 | 13 |
| 단말 노드 수 | 7 |
| 최소 단말 노드 크기 | 5 |
| 통계량 | 교육 | 검정 |
|---|---|---|
| 평균 음수 로그 우도 | 0.3971 | 0.5094 |
| ROC 곡선 아래 면적 | 0.8861 | 0.8200 |
| 95% CI | (0.5590, 1) | (0.7702, 0.8697) |
| 향상도 | 1.9376 | 1.8165 |
| 오분류 비용 | 0.2924 | 0.3909 |
주요 결과: 노드가 7개인 트리에 대한 그림 및 모형 요약
상대 교차 검증된 오분류 비용을 최소화하는 분류 트리에는 7개의 터미널 노드와 약 0.39의 상대 오분류 비용이 있습니다. ROC 곡선 아래 면적과 같은 기타 통계에서는 7-노드 트리가 4-노드 트리보다 더 잘 수행되는지도 확인합니다. 7-노드 트리에는 해석하기 쉬운 노드가 거의 없기 때문에 분석가는 7-노드 트리를 사용하여 중요한 변수를 연구하고 예측을 하기로 결정합니다.
2단계: 수형도에서 가장 순수한 터미널 노드 조사
트리를 선택한 후 수형도에서 가장 순수한 터미널 노드를 조사합니다. 파란색은 사건 수준을 나타내고 빨간색은 비사건 수준을 나타냅니다.
참고
수형도를 마우스 오른쪽 단추로 클릭하여 트리의 노드 분할 보기를 표시할 수 있습니다. 이 보기는 큰 트리가 있고 노드를 분할하는 변수만 보려는 경우에 유용합니다.
터미널 노드를 추가 그룹으로 분할할 수 없을 때까지 노드가 계속 분할됩니다. 대부분 파란색인 노드는 사건 수준의 강한 비율을 나타냅니다. 대부분 빨간색인 노드는 비사건 수준의 강한 비율을 나타냅니다.
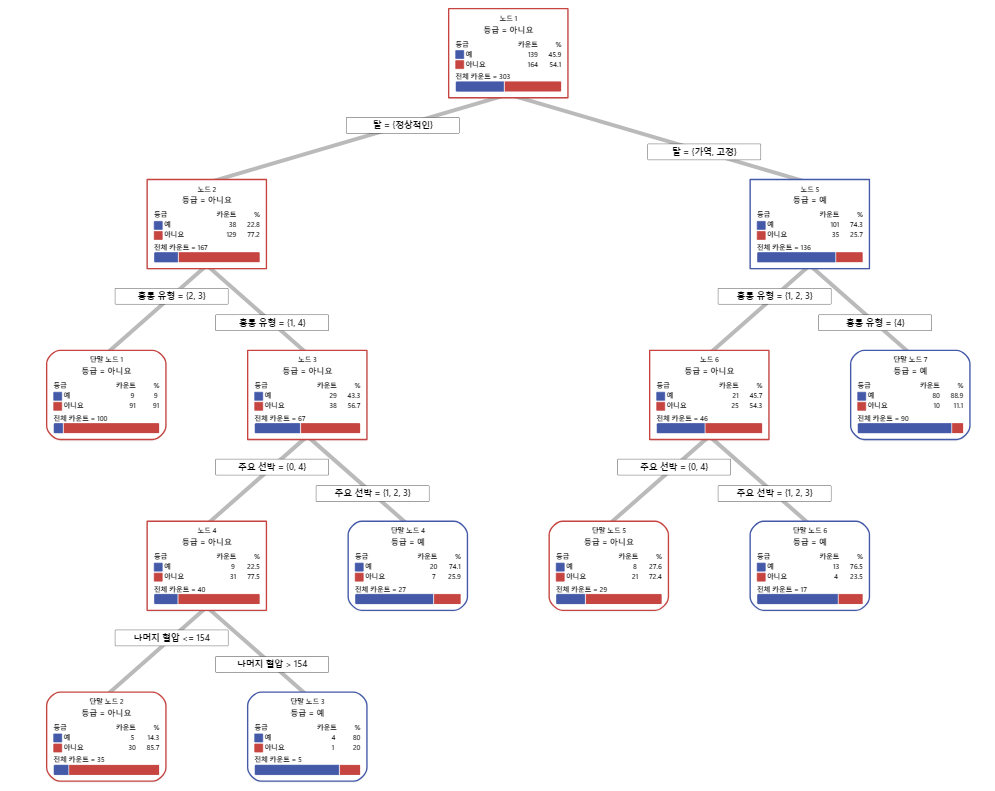
주요 결과: 수형도
이 분류 트리에는 7개의 터미널 노드가 있습니다. 사건 수준(예)은 파란색이고 비사건 수준(아니요)은 빨간색입입니다. 수형도는 학습 데이터 세트를 사용합니다. 트리 보기를 상세 보기와 노드 분할 보기 간에 전환할 수 있습니다.
