사후 확률은 데이터가 주어진 상태에서 그룹에 관측치를 할당할 확률입니다. 사전 확률은 데이터를 수집하기 전에 관측치가 한 그룹에 포함될 확률입니다. 예를 들어, 특정 자동차의 구매자를 분류하는 경우 구매자의 60%가 남성이고 40%가 여성이라는 사실을 이미 알고 있을 수 있습니다. 사전 확률을 알고 있거나 추정할 수 있는 경우 판별 분석에서는 사전 확률을 사용하여 사후 확률을 계산할 수 있습니다. 사전 확률을 지정하지 않는 경우 Minitab에서는 모든 그룹이 동일하다고 가정합니다.
데이터가 정규 분포를 따른다고 가정할 경우 선형 판별 함수는 ln(pi)만큼 증가합니다(여기서 pi는 그룹 i의 사전 확률). 최소 일반화 거리(또는 최대 선형 판별 함수)에 따라 그룹에 관측치를 포함하므로 사전 확률이 높은 그룹의 사후 확률이 높아지게 됩니다.
참고
사전 확률을 지정하면 결과의 정확성에 큰 영향을 미칠 수 있습니다. 그룹들의 비율이 같지 않은 것이 모집단의 실제 차이를 나타내는지, 아니면 표집 오차 때문인지 조사해야 합니다.
사전 확률이 있고 fi(x)가 그룹 i에 있는 데이터의 결합 밀도라고 가정합니다(모집단 모수는 표본 추정치로 바뀜).
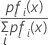
사후 확률이 가장 크면 ln [pifi(x)] 값도 가장 큽니다.
fi(x)가 정규 분포일 경우 이 값은 다음과 같이 계산됩니다.
ln [pifi(x)] = -0.5 [di2(x) – 2 ln pi] – (상수)
대괄호 안의 항은 x부터 그룹 i까지의 일반화 거리 제곱이라고 하며 di2(x)로 표시합니다. 이 값은 다음과 같이 계산됩니다.
di2(x) = -2[mi' Sp-1 x - 0.5 mi' Sp-1mi + ln pi] + x' Sp-1x
대괄호 안의 항은 선형 판별 함수입니다. 사전 확률이 없는 경우와의 유일한 차이점은 상수 항의 변화입니다. 사후 확률이 가장 크면 일반화 거리는 가장 작고 선형 판별 함수는 가장 크게 됩니다.