- 노드 2: THAL은 167건에 대해 정상이었습니다. 167건 중 38건인 22.8%가 '예', 129건인 77.2%가 '아니요'입니다.
- 노드 5: THAL은 136건에 대해 고정 또는 되돌릴 수 있었습니다. 136건 중 101건인 74.3%가 '예', 35건인 25.7%가 '아니요'입니다.
왼쪽 자식 노드와 오른쪽 자식 노드 모두에 대한 다음 분할은 통증이 1, 2, 3 또는 4로 평가되는 흉통 유형입니다. 노드 2는 터미널 노드 1의 부모 노드이고 노드 5는 터미널 노드 7의 부모 노드입니다.
- 터미널 노드 1: 100건의 경우 THAL는 정상이고, 흉통은 2 또는 3이었습니다. 100건 중 9건인 9%가 '예', 91건인 91%가 '아니요'입니다.
- 터미널 노드 7: 90건의 경우, THAL은 고정 또는 되돌릴 수 있음이고, 흉통은 4였습니다. 90건 중 80건인 88.9%가 '예', 10건인 11.1%가 '아니요'입니다.
3단계: 중요한 변수 결정
상대 변수 중요도 차트를 사용하여 트리에 가장 중요한 변수인 예측 변수를 결정합니다.
중요한 변수는 트리의 기본 또는 대리 분할입니다. 개선 점수가 가장 높은 변수가 가장 중요한 변수로 설정되고 다른 변수의 순위가 적절하게 매겨집니다. 상대 변수 중요도는 해석의 용이성을 위해 중요도 값을 표준화합니다. 상대적 중요도는 가장 중요한 예측 변수에 대한 백분율 개선으로 정의됩니다.
상대 변수 중요도 값의 범위는 0%에서 100%입니다. 가장 중요한 변수는 항상 100%의 상대적 중요도를 가집니다. 변수가 트리에 없는 경우 해당 변수는 중요하지 않습니다.
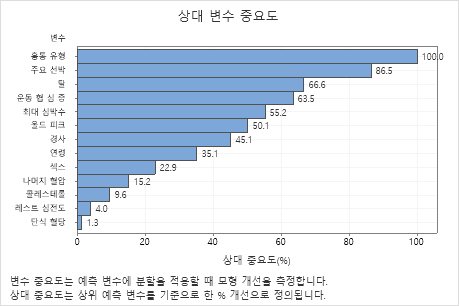
주요 결과: 상대 변수 중요도
- 주요 선박 약 87 %가 흉통 유형중요합니다.
- 탈 둘 운동 협 심 증 다 약 65 % 중요합니다 흉통 유형.
- 최대 심박수 약 55%가 흉통 유형중요합니다.
- 올드 피크 약 50%가 흉통 유형중요합니다.
- 경사, 연령, 섹스, 및 나머지 혈압 는 보다 훨씬 덜 중요합니다 흉통 유형.
콜레스테롤, 레스트 심전도, 단식 혈당는 긍정적인 중요도를 가지고 있지만, 분석가들은 이들이 트리에 크게 기여하지 않는다고 결정할 수도 있습니다.
4단계: 트리의 예측 능력 평가
가장 정확한 트리는 오분류 비용이 가장 낮은 트리입니다. 때로는 오분류 비용이 약간 더 높은 간단한 트리도 작동합니다. 오분류 비용 대 터미널 노드 플롯을 사용하여 대체 트리를 식별할 수 있습니다.
수신자 검사 특성(ROC) 곡선은 트리가 데이터를 얼마나 잘 분류하는지 보여줍니다. ROC 곡선은 y축의 진양성률과 x축의 가양성률을 플로팅합니다. 진양성률을 검정력이라고도 합니다. 가양성률을 유형 I 오차라고도 합니다.
분류 트리가 반응 변수에서 범주를 완벽하게 구분할 수 있는 경우 ROC 곡선 아래의 면적은 1이며, 이는 최상의 분류 모형입니다. 또는 분류 트리가 범주를 구분할 수 없고 할당을 완전히 임의로 만드는 경우 ROC 곡선 아래의 면적은 0.5입니다.
검증 기술을 사용하여 트리를 빌드하는 경우 Minitab은 학습 및 검증(검정) 데이터에 대한 트리의 성능 정보를 제공합니다. 곡선이 서로 가까이 있으면 트리가 과도 적합이 아니라고 확신할 수 있습니다. 검정 데이터가 있는 트리의 성능은 트리가 새 데이터를 얼마나 잘 예측할 수 있는지를 나타냅니다.
- 진양성률(TPR) - 사건 사례가 올바르게 예측될 확률
- 가양성률(FPR) - 비사건 사례가 잘못 예측될 확률
- 가음성률(FNR) - 사건 사례가 잘못 예측될 확률
- 진음성률(TNR) - 비사건 사례가 올바르게 예측될 확률
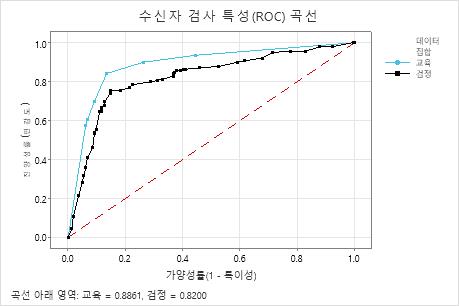
주요 결과: 수신자 검사 특성(ROC) 곡선
이 예제에서는 ROC 곡선 아래의 면적은 학습의 경우 0.886이고 검정의 경우 0.82입니다. 이러한 값은 대부분의 용도에서 분류 트리가 적절한 분류자임을 나타냅니다.
오차 행렬
| 예측된 등급(교육) | 예측된 등급(검정) | ||||||
|---|---|---|---|---|---|---|---|
| 실제 등급 | 카운트 | 예 | 아니요 | 정답률(%) | 예 | 아니요 | 정답률(%) |
| 예 (사건) | 139 | 117 | 22 | 84.2 | 105 | 34 | 75.5 |
| 아니요 | 164 | 22 | 142 | 86.6 | 24 | 140 | 85.4 |
| 모두 | 303 | 139 | 164 | 85.5 | 129 | 174 | 80.9 |
| 통계량 | 교육(%) | 검정(%) |
|---|---|---|
| 진양성률(민감도 또는 검정력) | 84.2 | 75.5 |
| 가양성률(유형 I 오차) | 13.4 | 14.6 |
| 가음성률(유형 II 오차) | 15.8 | 24.5 |
| 진음성률(특이성) | 86.6 | 85.4 |
주요 결과: 오차 행렬
- 진양성률(TPR) - 학습 데이터의 경우 84.2%, 검정 데이터의 경우 75.5%입니다.
- 가양성률(FPR) - 학습 데이터의 경우 13.4%, 검정 데이터의 경우 14.6%입니다.
- 가음성률(FPR) - 학습 데이터의 경우 15.8%, 검정 데이터의 경우 24.5%입니다
- 진음성률(FPR) - 학습 데이터의 경우 86.6%, 검정 데이터의 경우 85.4%입니다
전반적으로 정확도 %는 학습 데이터의 경우 85.5%이고, 검정 데이터의 경우 80.9%입니다.